More Related Content

PPTX
Coursera machine learning week7: Support Vector Machines ![[DL輪読会]Deep Learning 第5章 機械学習の基礎](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning5-180601021956-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Deep Learning 第5章 機械学習の基礎 
PDF
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太 
PDF

PDF
明治大学講演資料「機械学習と自動ハイパーパラメタ最適化」 佐野正太郎 
PDF
ディープラーニング入門 ~ 画像処理・自然言語処理について ~ 
PDF

PDF
Optimization and simulation with DataRobot Similar to Coursera machine learning week6

PDF

PPTX
![[輪講] 第1章](https://cdn.slidesharecdn.com/ss_thumbnails/random-171231020415-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX

PDF

PDF

PDF

PDF
Jubatusにおける大規模分散オンライン機械学習 
PDF

PPTX
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで Vm 1 
PDF
確率的深層学習における中間層の改良と高性能学習法の提案 
PDF

PDF
機械学習による統計的実験計画(ベイズ最適化を中心に) 
PDF
SVM実践ガイド (A Practical Guide to Support Vector Classification) 
PDF

PPTX

PDF

PDF

PPTX
数理最適化と機械学習の�融合アプローチ�-分類と新しい枠組み- 
PDF
Hands on-ml section1-1st-half-20210317 
PPTX
Feature engineering for predictive modeling using reinforcement learning More from Kikuya Takumi

PPTX

PPTX

PPTX

PPTX

PPTX

PPTX

PPTX

PPTX
データサイエンス勉強会~機械学習_強化学習による最適戦略の学習 
PPTX

PPTX
Coursera machine learning week6
- 1.
- 2.
アジェンダ
Week5を終えて
Advicefor Applying Machine Learning
学習アルゴリズムの評価
学習した仮説の評価
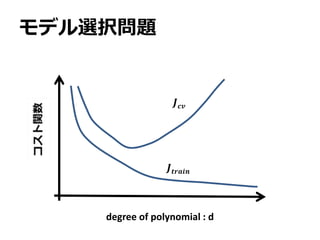
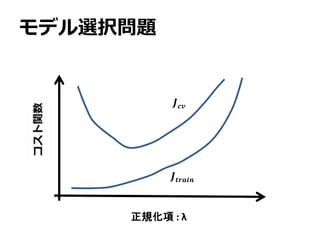
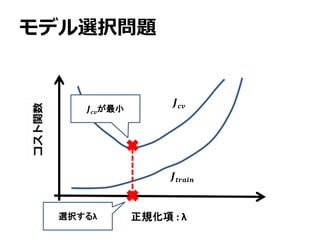
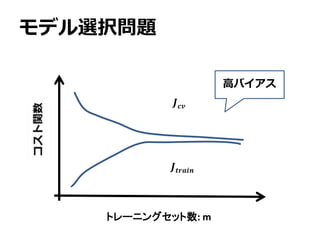
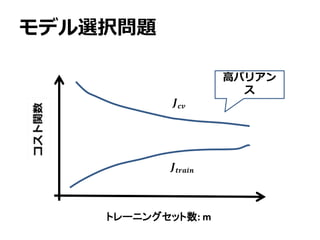
モデル選択問題
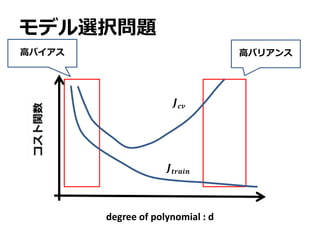
バイアスとバリアンス
Machine Learning System Design
Skewed Data
大量のデータセット
Week6のまとめ
- 3.
アジェンダ
Week5を終えて
Advicefor Applying Machine Learning
学習アルゴリズムの評価
学習した仮説の評価
モデル選択問題
バイアスとバリアンス
Machine Learning System Design
Skewed Data
大量のデータセット
Week6のまとめ
- 4.
- 5.
- 6.
アジェンダ
Week5を終えて
Advicefor Applying Machine Learning
学習アルゴリズムの評価
学習した仮説の評価
モデル選択問題
バイアスとバリアンス
Machine Learning System Design
Skewed Data
大量のデータセット
Week6のまとめ
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
アジェンダ
Week5を終えて
Advicefor Applying Machine Learning
学習アルゴリズムの評価
学習した仮説の評価
モデル選択問題
バイアスとバリアンス
Machine Learning System Design
Skewed Data
大量のデータセット
Week6のまとめ
- 31.
- 32.
- 33.
Skewed Data
分類問題において
予測/観測1(Positive) 0(Negative)
1(Positive) True Positive False Positive
0(Negative) False Negative True Negative
予測がPositiveで、観測Positiveである割合
→Precision(精度)
観測がPositiveで、予測もPositiveの割合
→Recall(再現性)
- 34.
- 35.
- 36.
- 37.
- 38.
アジェンダ
Week5を終えて
Advicefor Applying Machine Learning
学習アルゴリズムの評価
学習した仮説の評価
モデル選択問題
バイアスとバリアンス
Machine Learning System Design
Skewed Data
大量のデータセット
Week6のまとめ
- 39.
- 40.