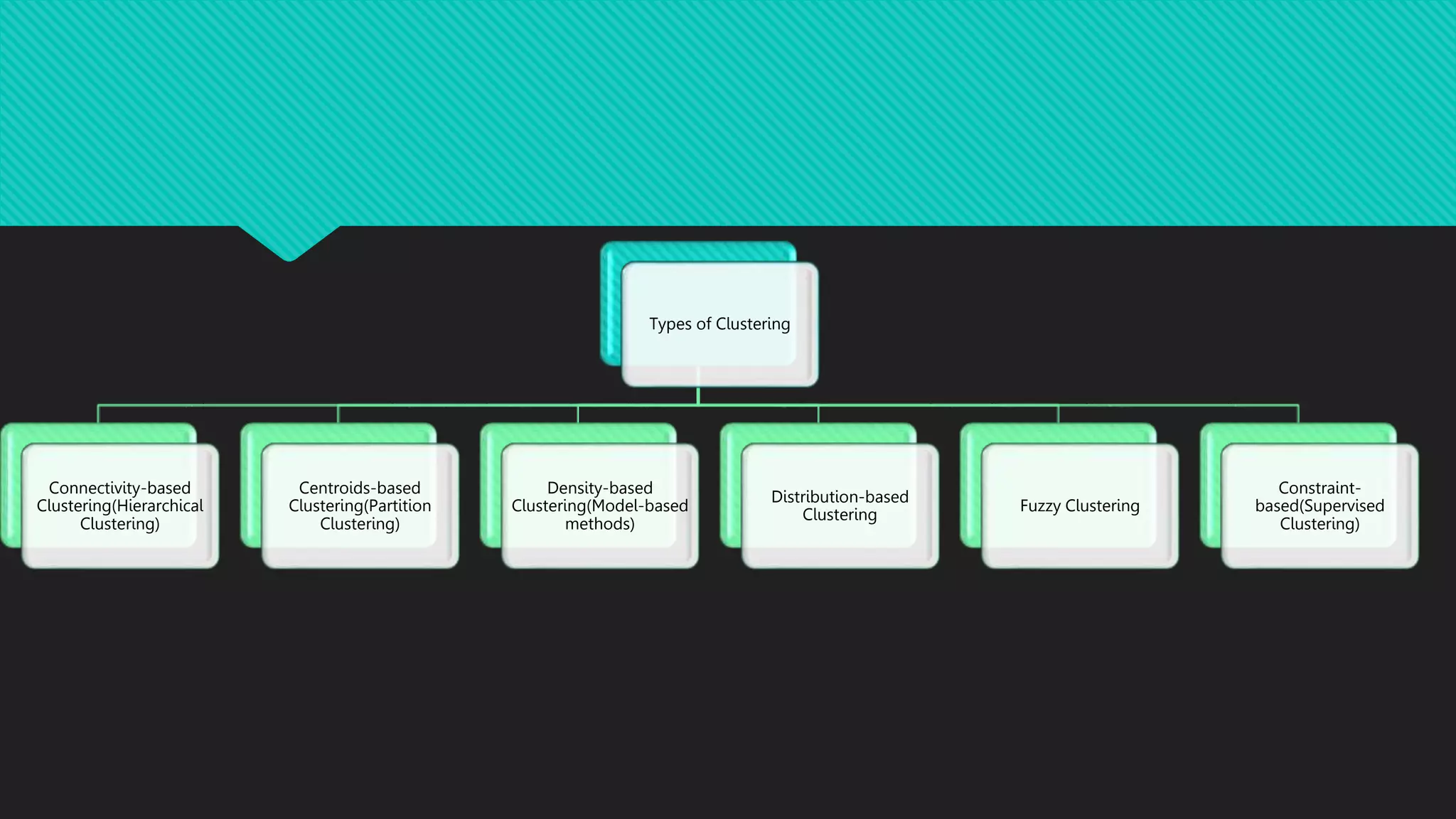
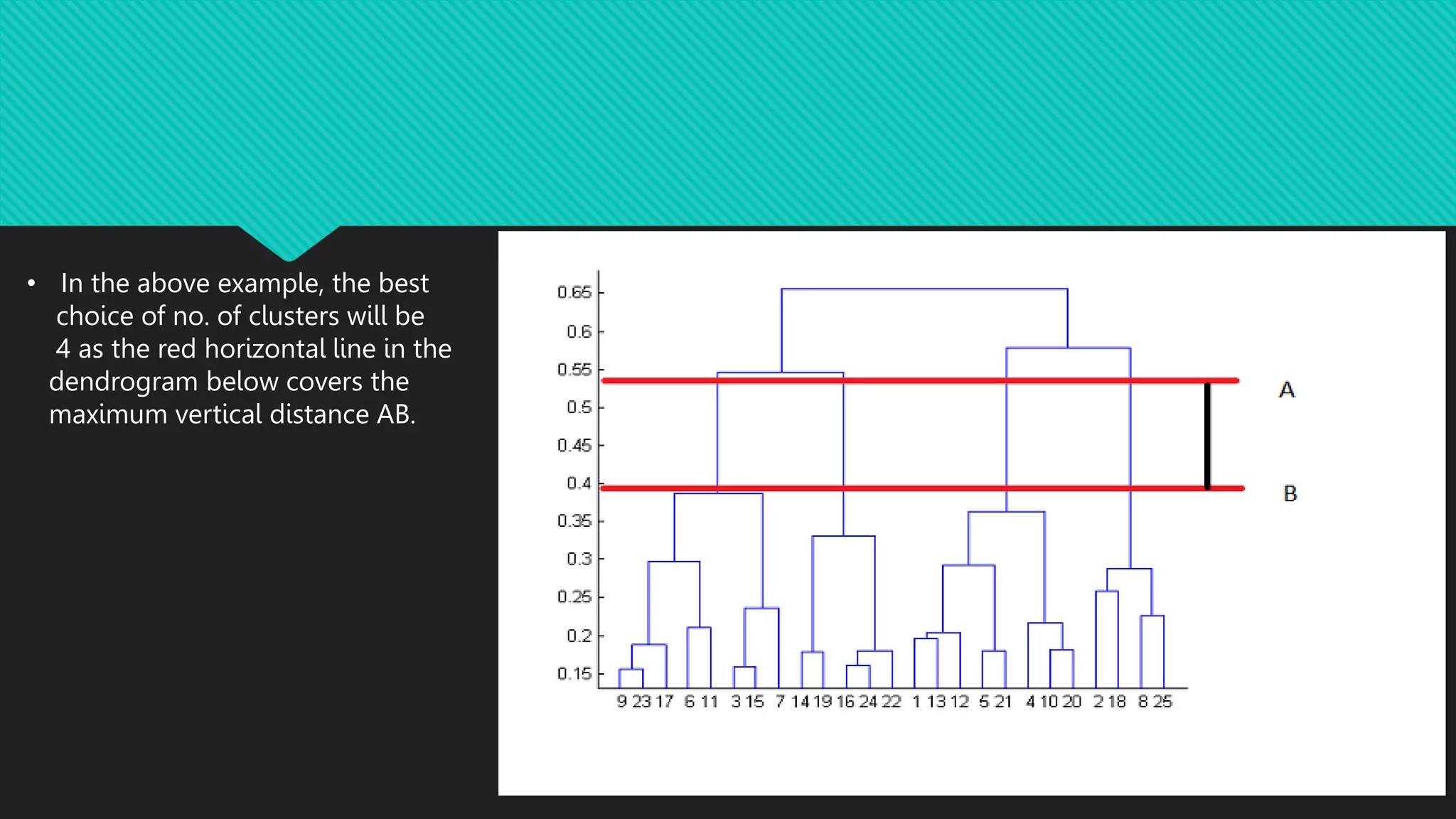
This document discusses different types of clustering methods used to group unlabeled data points. It describes hierarchical clustering, which builds clusters recursively by merging the two closest clusters. Hierarchical clustering results can be shown in a dendrogram that depicts the merge distances. The document also lists applications of clustering such as pattern recognition, market research, and bioinformatics.