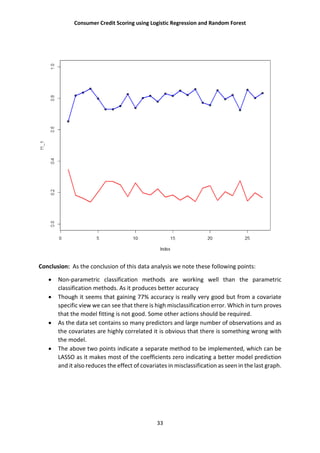
The document discusses using logistic regression and random forest models for consumer credit scoring. It begins by introducing credit scoring and explaining that the goal is to classify applicants as "good" or "bad" credit risks. It then outlines the typical steps taken in developing a credit scoring model, including understanding the problem, defining variables, exploratory data analysis, and splitting data into training and test sets. The document focuses on logistic regression, explaining the logistic regression model and how it is fitted. It also briefly introduces random forest methods and LASSO regularization.










![Consumer Credit Scoring using Logistic Regression and Random Forest
11
the parameters. The approach that will be followed here is called maximum likelihood. This
method yields values for the unknown parameters that maximize the probability of obtaining
the observed set of data. To apply this method, a likelihood function must be constructed.
This function expressed the probability of the observed data as a function of the unknown
parameters. The maximum likelihood estimators of these parameters are chosen that this
function is maximized, hence the resulting estimators will agree most closely with the
observed data.
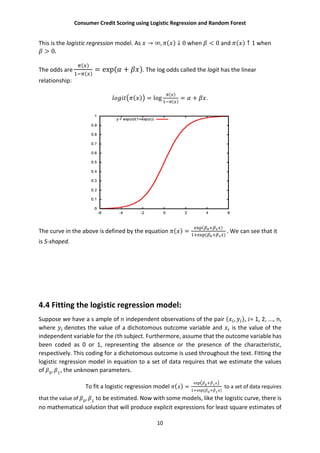
Now if is coded as 0 or 1, the expression for ( ) =
( )
( )
provides
conditional probability that = 1 given . This is denoted as ( ). It follow that 1 − ( ) gives the
conditional probability that = 1 given . Now this can be expressed for the observation ( , ) as:
( ) [1 − ( )]
The assumption is that the observations are independent, thus the likelihood function is
obtained as a product of the terms given by the above expression.
(β) = ∏( ( ) [1 − ( )] )
Where is the vector of unknown parameters.
Now has to be estimated so that (β) is maximized. The log likelihood
function is defined as:
( ) = { ln[ ( )] + (1 − ) ln[1 − ( )]}.
In linear regression, the normal equations obtained by minimizing the SSE, was linear in the
unknown parameters that are easily solved. In logistic regression, minimizing the log
likelihood yields equations that are nonlinear in the unknowns, so numerical methods are
used to obtain their solutions.
Deviance: Compare the observed values of the response variable to predicted values
obtained from models with and without the variable in question. In logistic regression,
comparison of observed to predicted values is based on the log likelihood function.
To better understand this comparison, it is helpful conceptually to think of an
observed value of the response variable as also being a predicted value resulting from a
saturated model. A saturated model is one that contains as many parameters as there are
data points.
The comparison of the observed to predicted values using the likelihood
function is based on the following expression:
= −2 ln
ℎ ( )
ℎ ( )
Substituting the likelihood function gives us the deviance statistic:
= −2 ∑ ln + (1 − ) ln .](https://image.slidesharecdn.com/project-160906140246/85/Consumer-Credit-Scoring-Using-Logistic-Regression-and-Random-Forest-11-320.jpg)
![Consumer Credit Scoring using Logistic Regression and Random Forest
12
Likelihood Ratio Test: The likelihood-ratio test uses the ratio of the maximized value of the
likelihood function for the full model ( ) over the maximized value of the likelihood function
for the simpler model ( ). The full model has all the parameters of interest in it. The
likelihood ratio test statistic equals:
−2 ln = −2[ln − ln ]
The likelihood-ratio test tests if the logistic regression coefficient for the dropped
variable can be treated as zero, thereby justifying the dropping of the variable from the
model.
Wald Test: The Wald test is used to test the statistical significance of each coefficient ( ) in
the model. A Wald test calculates a statistic which is:
=
This value is squared which yields a chi-square distribution and is used as the Wald
test statistic. (Alternatively the value can be directly compared to a normal distribution.)
Score Test: A test for significance of a variable, which does not require the computation of
the maximum likelihood estimates for the coefficients, is the Score test. The Score test is
based on the distribution of the derivatives of the log likelihood.
Let be the likelihood function which depends on a univariate parameter and let
be the data. The score is ( ) where
( ) =
ln ( | )
The observed Fisher information is
( ) =
ln ( | )
The statistic to test : = is: ( ) =
( )
( )
Which take (1) distribution asymptotically when is true.
4.5 Goodness of fit in Logistic regression
As in linear regression, goodness of fit in logistic regression attempts to get at how well a
model fits the data. It is usually applied after a “final model” has been selected. As we have
seen, often in selecting a model no single “final model” is selected, as a series of models are
fit, each contributing towards final inferences and conclusions. In that case, one may wish to
see how well more than one model fits, although it is common to just check the fit of one](https://image.slidesharecdn.com/project-160906140246/85/Consumer-Credit-Scoring-Using-Logistic-Regression-and-Random-Forest-12-320.jpg)



![Consumer Credit Scoring using Logistic Regression and Random Forest
17
bootstrap samples from the original data set, constructs a predictor from each sample, and
decides by averaging. It is one of the most effective computationally intensive procedures to
improve on unstable estimates, especially for large, high-dimensional data sets, where finding
a good model in one step is impossible because of the complexity and scale of the problem
(Bühlmann and Yu 2002; Kleiner et al. 2014; Wager et al. 2014) However, while bagging and
the CART-splitting scheme play key roles in the random forest mechanism, both are difficult
to analyse with rigorous mathematics, thereby explaining why theoretical studies have so far
considered simplified versions of the original procedure. This is often done by simply ignoring
the bagging step and/or replacing the CART-split selection by a more elementary cut protocol.
As well as this, in Breiman’s (2001) forests, each leaf (that is, a terminal node) of individual
trees contains a small number of observations, typically between 1 and 5.
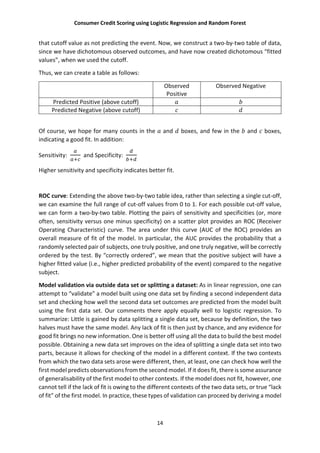
5.3 Definition of random forests:
A random forest is a classifier consisting a collection of tree-structured classifiers
{ℎ( , Θ ), = 1, … … … } where {Θ } are independent and identically distributed
random vectors and each tree casts a unit vote for the most popular class at input .
5.4 Basic principles:
Let us start with a word of caution. The term “random forests” is a bit ambiguous. For some
authors, it is but a generic expression for aggregating random decision trees, no matter how
the trees are obtained. For others, it refers to Breiman’s (2001) original algorithm. We
essentially adopt the second point of view in the present survey.
Our objective in this section is to provide a concise but mathematically precise
presentation of the algorithm for building a random forest. The general framework is
nonparametric regression estimation, in which an input random vector ∈ ⊂ ℝ is
observed, and the goal is to predict the square integrable random response ∈ ℝ by
estimating the regression
function ( ) = [ | = ]. With this aim in mind we assume that we have training sample
= ( , ), … … … . , ( , ) of independent random variables distributed as the
independent prototype pair ( , ).The goal is to use the dataset to construct an estimate
: → ℝ of the function . In this respect we say that regression function estimate is
(mean squared error) is consistent if [ ( ) − ( )] → 0 as → ∞(the expectation is
evaluated over and the sample .
A random forest is a predictor consisting of a collection of randomized
regression trees. For the tree is the family, the predicted value at the query point is
denoted by ; Θ , , where Θ , … … … . . , Θ are independent random variables
distributed same as the generic random variable Θ and independent of . In practice, the
variable Θ is used to resample the training set prior to the growing of individual trees and to
select the successive directions for splitting. In mathematical terms the tree estimate takes
the form:](https://image.slidesharecdn.com/project-160906140246/85/Consumer-Credit-Scoring-Using-Logistic-Regression-and-Random-Forest-17-320.jpg)


![Consumer Credit Scoring using Logistic Regression and Random Forest
21
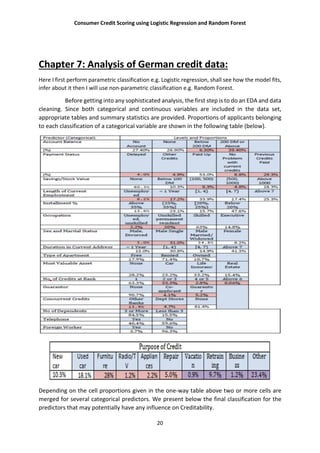
Account Balance: No account (1), None (No balance) (2), Some Balance (3)
Payment Status: Some Problems (1), Paid Up (2), No Problems (in this bank) (3)
Savings/
Stock Value: None, Below 100 DM, [100, 1000] DM, Above 1000 DM
Employment Length: Below 1 year (including unemployed), [1, 4), [4, 7), Above 7
Sex/Marital Status: Male Divorced/Single, Male Married/Widowed, Female
No of Credits at this bank: 1, More than 1
Guarantor: None, Yes
Concurrent Credits: Other Banks or Dept. Stores, None
Foreign Worker variable may be dropped from the study
Purpose of Credit: New car, Used car, Home Related, Other
Cross-tabulation of the some of the 9 predictors as defined above with Creditability is shown
below. The proportions shown in the cells are column proportions and so are the marginal
proportions. For example, 30% of 1000 applicants have no account and another 30% have no
balance while 40% have some balance in their account. Among those who have no account
135 are found to be Creditable and 139 are found to be Non-Creditable. In the group with no
balance in their account, 40% were found to be on-Creditable whereas in the group having
some balance only 1% are found to be Non-Creditable.
| Acc.Balance
Creditability | 1 | 2 | 3 | Row Total |
--------------|-----------|-----------|-----------|-----------|
0 | 240 | 14 | 46 | 300 |
| 0.4 | 0.2 | 0.1 | |
--------------|-----------|-----------|-----------|-----------|
1 | 303 | 49 | 348 | 700 |
| 0.6 | 0.8 | 0.9 | |
--------------|-----------|-----------|-----------|-----------|
Column Total | 543 | 63 | 394 | 1000 |
| 0.5 | 0.1 | 0.4 | |
--------------|-----------|-----------|-----------|-----------|
| Payment. Status
Creditability | 1 | 2 | 3 | Row Total |
--------------|-----------|-----------|-----------|-----------|
0 | 53 | 169 | 78 | 300 |
| 0.6 | 0.3 | 0.2 | |
--------------|-----------|-----------|-----------|-----------|
1 | 36 | 361 | 303 | 700 |
| 0.4 | 0.7 | 0.8 | |
--------------|-----------|-----------|-----------|-----------|
Column Total | 89 | 530 | 381 | 1000 |
| 0.1 | 0.5 | 0.4 | |
--------------|-----------|-----------|-----------|-----------|
| Savings
Creditability | 1 | 2 | 3 | Row Total |
--------------|-----------|-----------|-----------|-----------|
0 | 217 | 34 | 49 | 300 |
| 0.4 | 0.3 | 0.2 | |
--------------|-----------|-----------|-----------|-----------|
1 | 386 | 69 | 245 | 700 |](https://image.slidesharecdn.com/project-160906140246/85/Consumer-Credit-Scoring-Using-Logistic-Regression-and-Random-Forest-21-320.jpg)

![Consumer Credit Scoring using Logistic Regression and Random Forest
26
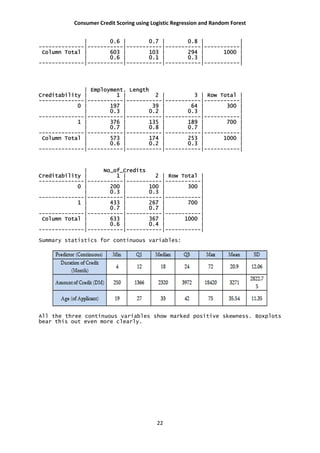
Resampling: Cross-Validated (10 fold, repeated 10 times)
Summary of sample sizes: 900, 900, 900, 900, 900, 900, ...
Resampling results:
Accuracy Kappa
0.7478 0.3642265
Now let’s see if there is any improvement in accuracy via confusion matrix.
Confusion Matrix and Statistics
Reference
Prediction 0 1
0 74 37
1 76 313
Accuracy : 0.774
95% CI : (0.7348, 0.8099)
No Information Rate : 0.7
P-Value [Acc > NIR] : 0.0001305
Kappa : 0.4187
Mcnemar's Test P-Value : 0.0003506
Sensitivity : 0.4933
Specificity : 0.8943
Pos Pred Value : 0.6667
Neg Pred Value : 0.8046
Prevalence : 0.3000
Detection Rate : 0.1480
Detection Prevalence : 0.2220
Balanced Accuracy : 0.6938
'Positive' Class : 0
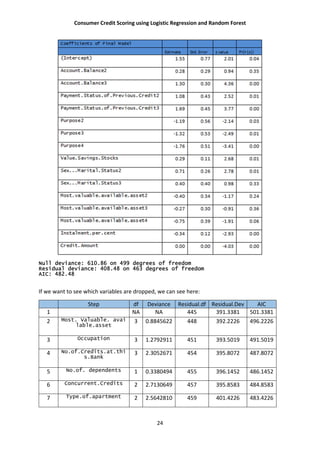
Here we can see in comparison to previous classification table we have a slight improvement
in accuracy, here we have 77.4% accuracy in predicting the true values of .
Now the question remains, is this model is a good fit? What are the effects of covariates
in misclassification? How does it affect the model? I discuss these later. First let’s see how the
nonparametric classifier e.g. Random forest performs.
Random forests are very good in that it is an ensemble learning method used for classification
and regression. It uses multiple models for better performance that just using a single tree
model. In addition, because many sample are selected in the process a measure of variable
importance can be obtain and this approach can be used for model selection and can be
particularly useful when forward/backward stepwise selection is not appropriate and when
working with an extremely high number of candidate variables that need to be reduced.
Here I do an unsupervised random forest method. Which leads to the following
results:
Call:
randomForest(formula = as.factor(Creditability) ~ ., data = Train50,
ntree = 400, importance = TRUE, proximity = TRUE)
Type of random forest: classification
Number of trees: 400
No. of variables tried at each split: 4
OOB estimate of error rate: 24%
Confusion matrix:
0 1 class.error](https://image.slidesharecdn.com/project-160906140246/85/Consumer-Credit-Scoring-Using-Logistic-Regression-and-Random-Forest-26-320.jpg)

![Consumer Credit Scoring using Logistic Regression and Random Forest
28
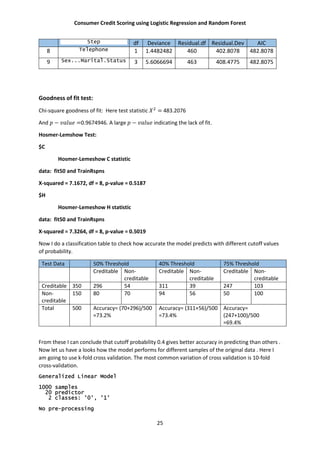
Now I will show that how random forest perform in predicting the credit scores. Measure of
accuracy will be given via confusion matrix.
Confusion Matrix and Statistics
Reference
Prediction 0 1
0 88 53
1 62 297
Accuracy : 0.771
95% CI : (0.704, 0.8022)
No Information Rate : 0.7
P-Value [Acc > NIR] : 0.05246
Kappa : 0.2772
Mcnemar's Test P-Value : 2.865e-08
Sensitivity : 0.3400
Specificity : 0.9029
Pos Pred Value : 0.6240
Neg Pred Value : 0.8248
Prevalence : 0.3000
Detection Rate : 0.1020
Detection Prevalence : 0.1700
Balanced Accuracy : 0.6924
'Positive' Class : 0](https://image.slidesharecdn.com/project-160906140246/85/Consumer-Credit-Scoring-Using-Logistic-Regression-and-Random-Forest-28-320.jpg)
![Consumer Credit Scoring using Logistic Regression and Random Forest
29
So form above we have found that the accuracy in prediction is 77.1%. Which is quite an
improvement from the logistic regression procedure we performed before.
Ultimately these statistical decisions must be translated into profit consideration
for the bank. Let us assume that a correct decision of the bank would result in 35% profit at
the end of 5 years. A correct decision here means that the bank predicts an application to be
good or credit-worthy and it actually turns out to be credit worthy. When the opposite is
true, i.e. bank predicts the application to be good but it turns out to be bad credit, then the
loss is 100%. If the bank predicts an application to be non-creditworthy, then loan facility is
not extended to that applicant and bank does not incur any loss (opportunity loss is not
considered here). The cost matrix, therefore, is as follows:
Predicted
Actual Creditworthy Creditworthy Non-Creditworthy
+0.35 0
Non-creditworthy -1.00 0
Out of 1000 applicants, 70% are creditworthy. A loan manager without any model would incur
[0.7*0.35 + 0.3 (-1)] = - 0.055 or 0.055 unit loss. If the average loan amount is 3200 DM
(approximately), then the total loss will be 1760000 DM and per applicant loss is 176 DM.
Actual Prediction by logistic regression Prediction by random forest
50%
threshold
40%
threshold
75%
threshold
Creditable Creditable Creditable Creditable
Creditable 0.592 0.622 0.494 0.594
Non-
creditable
0.16 0.188 0.1 0.124
Per
applicant
profit
0.0472 0.0297 0.0729 0.0839
Random forest shows a good per unit profit.](https://image.slidesharecdn.com/project-160906140246/85/Consumer-Credit-Scoring-Using-Logistic-Regression-and-Random-Forest-29-320.jpg)


![Consumer Credit Scoring using Logistic Regression and Random Forest
35
CrossTable(Creditability,Payment.status, digits=1,prop.r=F, prop.t=F, prop.chisq=F, chisq=F)
CrossTable(Creditability,Savings,digits=1,prop.r=F,prop.t=F, prop.chisq=F, chisq=F)
CrossTable(Creditability,Employment.length,digits=1,prop.r=F, prop.t=F, prop.chisq=F, chisq=F)
CrossTable(Creditability,Sex_marital_status,digits=1,prop.r=F, prop.t=F, prop.chisq=F, chisq=F)
CrossTable(Creditability,No_of_Credits,digits=1,prop.r=F, prop.t=F, prop.chisq=F, chisq=F)
CrossTable(Creditability,Guarantor,digits=1,prop.r=F, prop.t=F, prop.chisq=F, chisq=F)
CrossTable(Creditability,Concurrent_credit,digits=1,prop.r=F, prop.t=F, prop.chisq=F, chisq=F)
CrossTable(Creditability,Purpose_of_credit,digits=1,prop.r=F,prop.t=F, prop.chisq=F, chisq=F)
CrossTable(Creditability,Type.of.apartment,digits=1,prop.r=F,prop.t=F, prop.chisq=F, chisq=F)
CrossTable(Creditability,No.of.dependents,digits=1,prop.r=F,prop.t=F, prop.chisq=F, chisq=F)
CrossTable(Creditability,Instalment.per.cent,digits=1,prop.r=F,prop.t=F, prop.chisq=F, chisq=F)
#Summary statistics for continuous variables
summary(Duration.of.Credit..month.);sd(Duration.of.Credit..month.)
summary(Credit.Amount);sd(Credit.Amount)
summary(Age..years.);sd(Age..years.)
#boxplot for cont. variables
par(mfrow=c(2,2))
boxplot(Duration.of.Credit..month., bty="n",xlab = "Credit Month", cex=0.4) # For boxplot
boxplot(Credit.Amount, bty="n",xlab = "Amount", cex=0.4)
boxplot(Age..years., bty="n",xlab = "Age", cex=0.4)
# Logistic model
for (i in c(2,4:5,7:13,15:20)){
DATA[,i] <- as.factor(DATA[,i])
}
nrow(DATA)
set.seed(50) # setting the random number seed for splitting the dataset
indexes = sample(1:nrow(DATA), size=0.5*nrow(DATA)) # Random sample of 50% of row numbers
created
Train50 <- DATA[indexes,]
Test50 <- DATA[-indexes,]
indVariables <- colnames(DATA[,2:21]);indVariables](https://image.slidesharecdn.com/project-160906140246/85/Consumer-Credit-Scoring-Using-Logistic-Regression-and-Random-Forest-35-320.jpg)
![Consumer Credit Scoring using Logistic Regression and Random Forest
36
# getting the independent variables, the last column is the dependent variable
rhsOfModel <- paste(indVariables,collapse="+")
# creating the right hand side of the model expression
rhsOfModel
model <- paste("Creditability ~ ",rhsOfModel)
# creating the text model
model
frml <- as.formula(model) # converting the above text into a formula
frml
library(MASS) # loading the library MASS for stepwise regression
TrainModel <- glm(formula=frml,family="binomial",data=Train50)
# building the model on training data with LOGIT link (family = binomial
finalModel <- step(object=TrainModel)
summary(finalModel)# stepwise regression
finalModel$coefficients[1:21]
sum(residuals(finalModel,type="pearson")^2)
deviance(finalModel)
1-pchisq(deviance(finalModel),df.residual(finalModel))
summary(object=finalModel)
finalModel$anova
finalModel$fitted.values
fit50 <- fitted.values(finalModel)
fit50
library(MKmisc) # loading the library MKmisc for Hosmer Lemeshow Goodness of fit
HLgof.test(fit=fit50,obs=TrainRspns)
library(pROC) # loading library pROC for ROC curve
TestPred <- predict(object=finalModel,newdata=Test50, type="response")
# predicting the testing data
TestPredRspns <- ifelse(test= TestPred < 0.75, yes= 0, no= 1)
#Random Forest
library(randomForest)](https://image.slidesharecdn.com/project-160906140246/85/Consumer-Credit-Scoring-Using-Logistic-Regression-and-Random-Forest-36-320.jpg)
![Consumer Credit Scoring using Logistic Regression and Random Forest
37
rf50<-randomForest(as.factor(Creditability)~.,data=Train50,
ntree=400,importance=TRUE,proximity=TRUE)
rf50<-randomForest(as.factor(Creditability)~.,data=Train50,
ntree=400,importance=TRUE,proximity=TRUE,control=ctrl)
print(rf50)
summary(rf50)
plot.new()
plot(proximity(rf50))
plot(rf50, main="Error rate", lwd=2,lty=7,fg="blue",)
plot( importance(rf50), lty=2, pch=16,col="red")
lines(importance(rf50),col="blue",lty=6,lwd=2)
Test50_rf_pred <- predict(rf50,Test50,type="class")
confusionMatrix(Test50_rf_pred, Test50$Creditability)
#limitations
DT<-
data.frame(Creditability,as.numeric(Duration.in.Current.address),as.numeric(Age..years.),as.numeric
(Guarantors),as.numeric(Savings),as.numeric(Length.of.current.employment),as.numeric(Duration.o
f.Credit..month.),as.numeric(Credit.Amount),as.numeric(Purpose),as.numeric(Instalment.per.cent),a
s.numeric(Payment.status),as.numeric(Foreign.Worker),as.numeric(Acc.Balance))
pc_DT<-prcomp(DT[,2:13])
summary(prcomp(DT[,2:13]))
library(GGally)
ggpairs(DT[,2:13],)
for(i in 1:3){
for( j in 1:3){
for(k in 1:3){
(Acc.Balance=i & Payment.status=j & Savings=k)}}}
plot(f1,lwd=3)
lines(f2,col="red",lwd=2)
plot(f2,add=TRUE)
lines(f1,col="blue",lwd=2)
plot.new()
plot(f1_1,lwd=5)](https://image.slidesharecdn.com/project-160906140246/85/Consumer-Credit-Scoring-Using-Logistic-Regression-and-Random-Forest-37-320.jpg)
![Consumer Credit Scoring using Logistic Regression and Random Forest
38
lines(f2_1,col="red",lwd=2)
lines(f1_1,col="blue",lwd=2)
#lasso
x <- as.matrix(Train50_DT[, 2:13])
y <- as.matrix(Train50_DT[, 1])
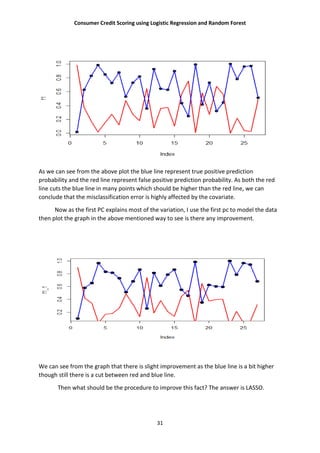
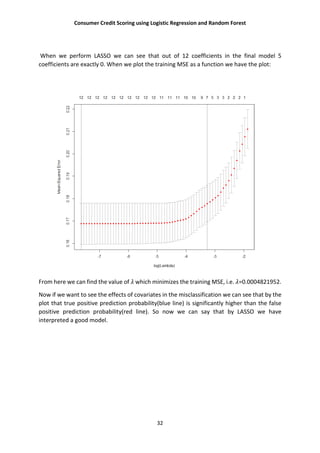
cv <- cv.glmnet(x, y,nfolds = 100)
plot(cv)
mdl <- glmnet(x, y,lambda = cv$lambda.1se)
mdl$beta
plot.glmnet(mdl)
bestlam=cv$lambda.min
plot(f1_1,ylim=c(0.0,1),lwd=2)
lines(f1_1,col="blue",lwd=2)
lines(f2_1,col="red",lwd=2)
Appendix:2
Data set link: http://www.statistik.lmu.de/service/datenarchiv/kredit/kredit_e.html
For the description of variables and more information please go to this link .](https://image.slidesharecdn.com/project-160906140246/85/Consumer-Credit-Scoring-Using-Logistic-Regression-and-Random-Forest-38-320.jpg)

























































































