









![Another view of logistic regression
Log odds : ln [ p/(1-p) ] = wX + ε
p / (1-p) = ewX
p = (1-p) ewX
p (1 + ewX) = ewX
p = ewX / (1 + ewX) = 1/(e-wX+1)
Logistic regression is a “linear regression” between log-
odds of an event and features (X)
4/15/11 17](https://image.slidesharecdn.com/kritipuniyanimeetupnycapr2011-110415122715-phpapp02/75/Intro-to-Classification-Logistic-Regression-SVM-17-2048.jpg)









![Patient Diagnosis
Y = disease
X = [age, weight, BP, blood sugar, MRI, genetic tests …]
Don’t want all “features” to be relevant.
Weight vector w should be “mostly zeros”.
4/15/11 29](https://image.slidesharecdn.com/kritipuniyanimeetupnycapr2011-110415122715-phpapp02/75/Intro-to-Classification-Logistic-Regression-SVM-29-2048.jpg)

![L1 v/s L2 example
MLE estimate : [ 11 0.8 ]
L2 estimate : [ 10 0.6 ] shrinkage
L1 estimate : [ 10.2 0 ] sparsity
Mini-conclusion :
L2 optimization is fast, L1 tends to be slower. If you have the
computational resources, try both (at the same time) !
ALWAYS run logistic regression with at least some
regularization.
Corollary : ALWAYS run logistic regression on features that
have been standardized (zero mean, unit variance)
4/15/11 31](https://image.slidesharecdn.com/kritipuniyanimeetupnycapr2011-110415122715-phpapp02/75/Intro-to-Classification-Logistic-Regression-SVM-31-2048.jpg)


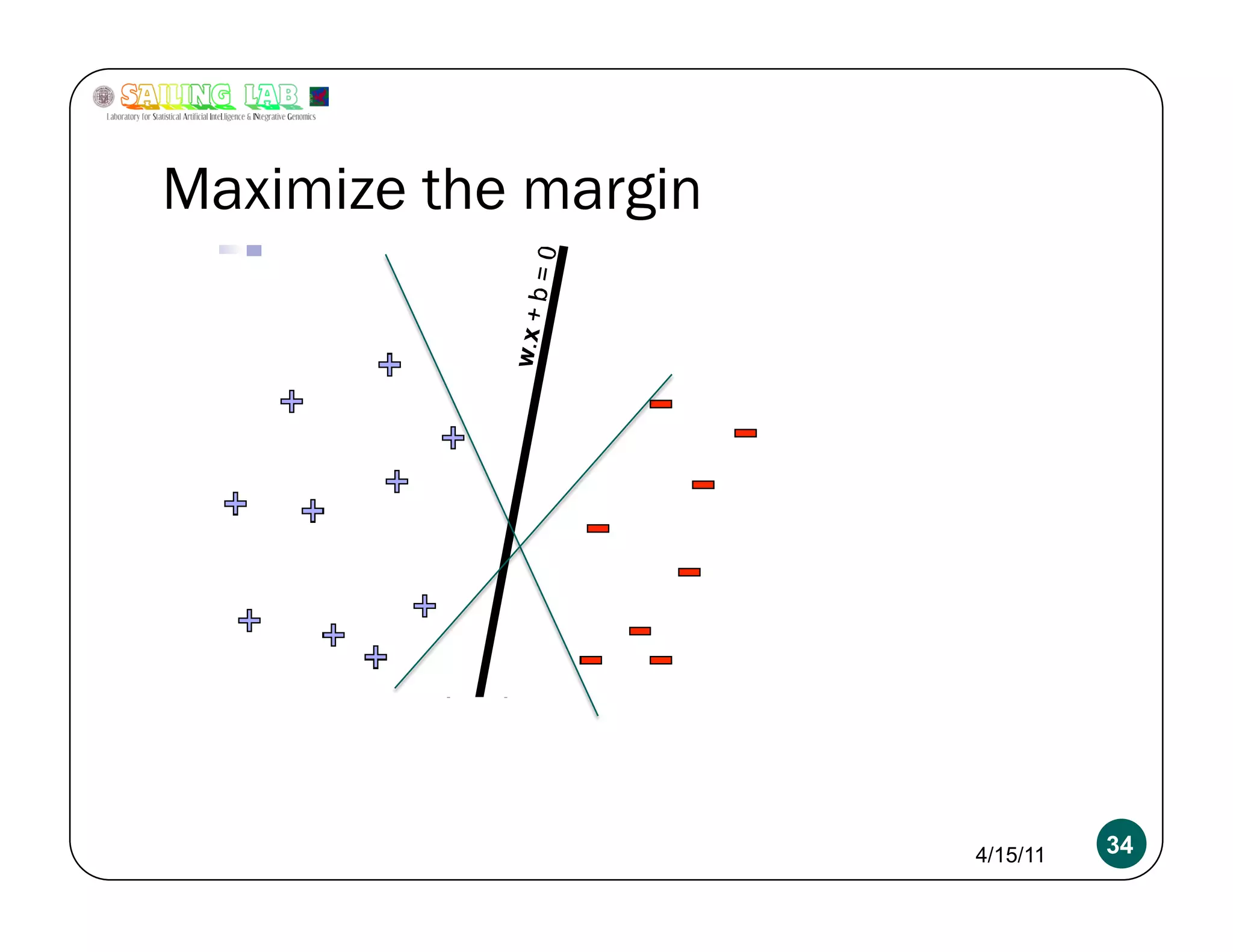
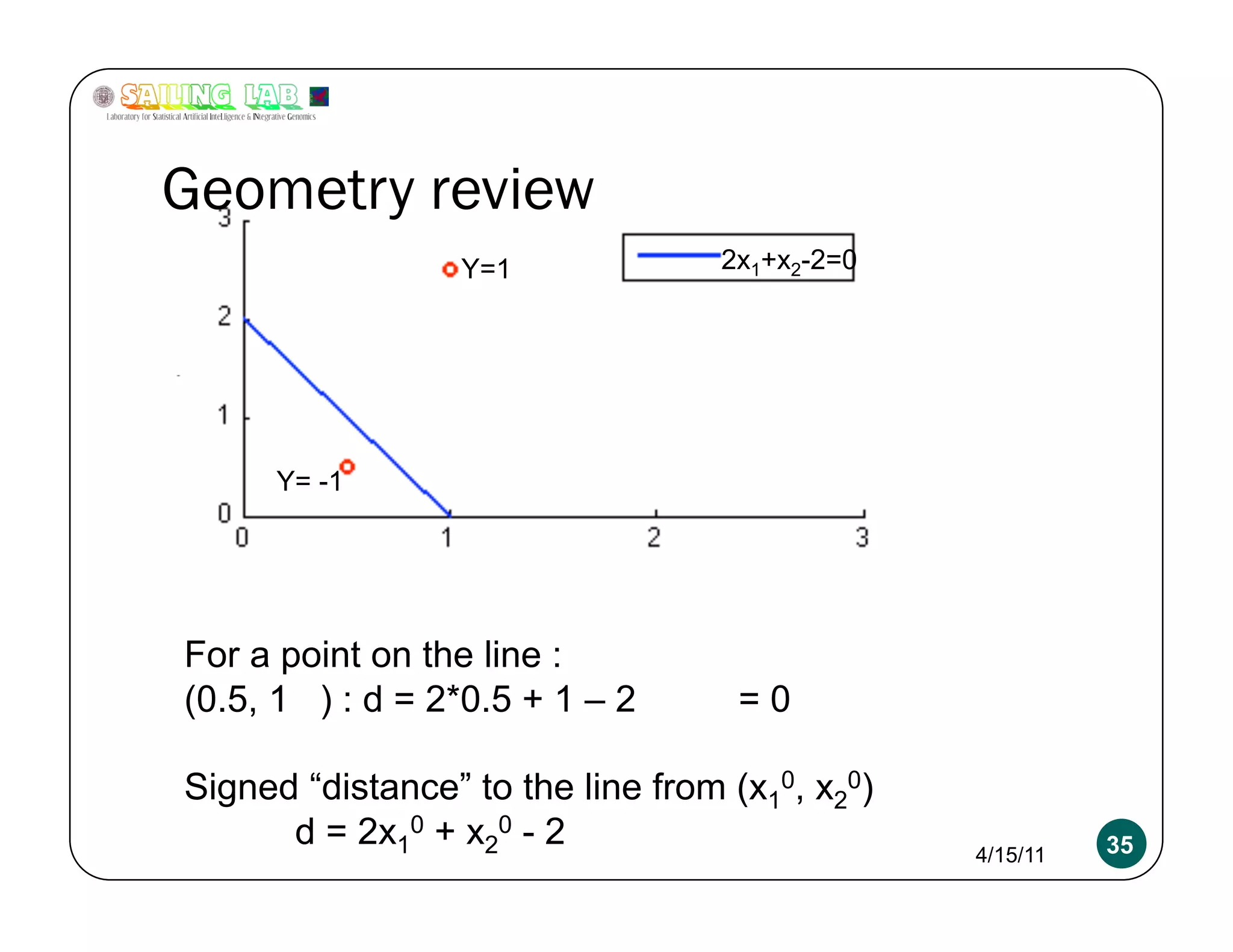
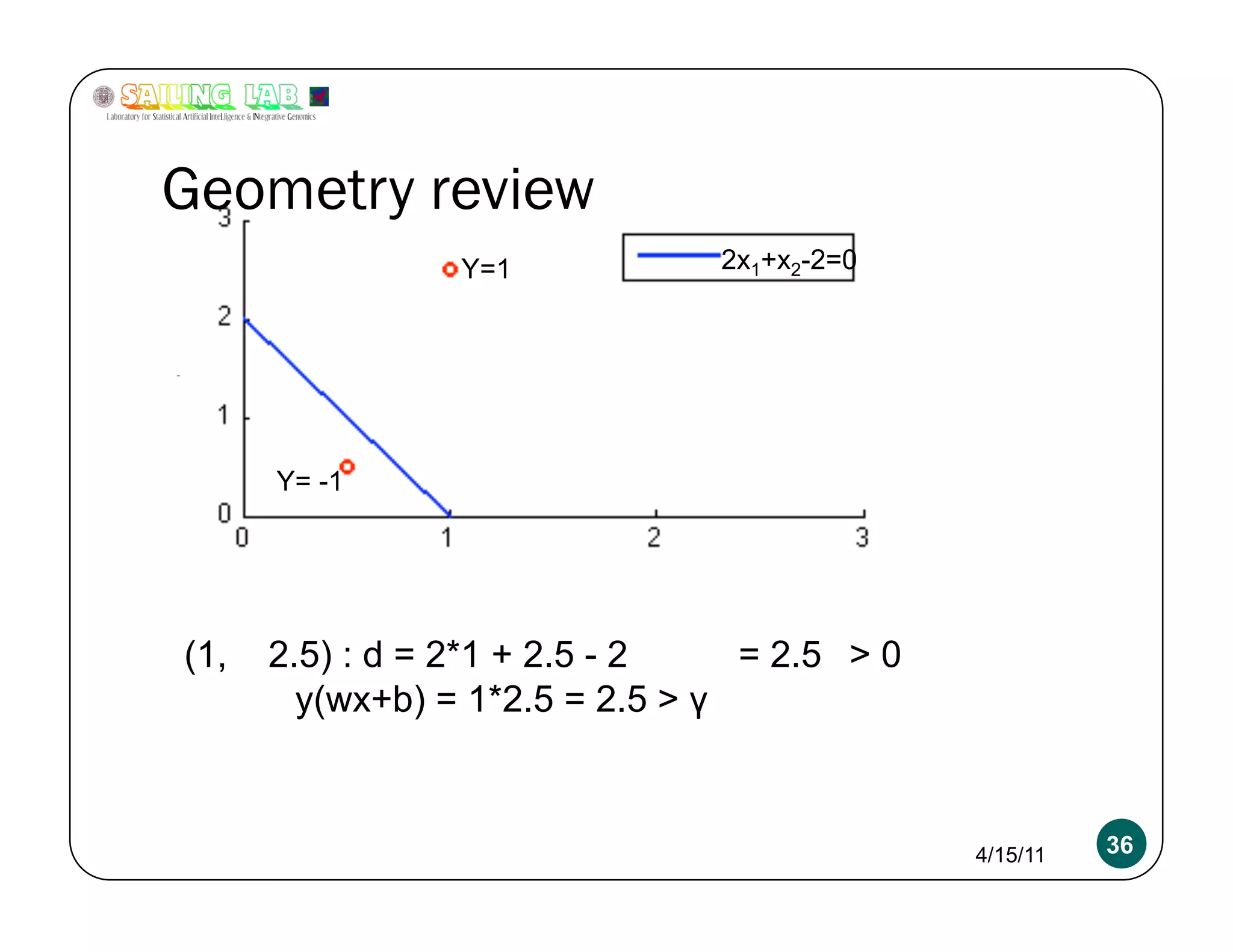
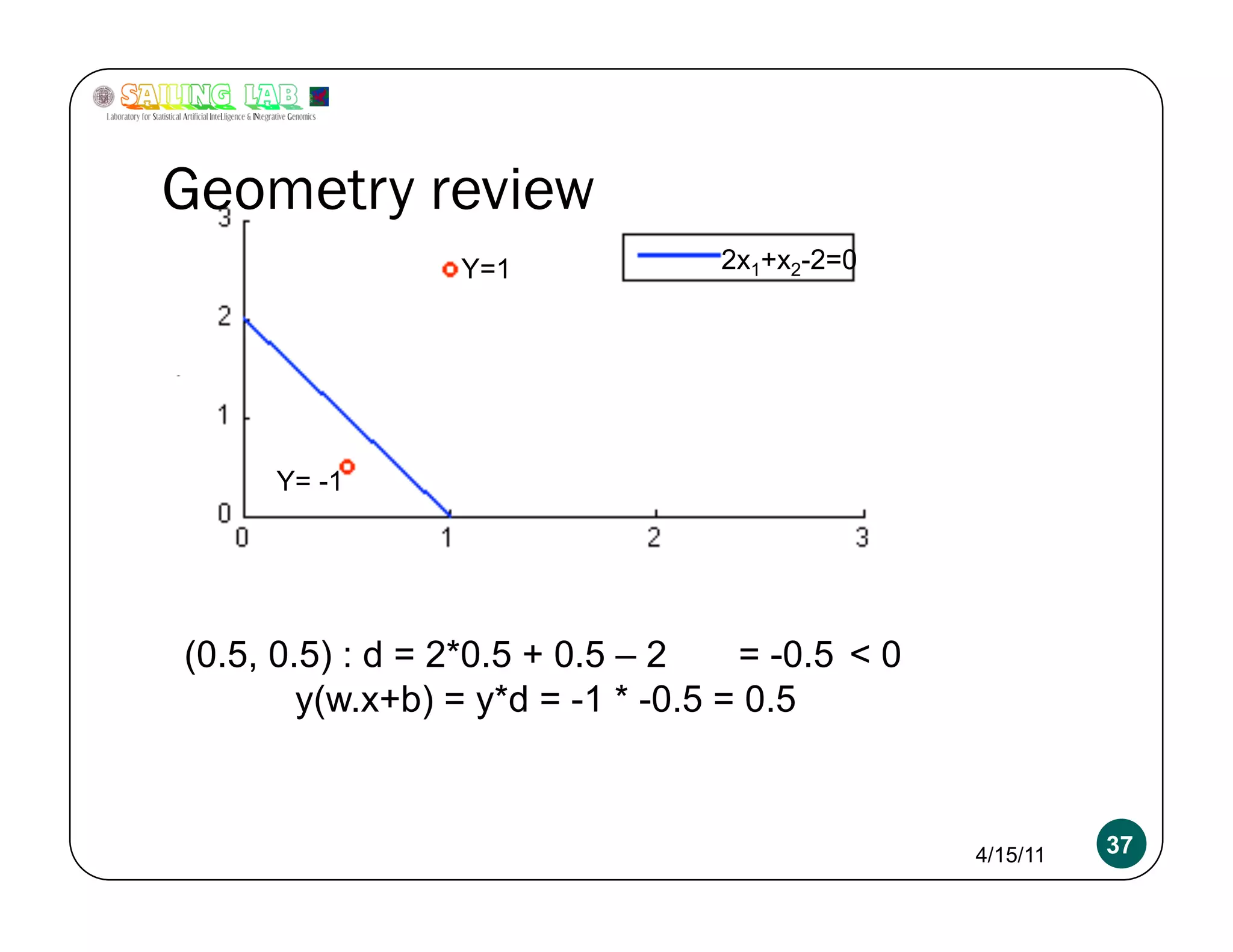
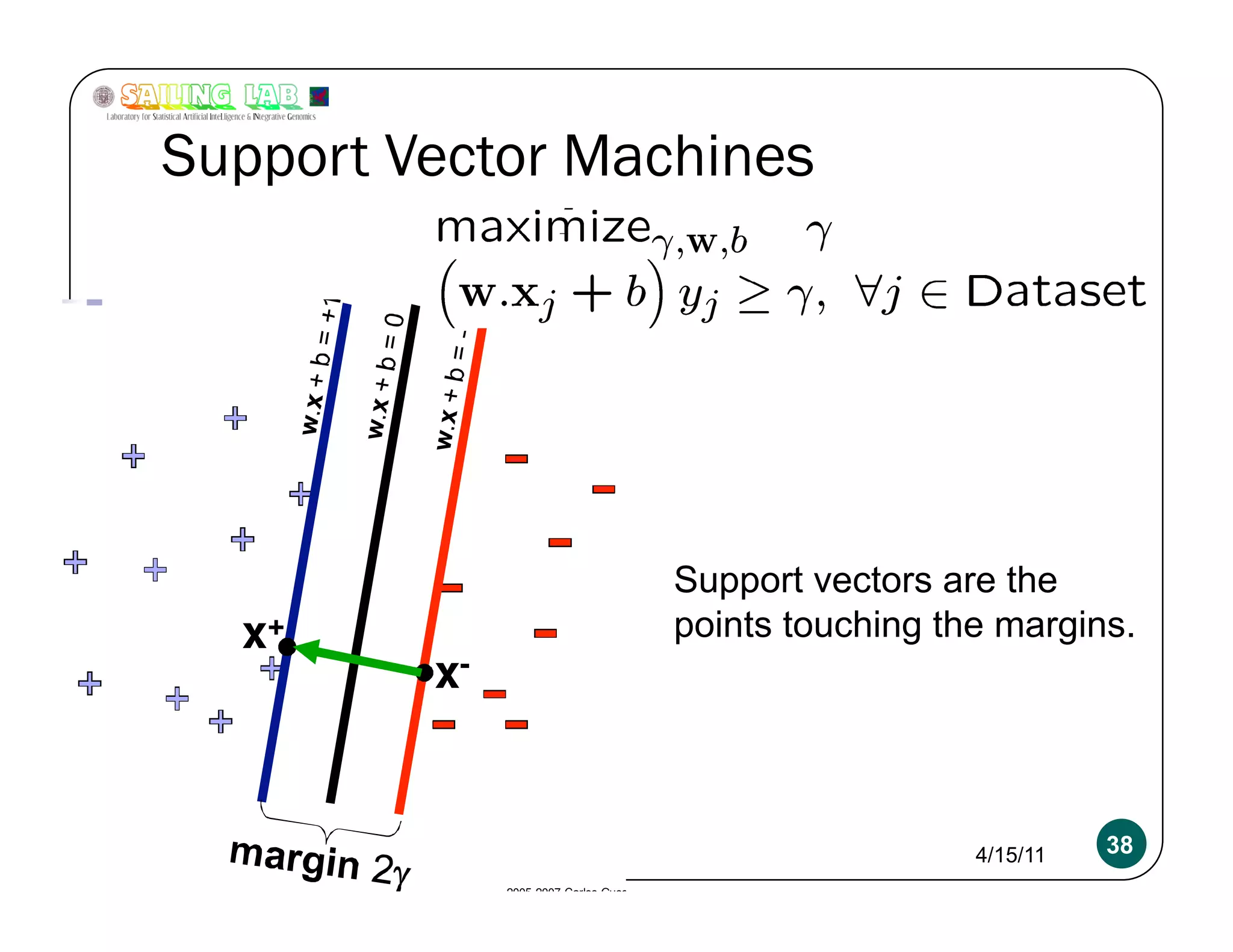




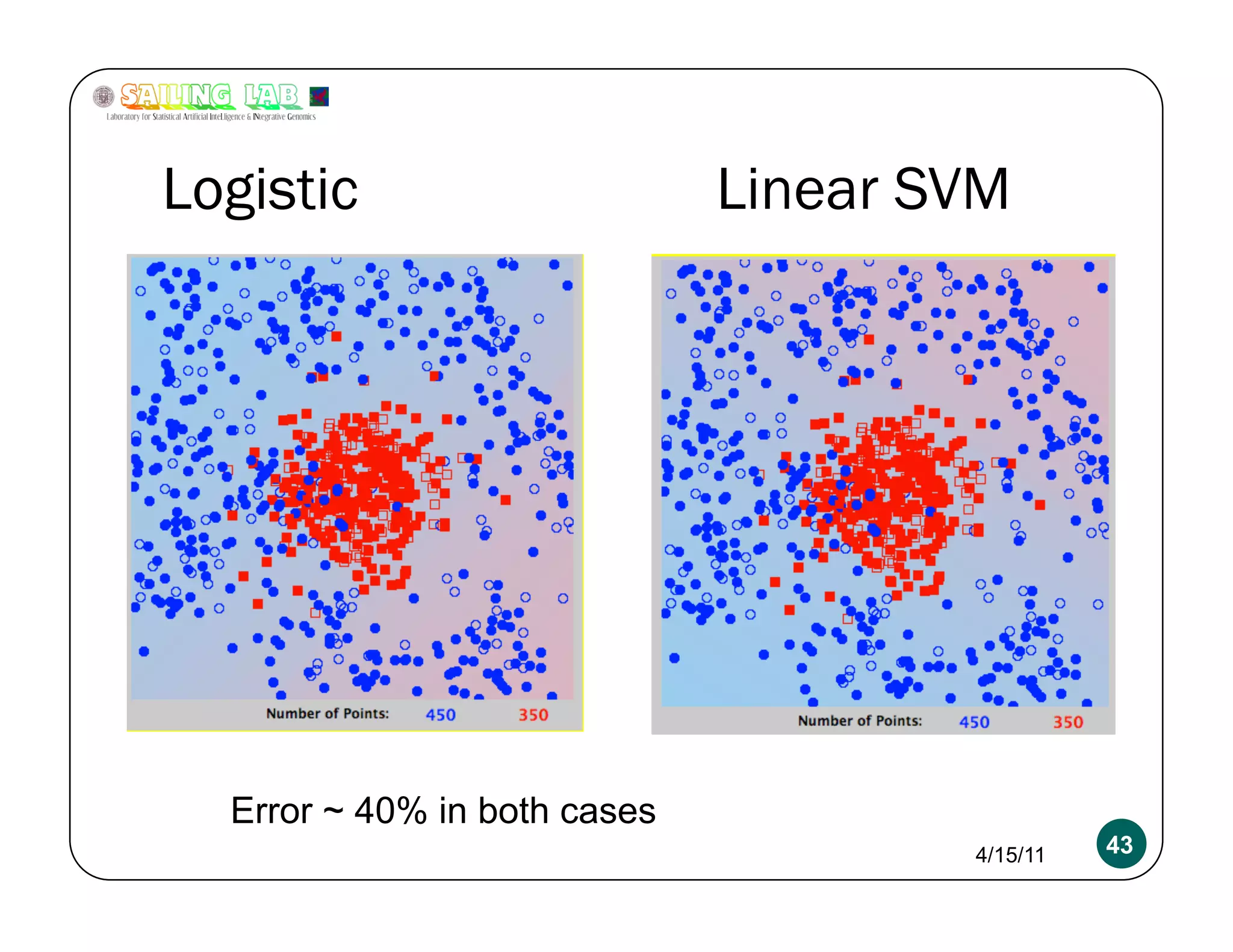
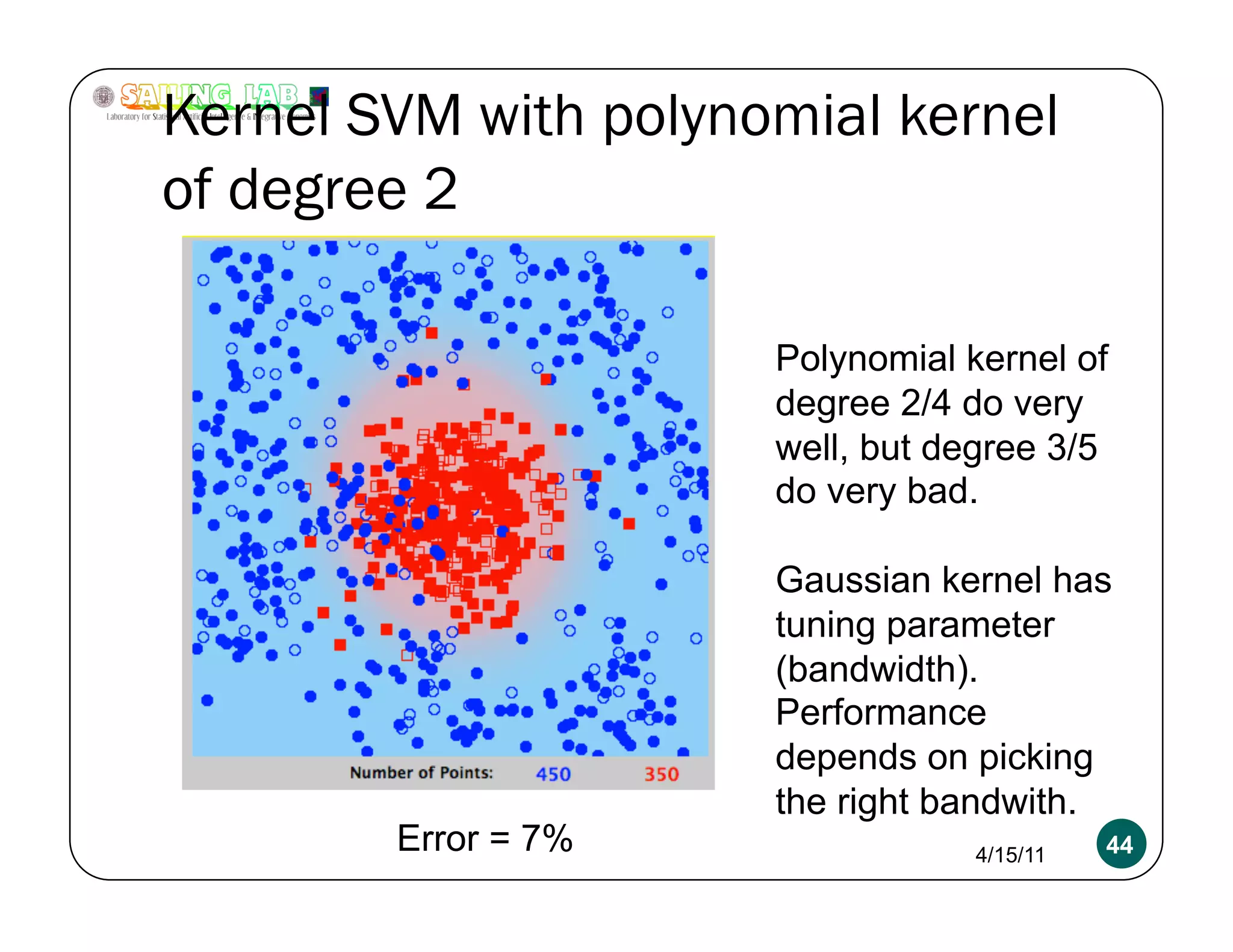









![Overfitting a more serious problem
2x+y-2 = 0 w = [2 1 -2]
4x+2y-4 = 0 w = [4 2 -4]
400x+200y-400 = 0 w = [400 200 -400]
Absolutely need L2 regularization 4/15/11 54](https://image.slidesharecdn.com/kritipuniyanimeetupnycapr2011-110415122715-phpapp02/75/Intro-to-Classification-Logistic-Regression-SVM-54-2048.jpg)

The document is a presentation focusing on machine learning, particularly classification using logistic regression and support vector machines (SVMs). It outlines key concepts such as models, inference, and learning, while discussing regularization techniques to prevent overfitting and improving model accuracy. Additionally, it compares logistic regression and SVMs, emphasizing their applications and the importance of selecting appropriate models based on data characteristics.












































































