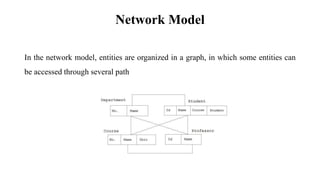
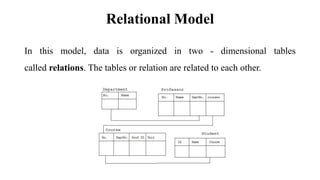
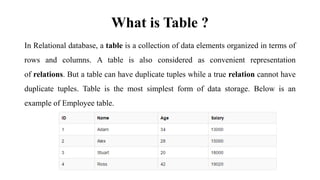
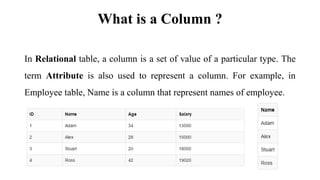
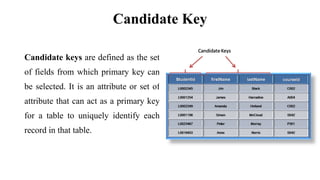
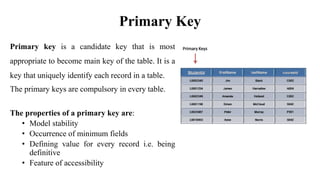
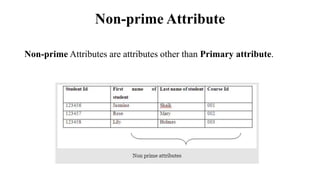
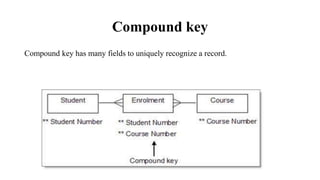
This document discusses database management system (DBMS) architecture and relational database management systems (RDBMS). It describes one-tier, two-tier, and three-tier architectures for DBMS. It also discusses database models including hierarchical, network, and relational models. Additionally, it covers RDBMS concepts such as tables, records, fields, columns, keys including primary keys and foreign keys. It provides examples to illustrate these concepts.