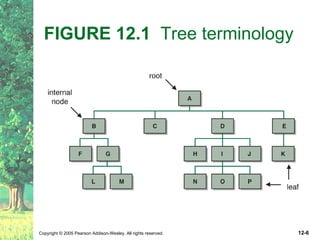
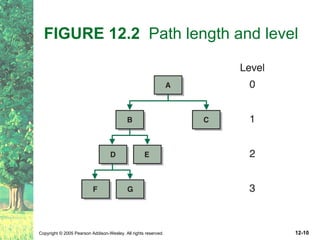
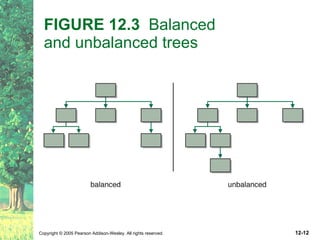
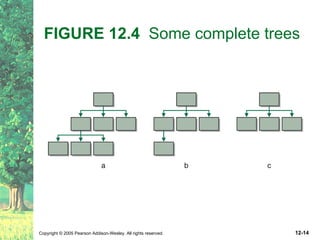
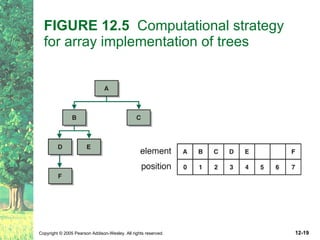
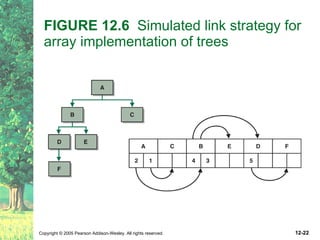
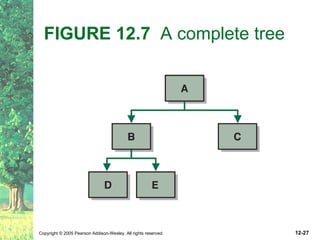
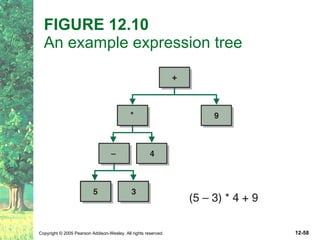
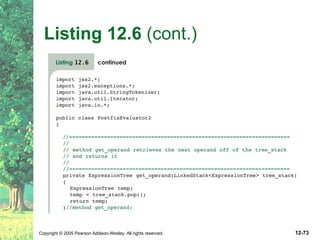
This document defines key terms related to trees as data structures. It discusses different implementations of trees using links and arrays, and different traversal methods for trees including preorder, inorder, postorder, and levelorder traversal. It also provides examples of binary tree implementations using classes for tree nodes and the tree itself.