Download as PDF, PPTX






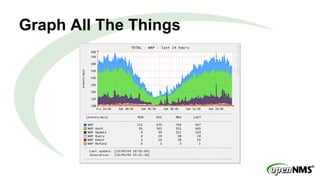





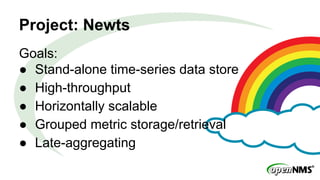




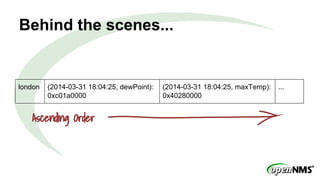



The document discusses a Meetup presentation by Eric Evans on time-series data storage using Cassandra and its capabilities for high-throughput, horizontally scalable storage and retrieval of grouped metrics. It highlights the limitations of the existing RRDTool system and presents Newts as a solution with optimized writing and retrieval of sample data, structured as a key-value format. Key features include the aggregation of measurements at query time and a sample structure for data organization.







![TypoScript and EEL outside of Neos [InspiringFlow2013]](https://cdn.slidesharecdn.com/ss_thumbnails/typoscriptandeel-130420043915-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)













![[Paper Reading] Efficient Query Processing with Optimistically Compressed Has...](https://cdn.slidesharecdn.com/ss_thumbnails/icde-2020-220209161641-thumbnail.jpg?width=640&height=640&fit=bounds)










































































