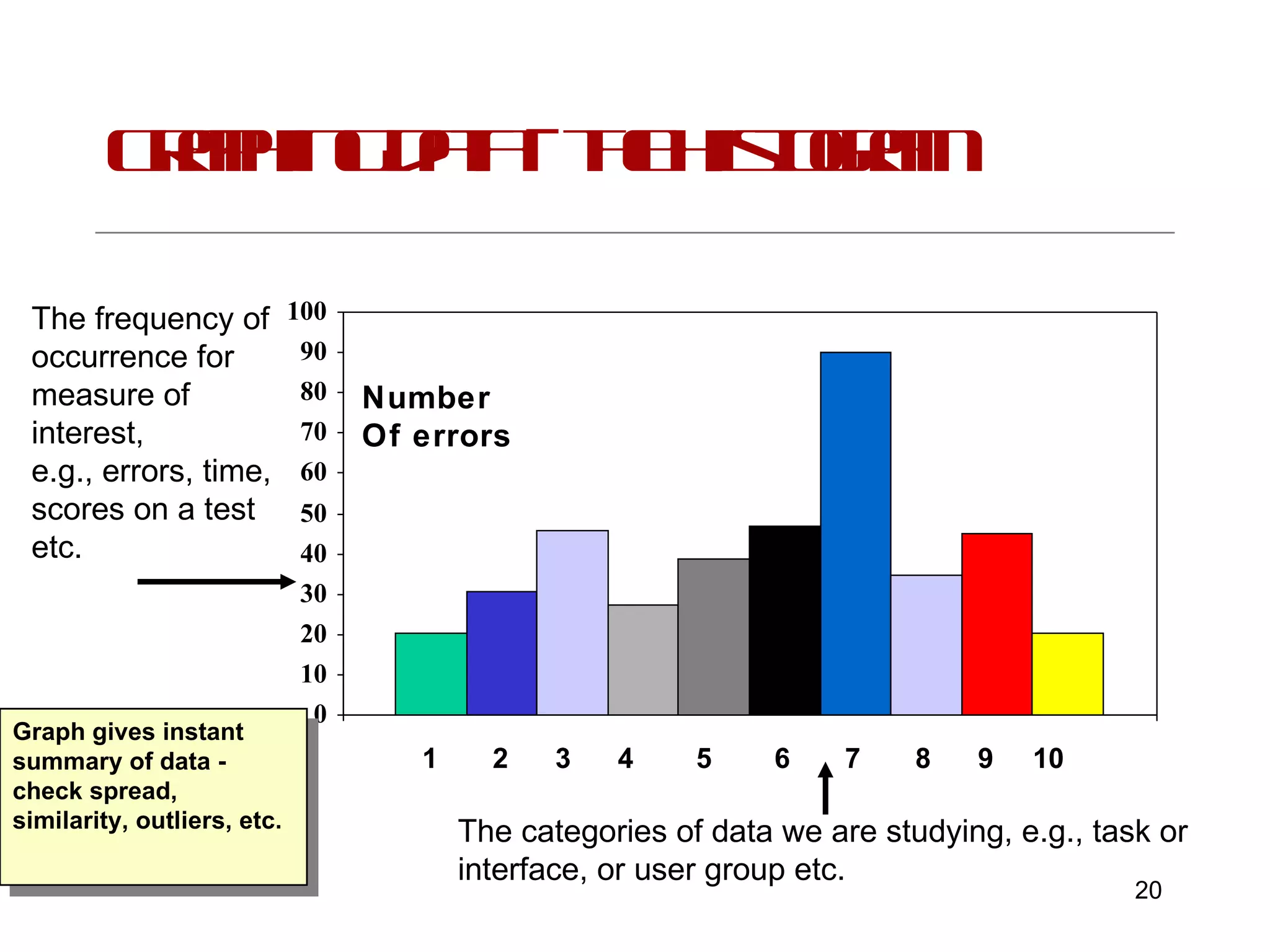
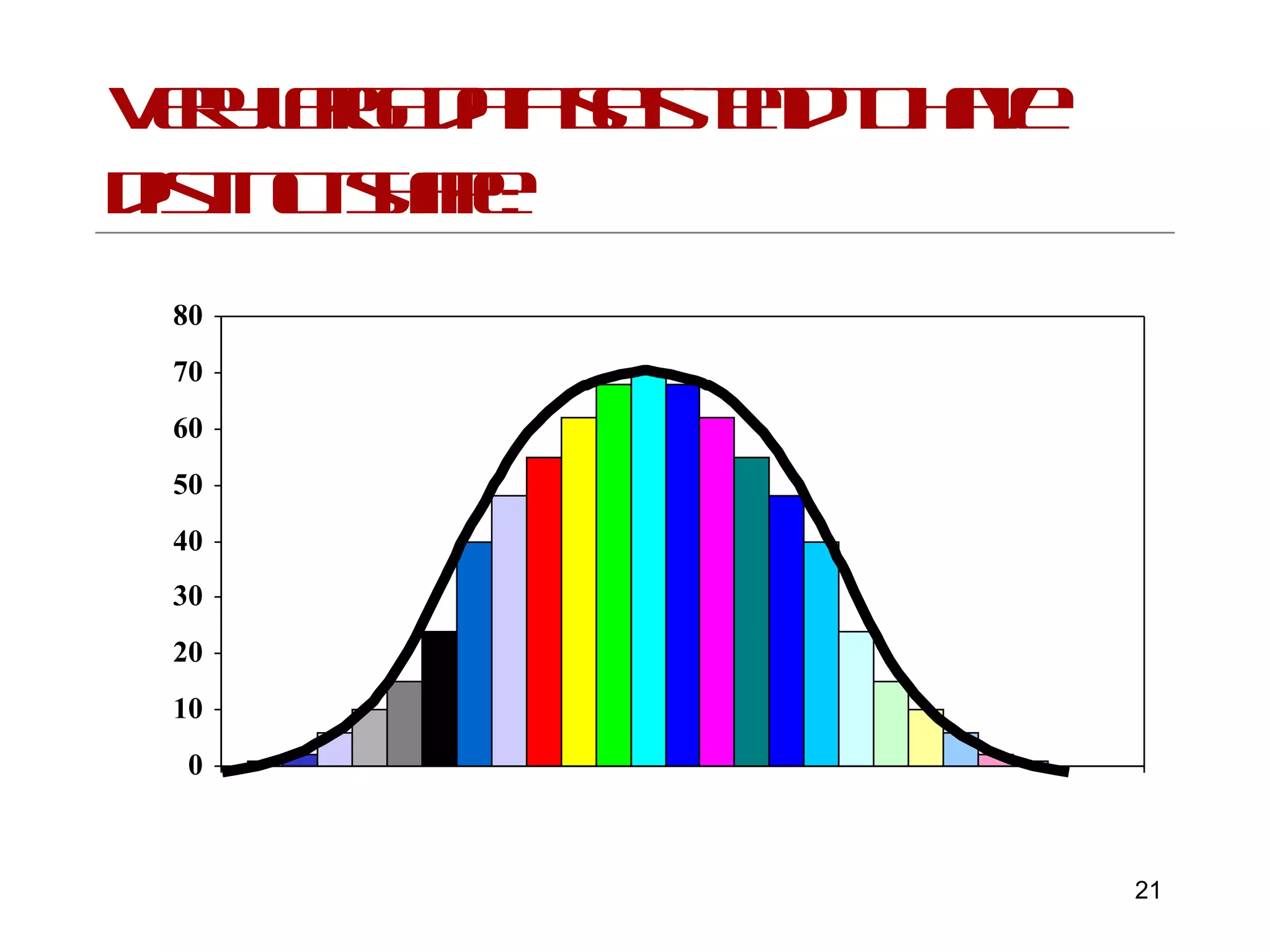
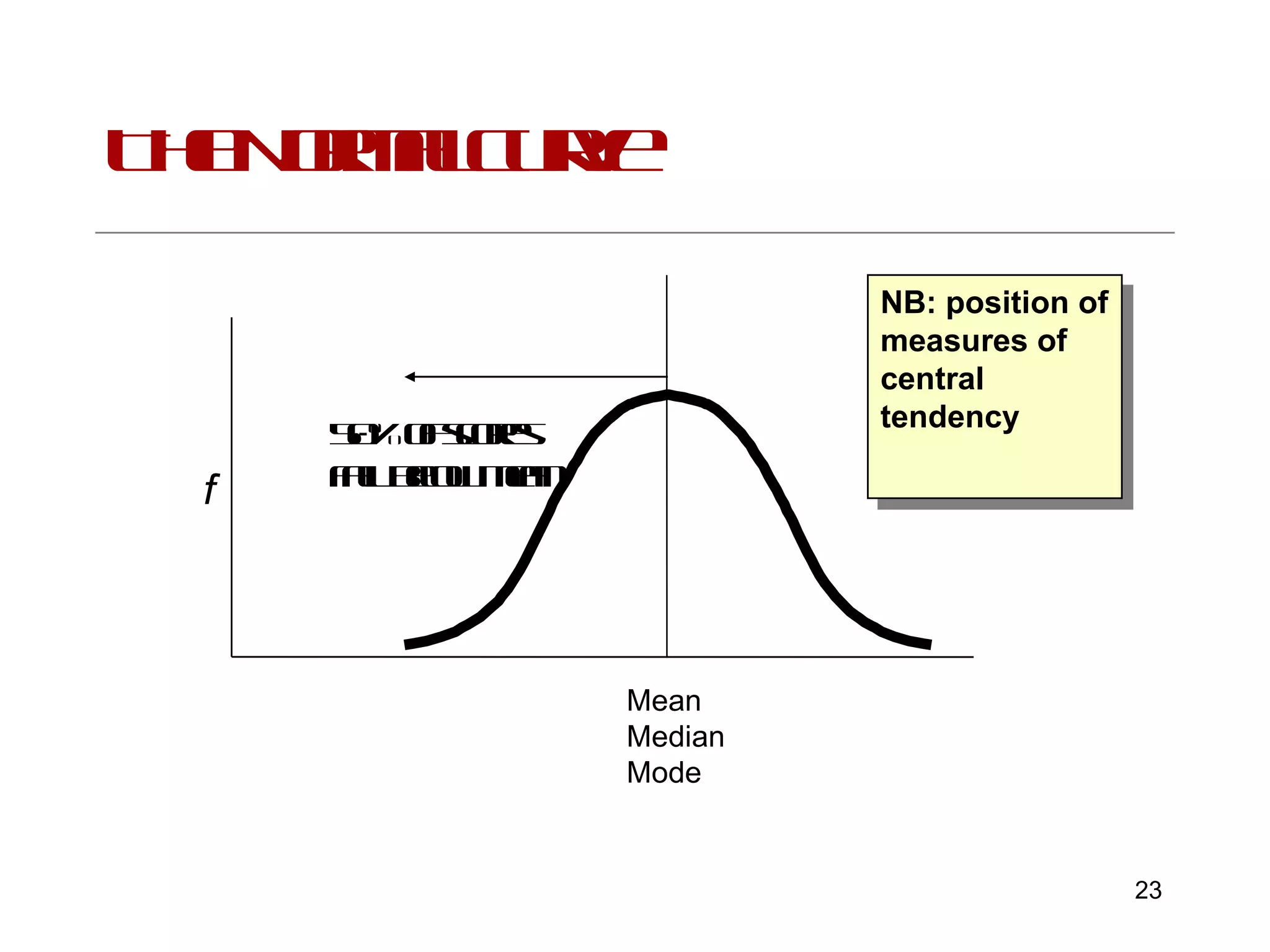
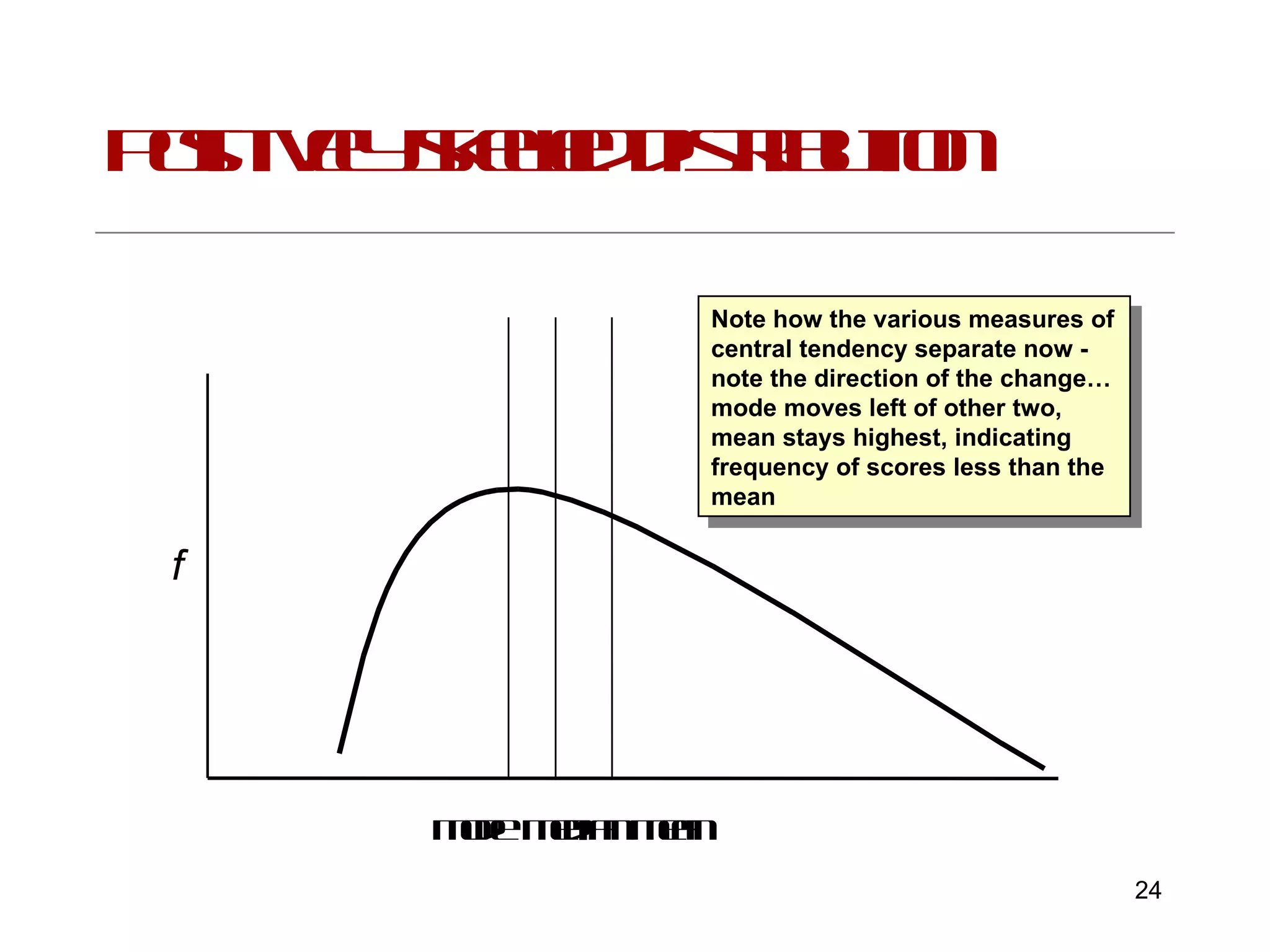
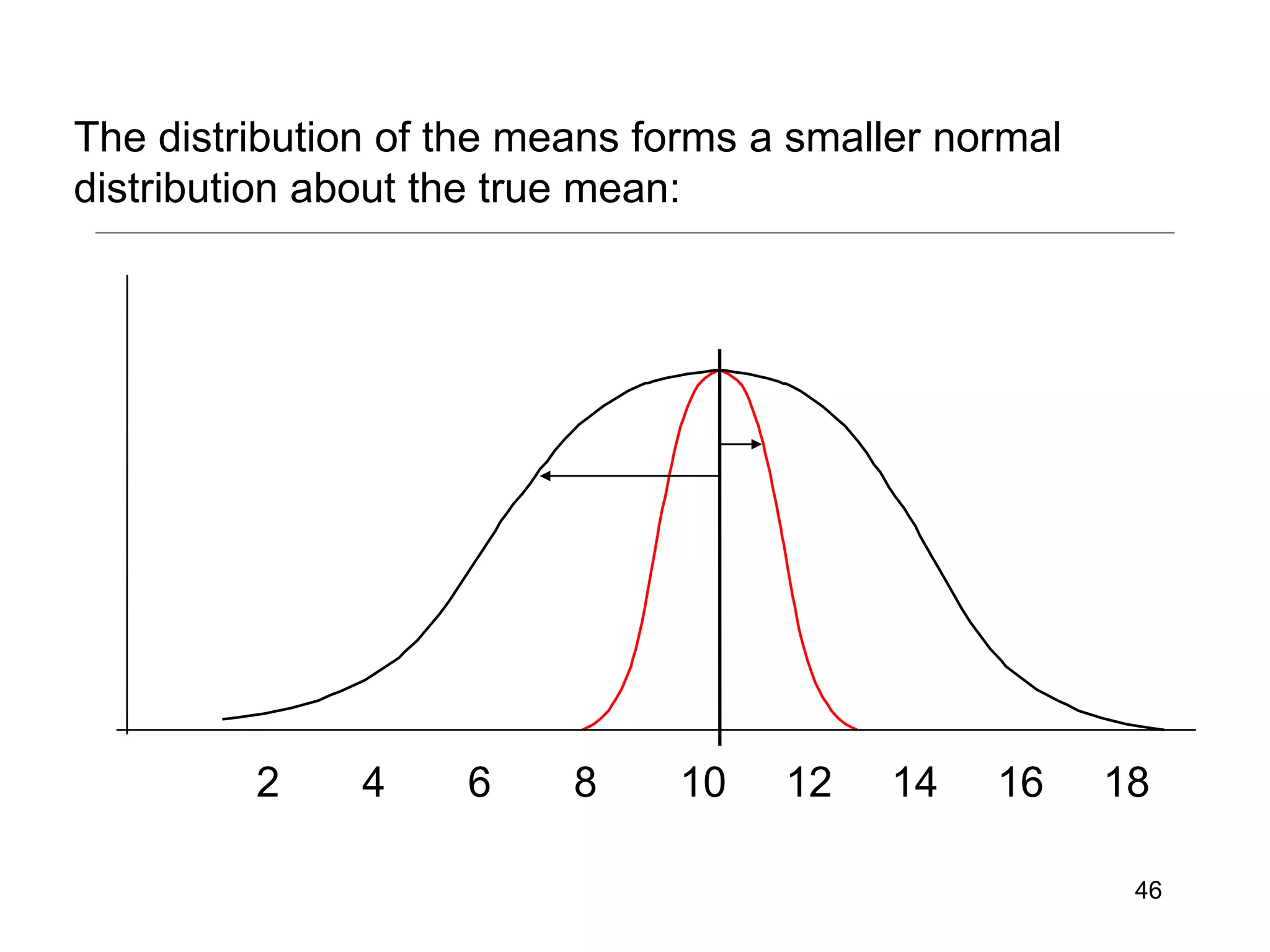
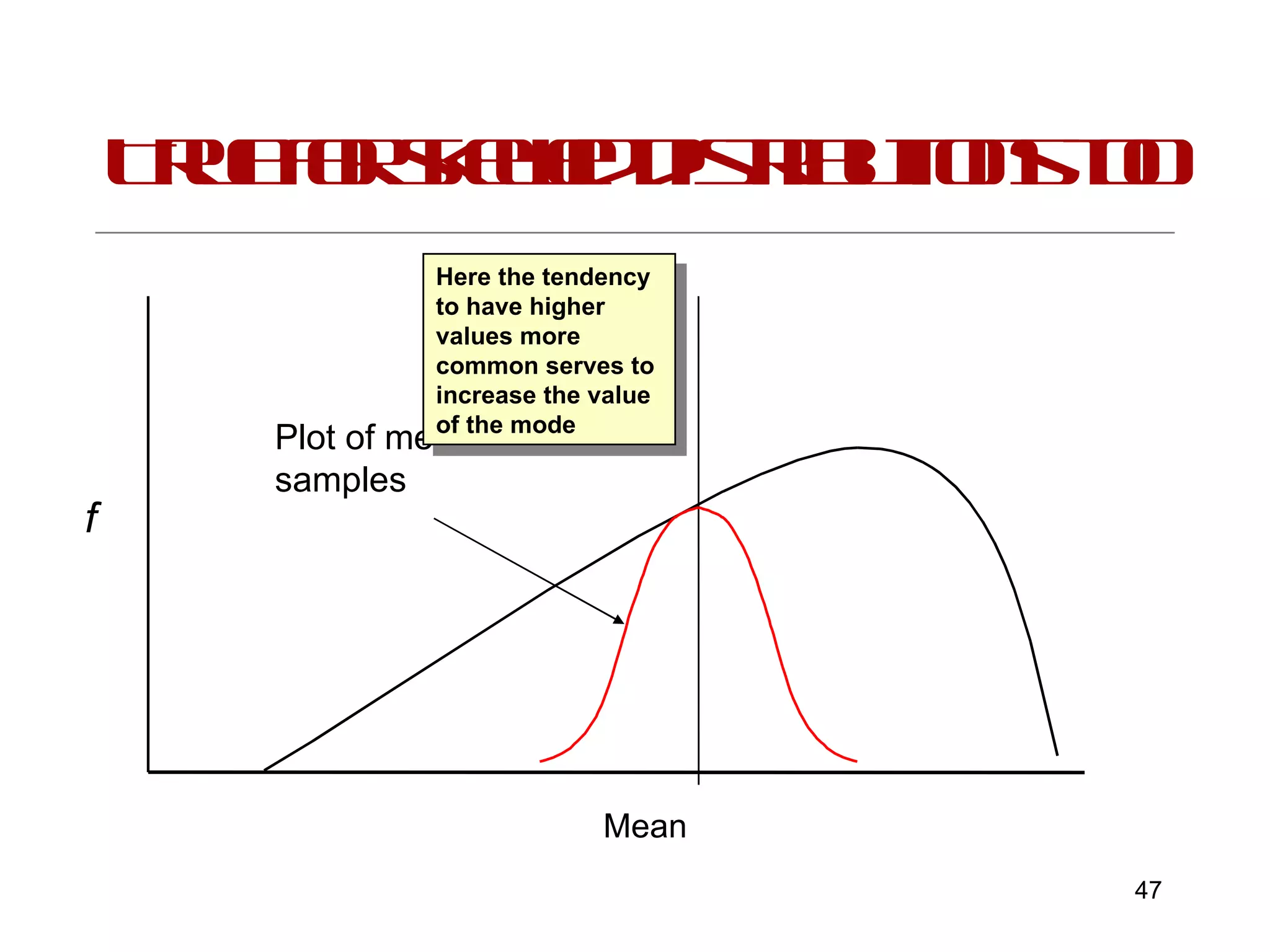
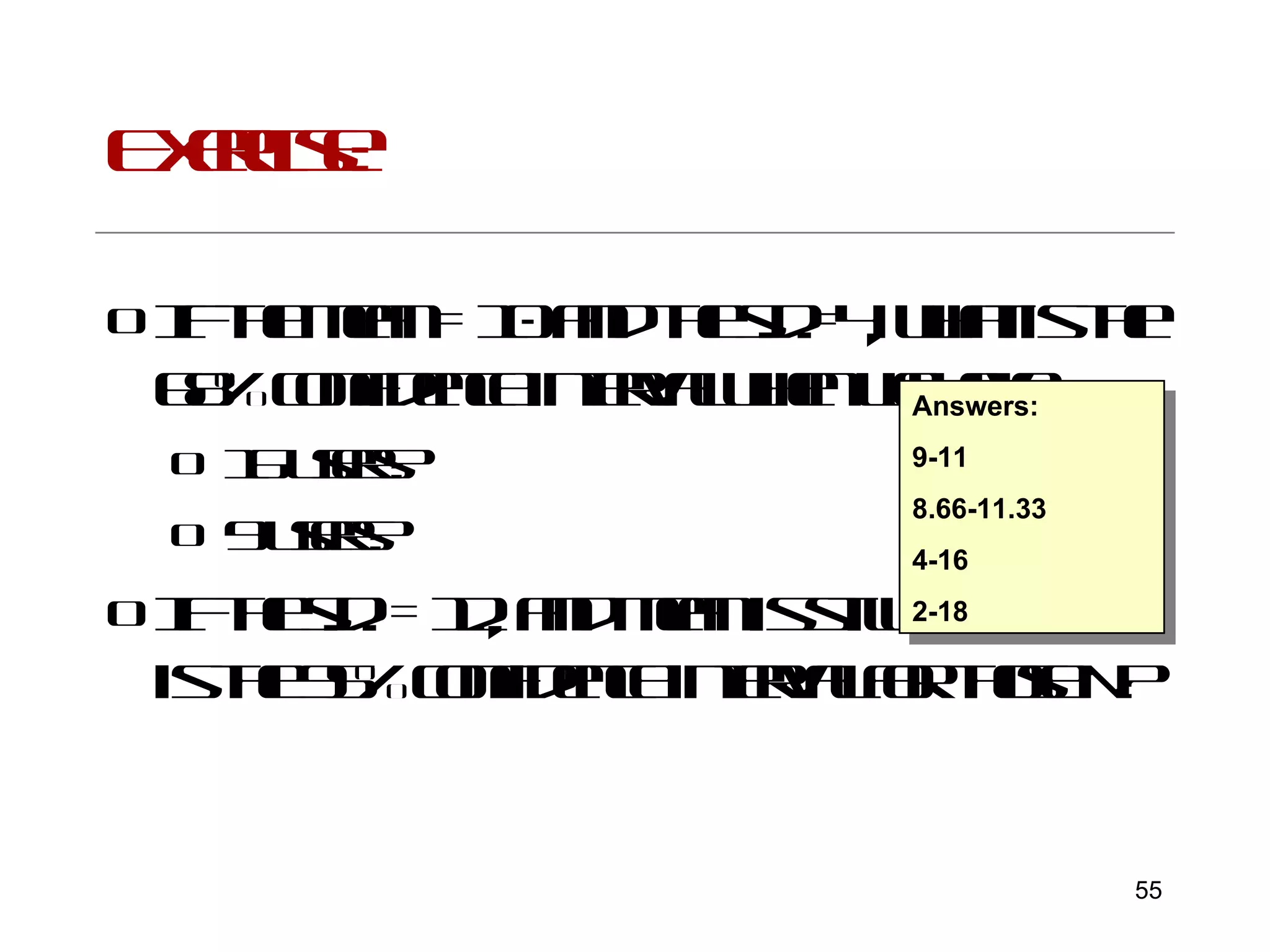
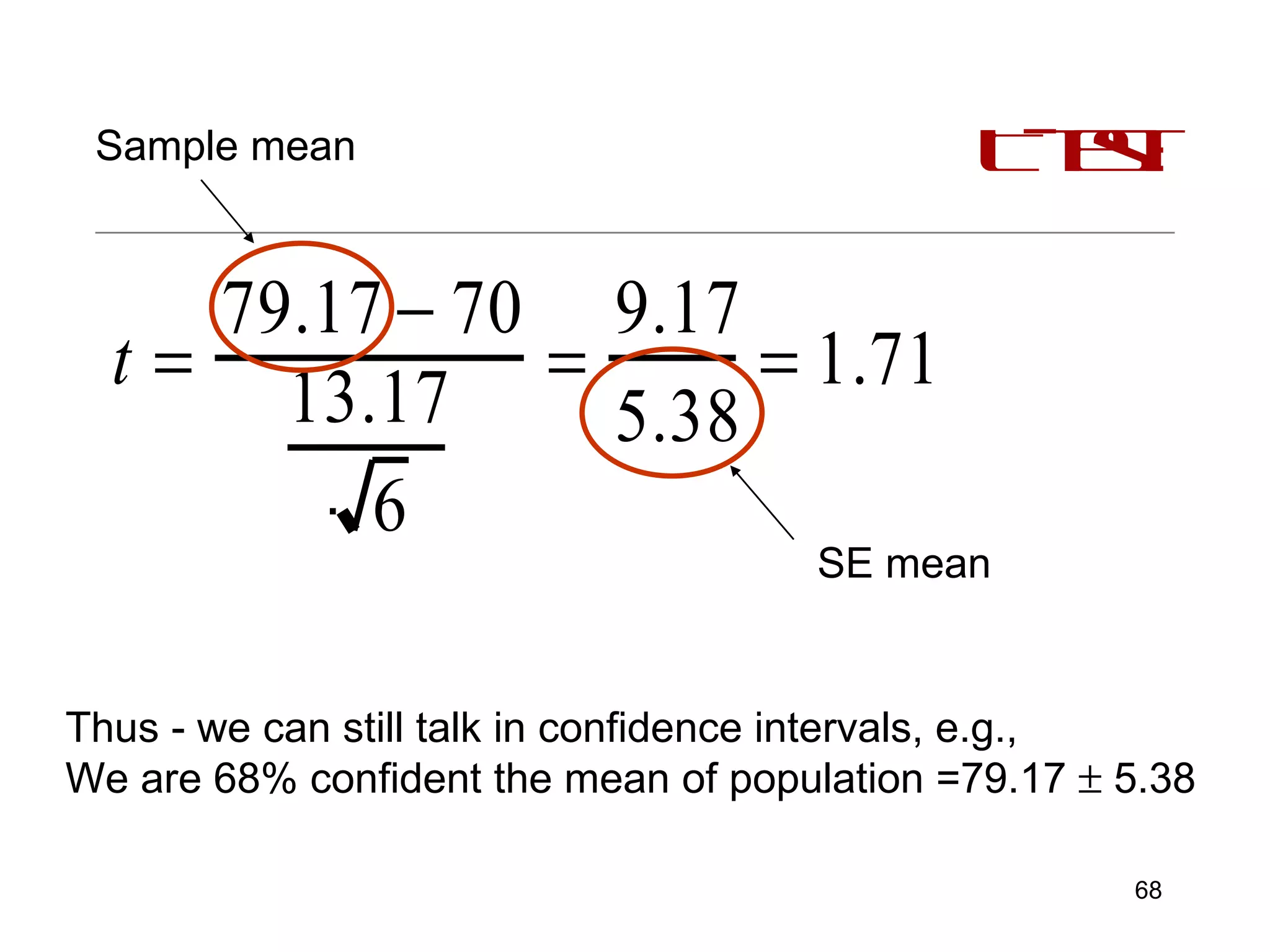
This document provides an introduction to inferential statistics and statistical significance. It discusses key concepts like standard error of the mean, confidence intervals, and comparing means from two samples using a t-test. The document explains how inferential statistics allow researchers to make inferences about populations based on samples and determine if observed differences are likely due to chance or a real effect.

![Do you speak the language? t = n 1 - X B 2 X B 2 ( ) n 2 - 1 n 1 + ( ) x - ( n 1 -1) + (n 2 -1) X A — X B — X A 2 X A 2 ( ) ( ) ( ) + [ ] 1 n 2](https://image.slidesharecdn.com/researchclass-dillon-111020084916-phpapp01/75/statistics-2-2048.jpg)
![Don’t Panic ! t = n 1 - X B 2 X B 2 ( ) n 2 - 1 n 1 + ( ) x - Compare with SD formula ( n 1 -1) + (n 2 -1) Difference between means X A — X B — X A 2 X A 2 ( ) ( ) ( ) + [ ] 1 n 2](https://image.slidesharecdn.com/researchclass-dillon-111020084916-phpapp01/75/statistics-3-2048.jpg)











![Interpreting Z scores Mean = 70,SD = 6 Then a score of 82 is 2 sd [ (82-70)/6] above the mean, or 82 = Z score of 2 Similarly, a score of 64 = a Z score of -1 By using Z scores, we can standardize a set of scores to a scale that is more intuitive Many IQ tests and aptitude tests do this, setting a mean of 100 and an SD of 10 etc.](https://image.slidesharecdn.com/researchclass-dillon-111020084916-phpapp01/75/statistics-17-2048.jpg)