Download as PDF, PPTX














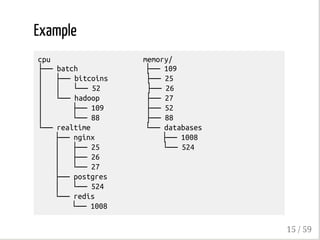













































The document outlines the anatomy and implementation of containers in computing, detailing components like namespaces, control groups (cgroups), and copy-on-write storage. It discusses the differences between containers and virtual machines, with insights into how containers manage resources and isolate processes. Furthermore, it explores various container runtimes such as Docker, LXC, and rkt, along with other related technologies.





























































































