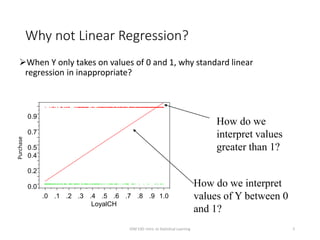
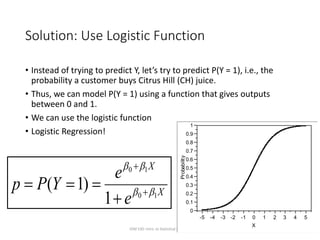
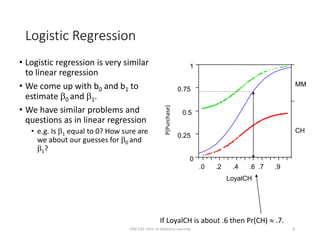
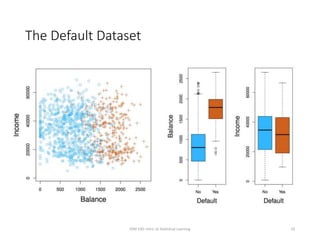
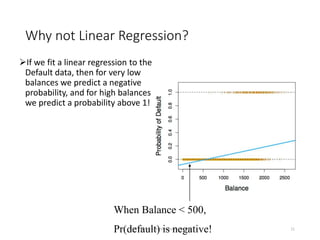
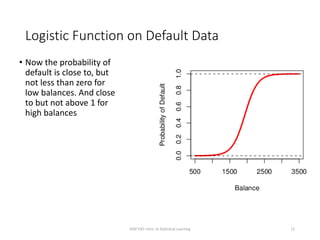
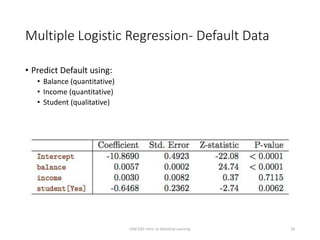
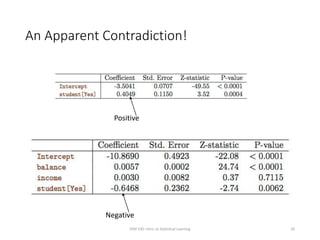
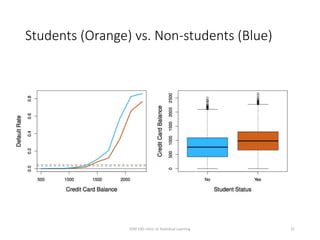
This document provides an overview of logistic regression for classification problems. It introduces logistic regression using two examples: predicting orange juice brand preference and credit card default. Linear regression is inappropriate for classification with binary outcomes. Logistic regression models the probability of an outcome using a logistic function to constrain predictions between 0 and 1. The document explains how to interpret logistic regression coefficients and make predictions, and how to extend the approach to multiple predictors.