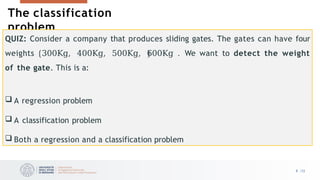
The document outlines a lesson on logistic regression, focusing on its use for classification problems where response variables are categorical rather than continuous. It explains why linear regression is inadequate for such cases and details the formulation of logistic regression, including its cost function and application to various classification scenarios. Additionally, it introduces the Framingham Heart Study as a case study for applying logistic regression to estimate the risk of coronary heart disease.






![Example: cat vs dog classification
𝜑1 Weight [kg]
Height
[cm]
Cats
Dogs
Classifier function 𝑓
⋅
Suppose that we measure the weight and
height of some dogs and cats
We want to learn the function 𝑓 ⋅ that
can tell us if a given input vector 𝝋 = 𝜑1,
𝜑2
𝖳 is a dog or a cat
• 𝜑1: weight
• 𝜑2: height
QUIZ: The point is classified by the model
as a ?
𝜑2
7 /33](https://image.slidesharecdn.com/lecture-03-logistic-regression-241015232942-89e79097/85/Logistic-regression-Supervised-MachineLearning-pptx-7-320.jpg)


![Why not linear regression?
With two levels, the situation is better. For instance, perhaps there are only two
possibilities for the patient’s medical condition: stroke and drug overdose
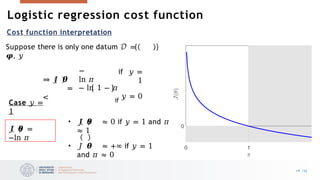
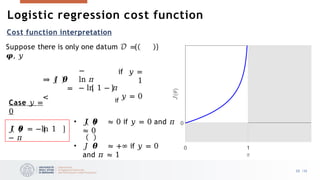
0 if
stroke
𝑦 = <
1
if
drug overdose
We can fit a linear regression to this binary response, and classify as drug overdose if
𝑦C > 0.5 and stroke otherwise, interpreting 𝑦C as a probability of drug overdose
However, if we use linear regression, some of our estimates might be outside the [0, 1]
interval, which does not make sense as a probability. There is nothing that “saturates” the
output between 0 and 1. Logistic function (Sigmoid)
12 /33](https://image.slidesharecdn.com/lecture-03-logistic-regression-241015232942-89e79097/85/Logistic-regression-Supervised-MachineLearning-pptx-12-320.jpg)









![Logistic regression recap
The classification boundary found by
logistic regression is linear
Infact, classifying with the rule:
𝑦 = 1 if 𝑠 𝝋𝖳𝜽 ≥ 0.5
is the same as saying
𝑦 = 1 if 𝝋𝖳𝜽 ≥ 0
Weight [kg]
Height
[cm]
Cats
Dogs
Linear classifier
26 /33](https://image.slidesharecdn.com/lecture-03-logistic-regression-241015232942-89e79097/85/Logistic-regression-Supervised-MachineLearning-pptx-26-320.jpg)
![We want to estimate if a student will get admitted
to a university given the results on two exams (𝜑1, 𝜑2)
• The training set consists of 𝑁 = 100 students
with
𝜑1 𝑖 , 𝜑2 𝑖 and 𝑦 𝑖 ∈ 0,1 , for 𝑖 = 1, … , 𝑁
•
•
•
Φ ∈
ℝ100×3
𝒚 ∈
ℝ100×1
𝜽 ∈ ℝ3×1
% Read data from file
data = load(‘studentsdata.csv’);
Phi = data(:, [1, 2]); y = data(:, 3);
% Setup the data matrix appropriately, and
add ones for the intercept term
[N, m] = size(Phi); d = m + 1;
% Add intercept term
Phi = [ones(N, 1) Phi];
% Initialize fitting parameters
initial_theta = zeros(d, 1);
pi_s = sigmoid(Phi*theta)
J = ( -y'*log(pi_s) – (1-y)'*log(1-pi_s));
grad = Phi'*( pi_s - y);
Embed in a function and pass the function to an
optimization algoritm that iteratively computes
the gradient
28 /33
Students admissions classification](https://image.slidesharecdn.com/lecture-03-logistic-regression-241015232942-89e79097/85/Logistic-regression-Supervised-MachineLearning-pptx-28-320.jpg)











































![ANIMAL_CELL_,_TISSUE_AND_ORGAN_CULTURE[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/animalcelltissueandorganculture1-260204172026-4462b440-thumbnail.jpg?width=640&height=640&fit=bounds)






![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)


