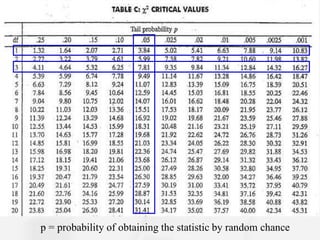
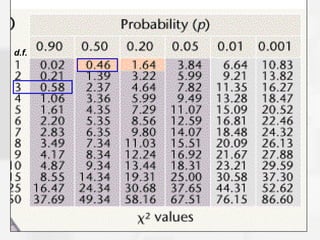
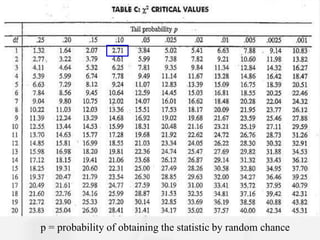
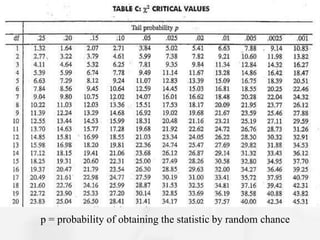
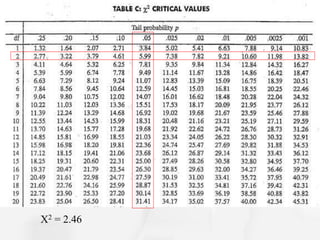
The document discusses the Chi-Square statistic, which is used to compare observed categorical data to expected values to determine if any differences are statistically significant. It outlines the assumptions, requirements, and steps to conduct a Chi-Square analysis, including defining the null hypothesis, calculating expected and observed frequencies, determining the Chi-Square value and degrees of freedom, and comparing the Chi-Square value to a table to either reject or fail to reject the null hypothesis. The document emphasizes that a Chi-Square analysis determines the probability that any differences between observed and expected are due to chance rather than a real association between variables.