Downloaded 145 times






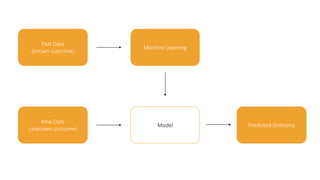



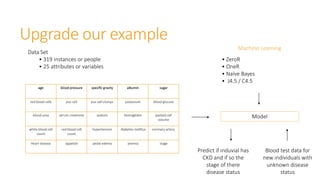
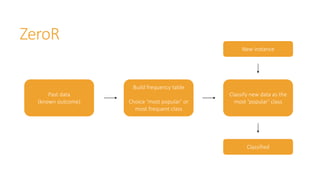

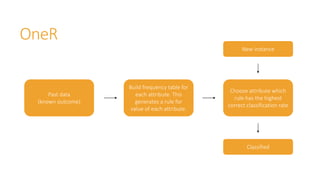

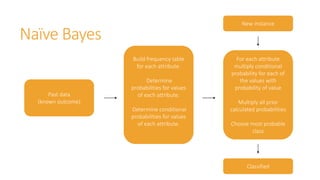

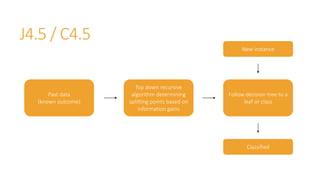
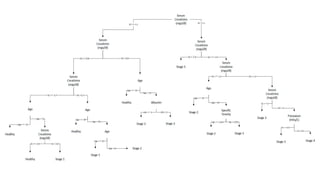

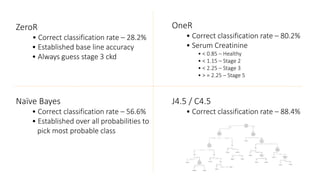






Machine learning models are trained on past data with known outcomes to predict unknown future outcomes. The document compares several machine learning algorithms on a medical dataset to predict kidney disease: - ZeroR classified 28.2% correctly by always predicting stage 3 disease. - Naive Bayes classified 56.6% correctly using attribute probabilities. - OneR classified 80.2% correctly with a single rule based on serum creatinine levels. - J4.5 decision tree classified the highest at 88.4% correctly by recursively splitting data into subgroups based on attribute information gains.



























![[IJET-V2I3P22] Authors: Harsha Pakhale,Deepak Kumar Xaxa](https://cdn.slidesharecdn.com/ss_thumbnails/ijet-v2i3p22-160711112719-thumbnail.jpg?width=640&height=640&fit=bounds)












































