Downloaded 29 times

















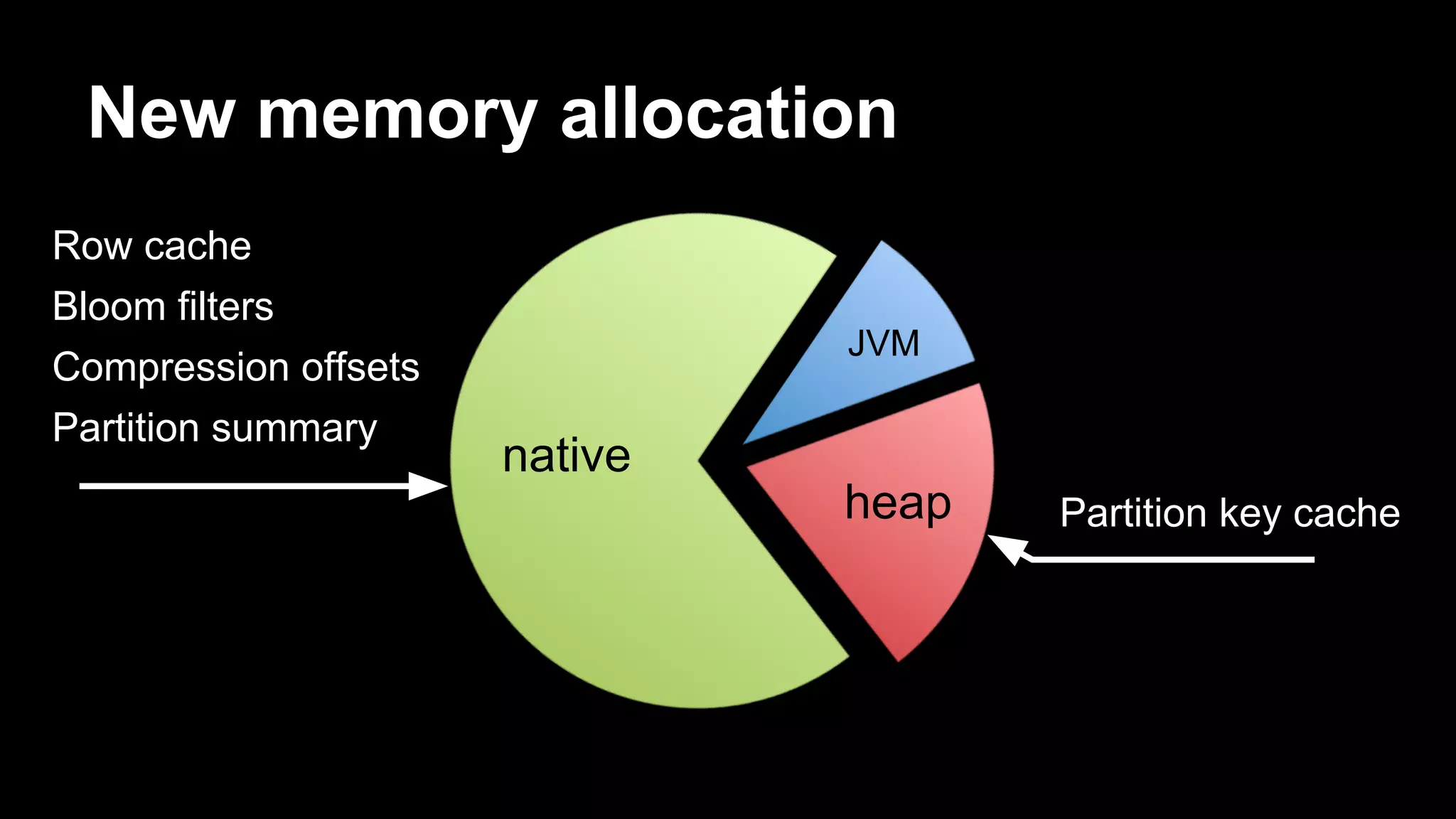











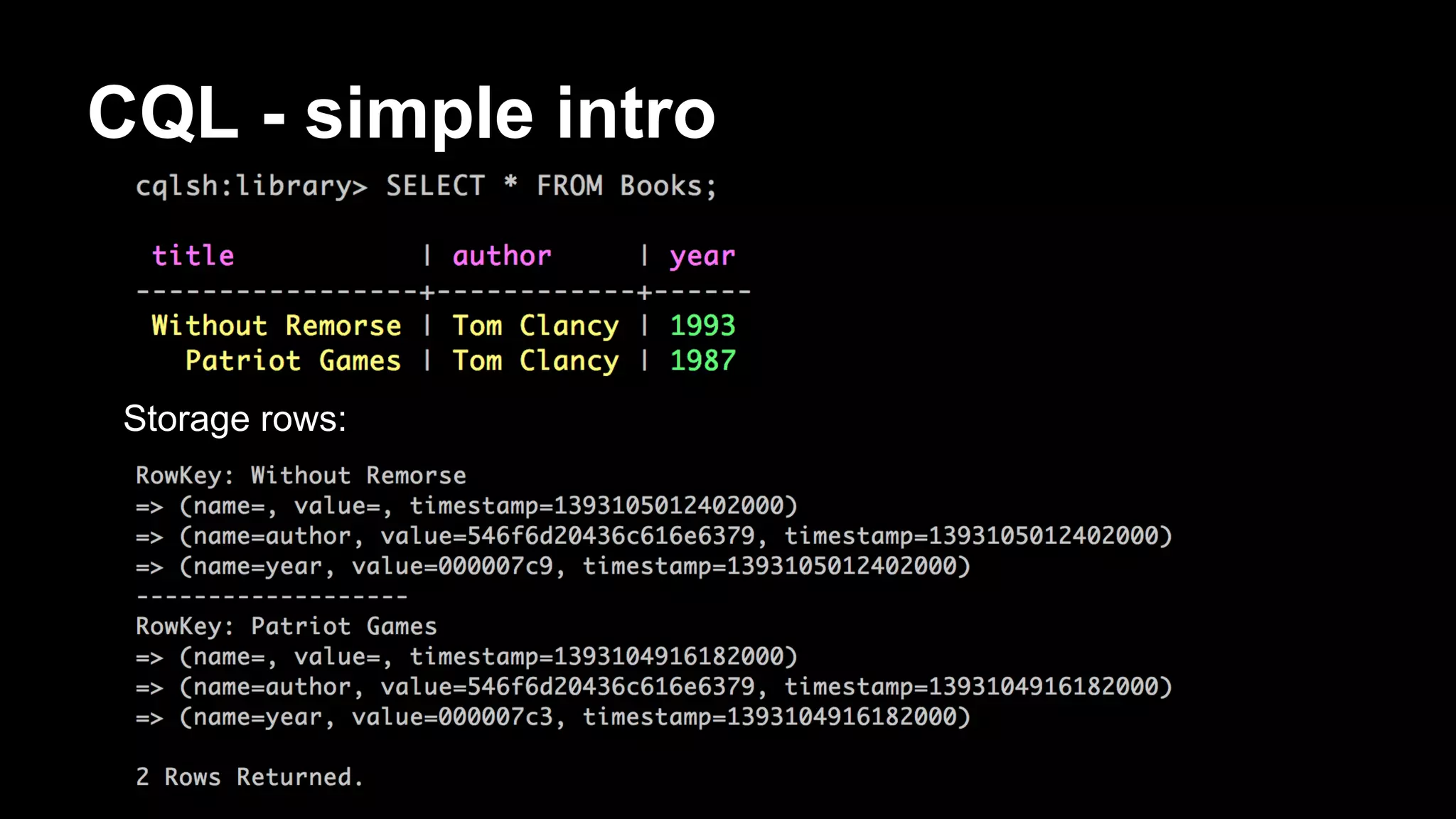
![Storage rows
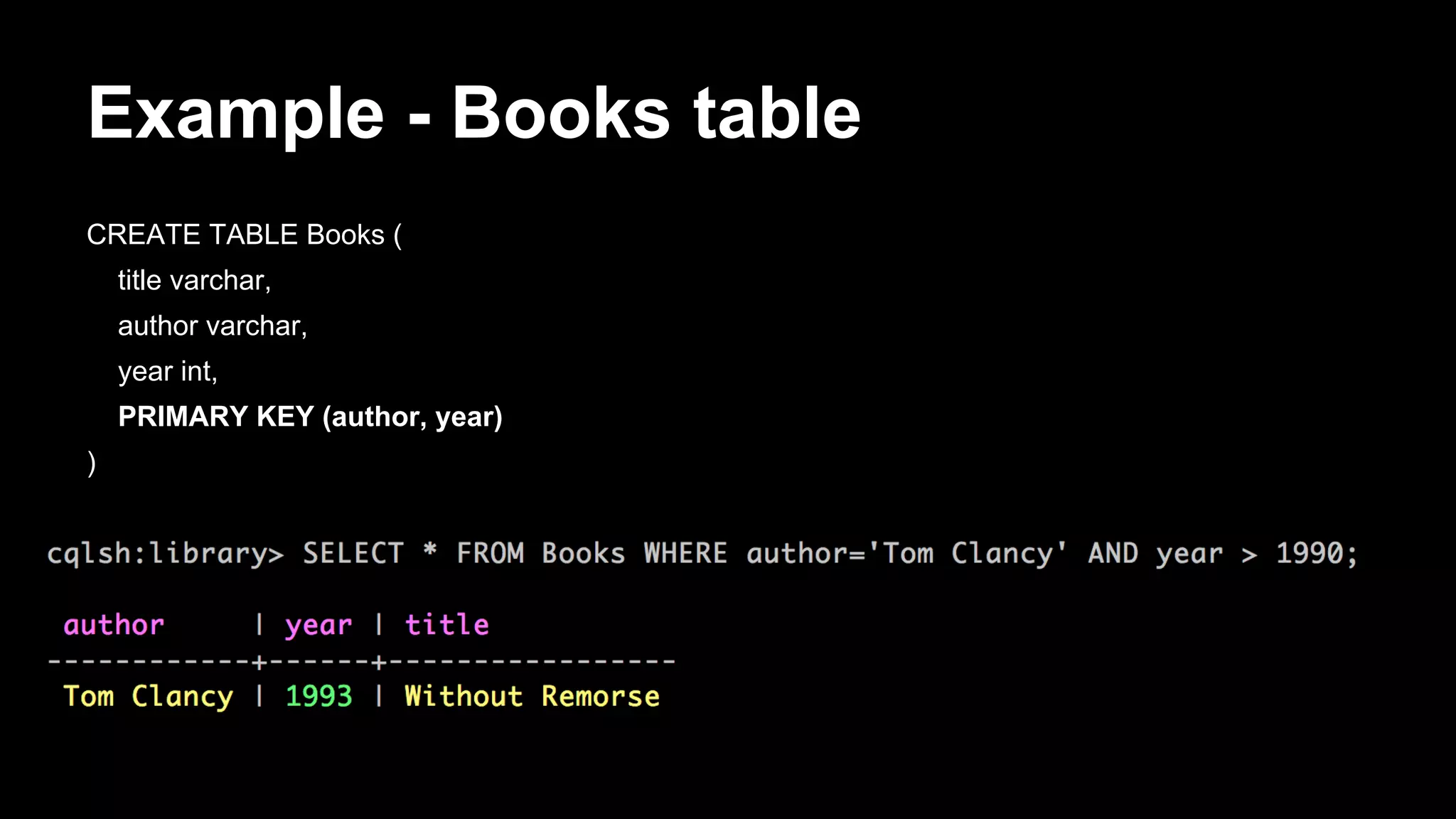
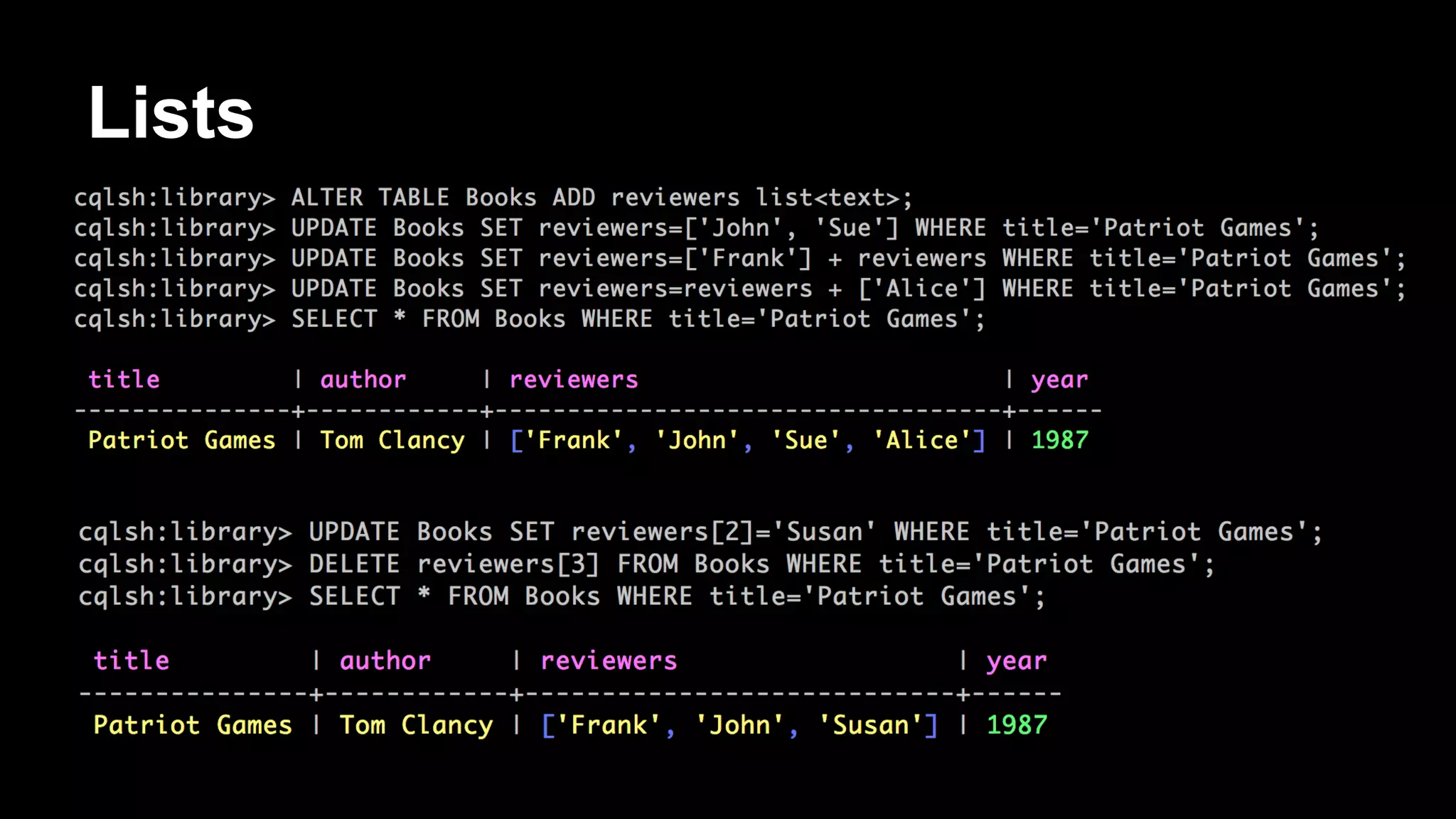
[default@unknown] create keyspace Library;
[default@unknown] use Library;
[default@Library] create column family Books
...
with comparator=UTF8Type
...
and key_validation_class=UTF8Type
…
and default_validation_class=UTF8Type;
[default@Library] set Books['Patriot Games']['author'] = 'Tom Clancy';
[default@Library] set Books['Patriot Games']['year'] = '1987';
[default@Library] list Books;
RowKey: Patriot Games
=> (name=author, value=Tom Clancy, timestamp=1393102991499000)
=> (name=year, value=1987, timestamp=1393103015955000)](https://image.slidesharecdn.com/bigdatagrowsupdevnexus-140225120726-phpapp02/75/Big-Data-Grows-Up-A-re-introduction-to-Cassandra-34-2048.jpg)
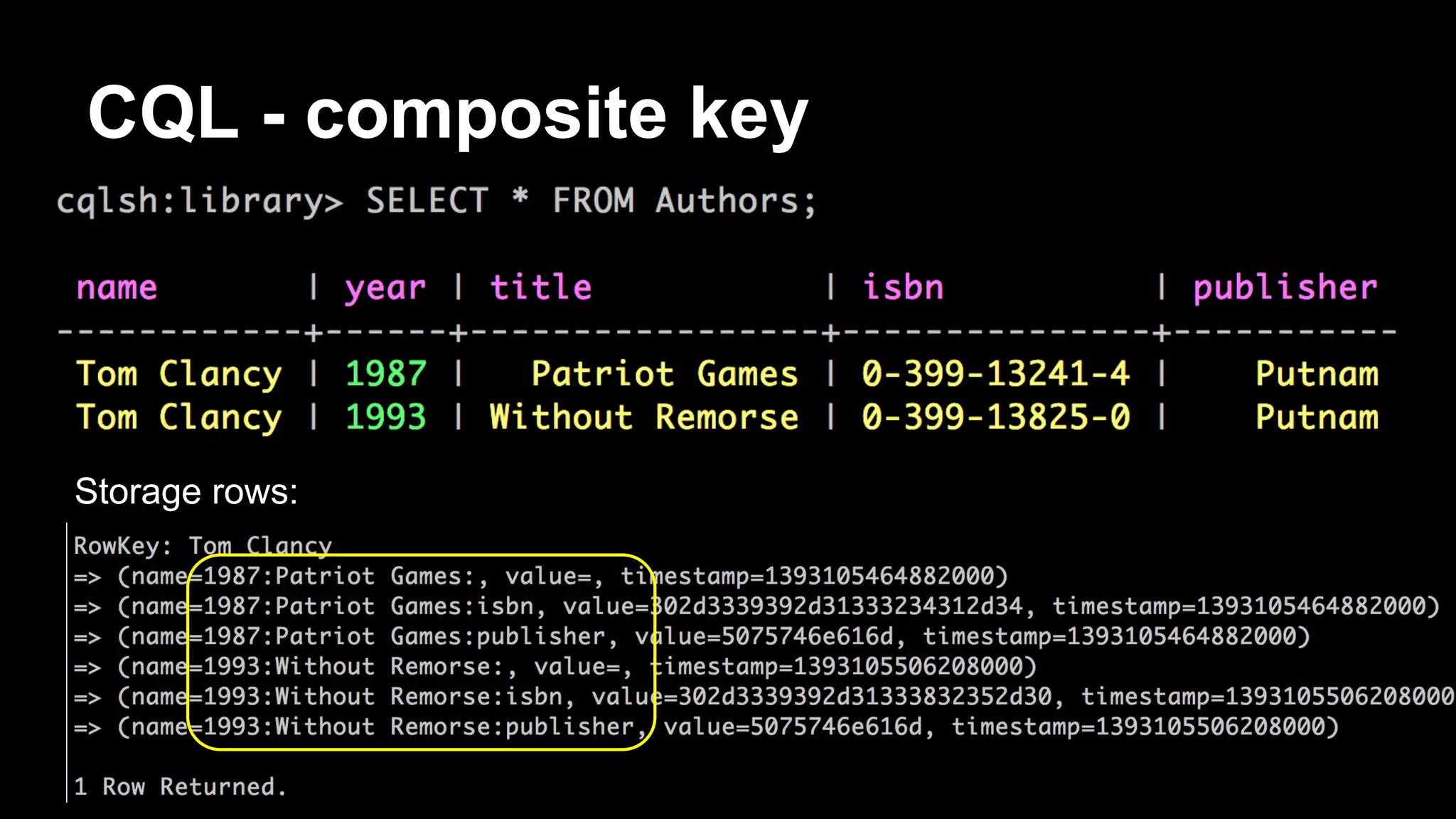
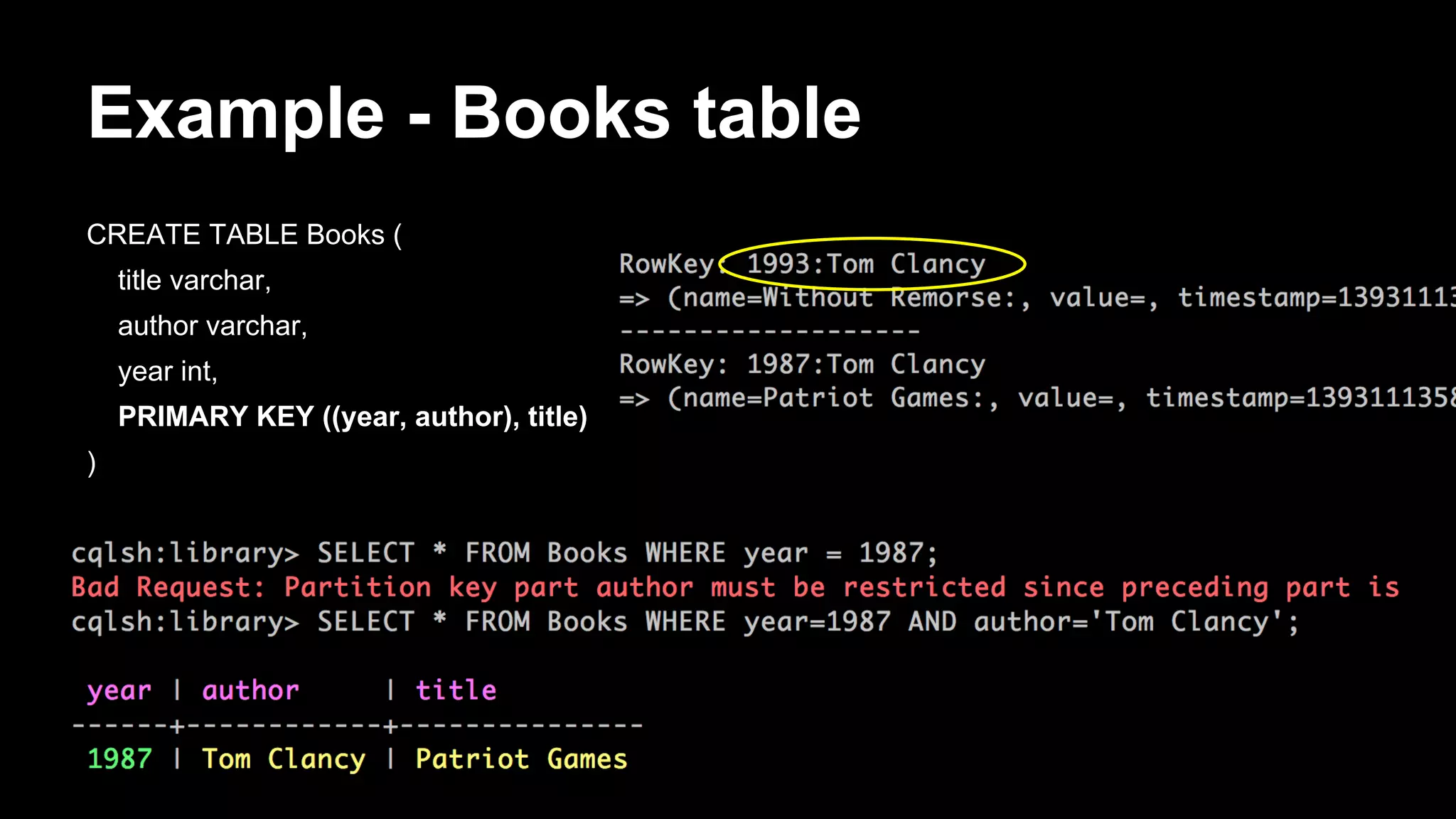
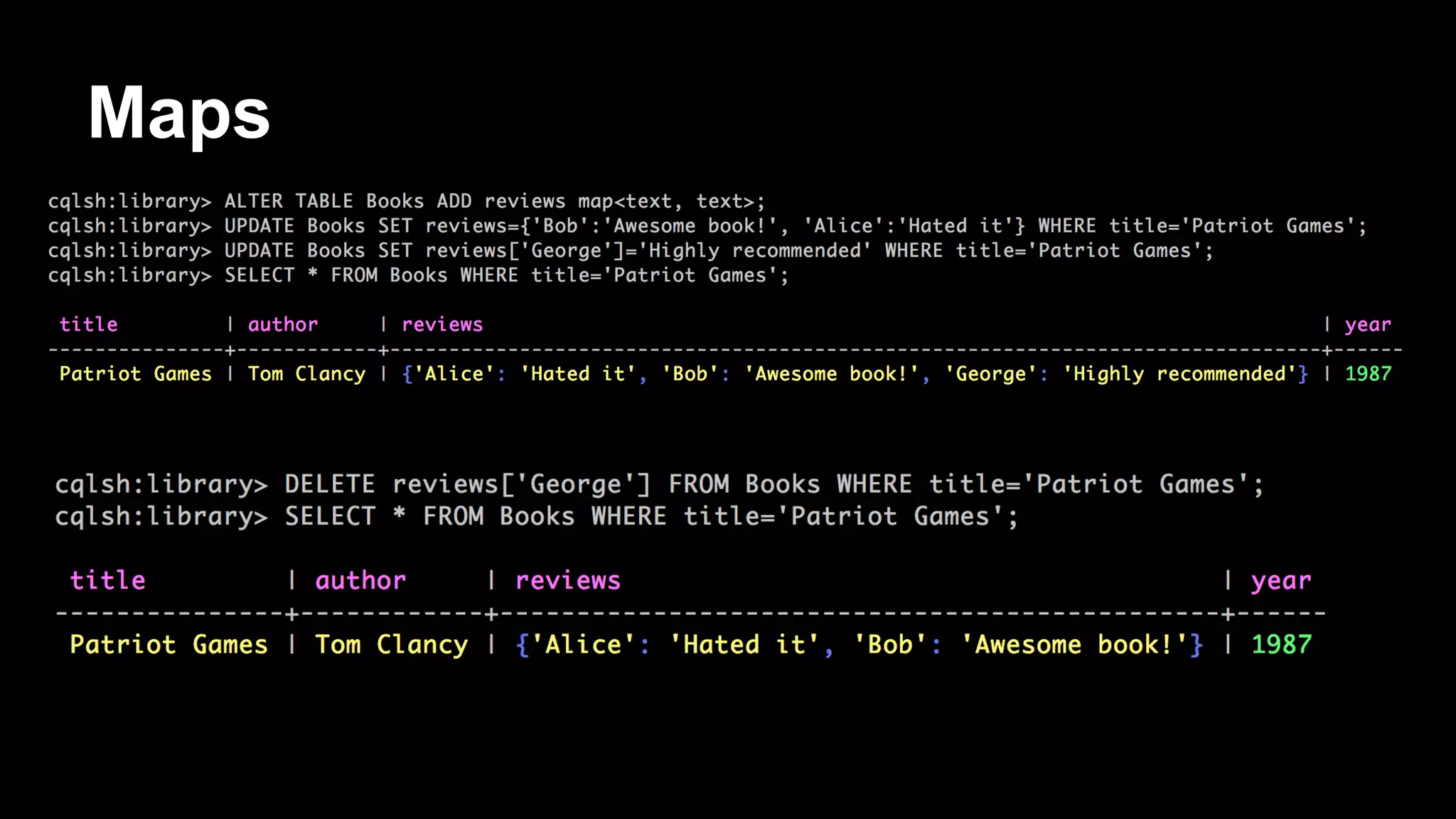
![Storage rows - composites
[default@Library] create column family Authors
...
with key_validation_class=UTF8Type
...
and comparator='CompositeType(LongType,UTF8Type,UTF8Type)'
...
and default_validation_class=UTF8Type;
[default@Library] set Authors['Tom Clancy']['1987:Patriot Games:publisher'] = 'Putnam';
[default@Library] set Authors['Tom Clancy']['1987:Patriot Games:ISBN'] = '0-399-13241-4';
[default@Library] set Authors['Tom Clancy']['1993:Without Remorse:publisher'] = 'Putnam';
[default@Library] set Authors['Tom Clancy']['1993:Without Remorse:ISBN'] = '0-399-13825-0';
[default@Library] list Authors;
RowKey: Tom Clancy
=> (name=1987:Patriot Games:ISBN, value=0-399-13241-4, timestamp=1393104011458000)
=> (name=1987:Patriot Games:publisher, value=Putnam, timestamp=1393103948577000)
=> (name=1993:Without Remorse:ISBN, value=0-399-13825-0, timestamp=1393104109214000)
=> (name=1993:Without Remorse:publisher, value=Putnam, timestamp=1393104083773000)](https://image.slidesharecdn.com/bigdatagrowsupdevnexus-140225120726-phpapp02/75/Big-Data-Grows-Up-A-re-introduction-to-Cassandra-35-2048.jpg)




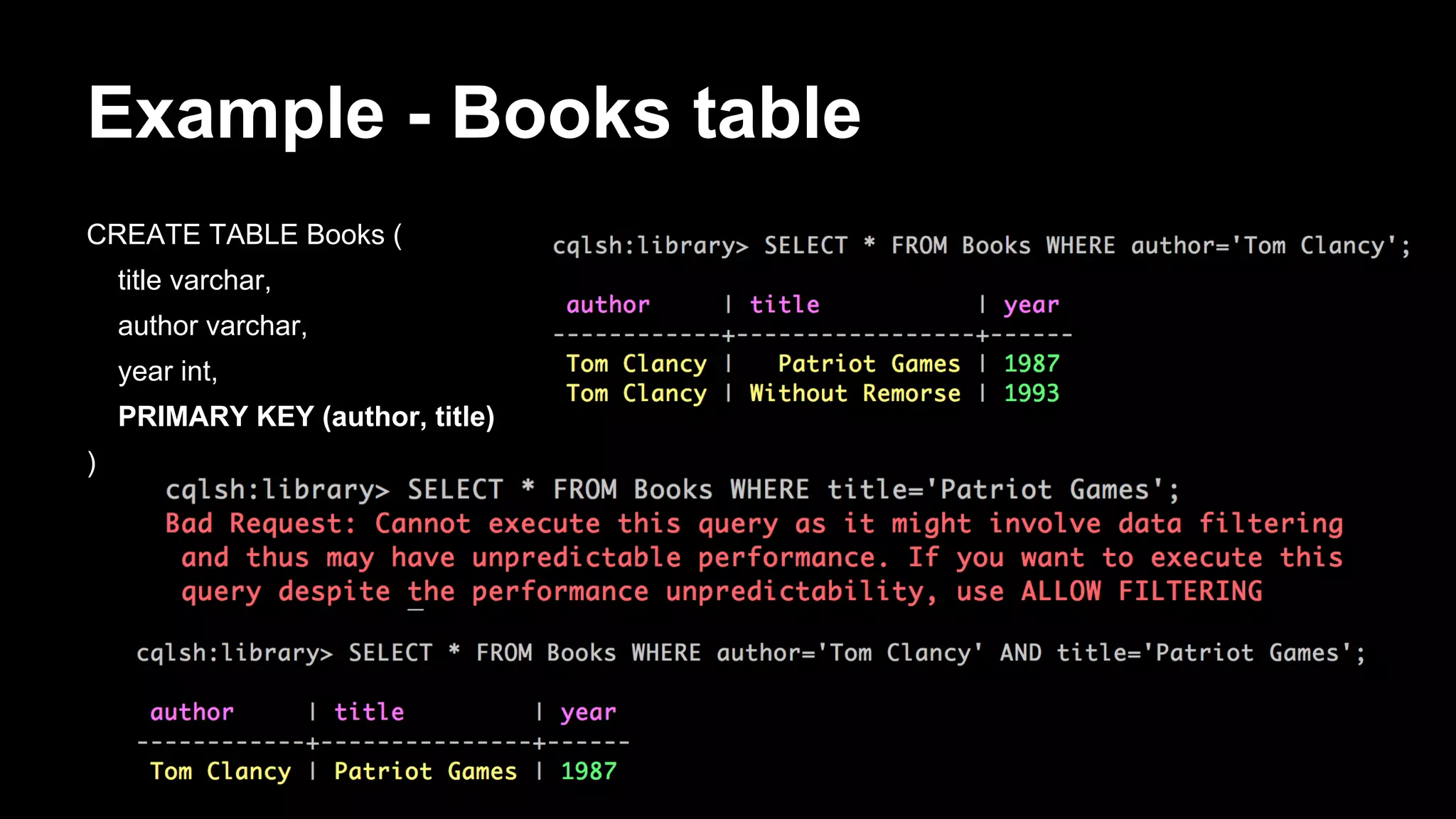








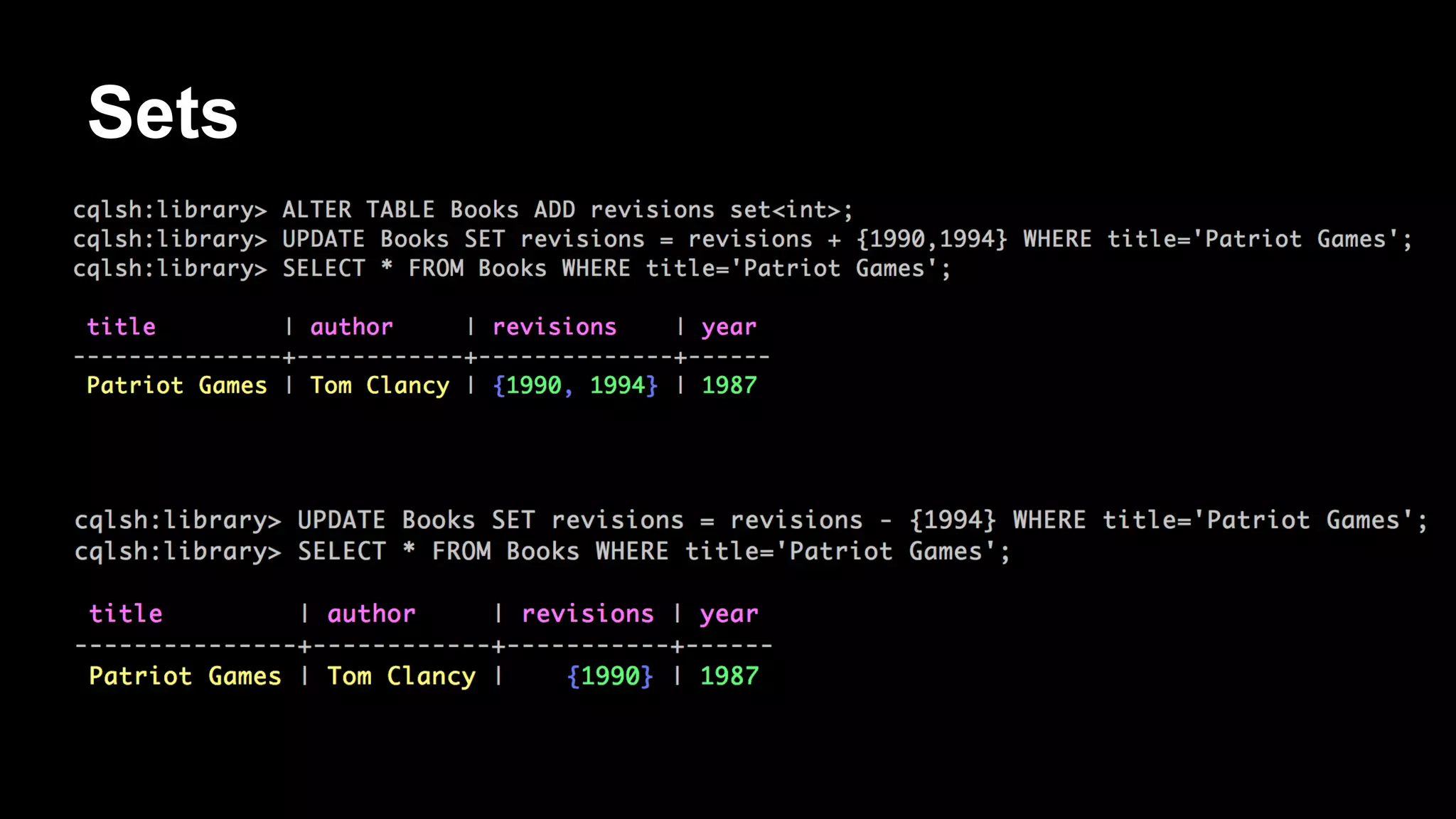
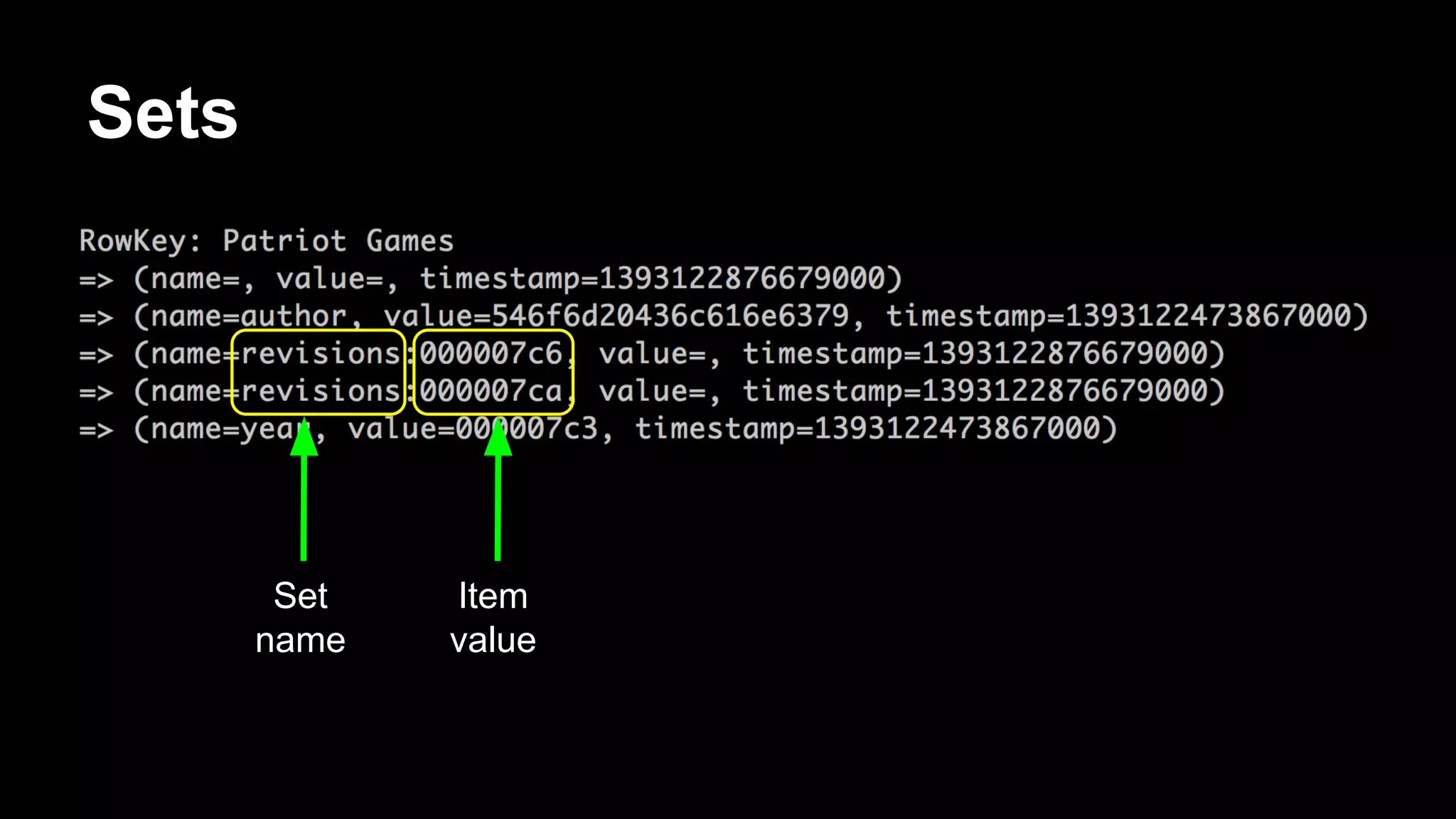

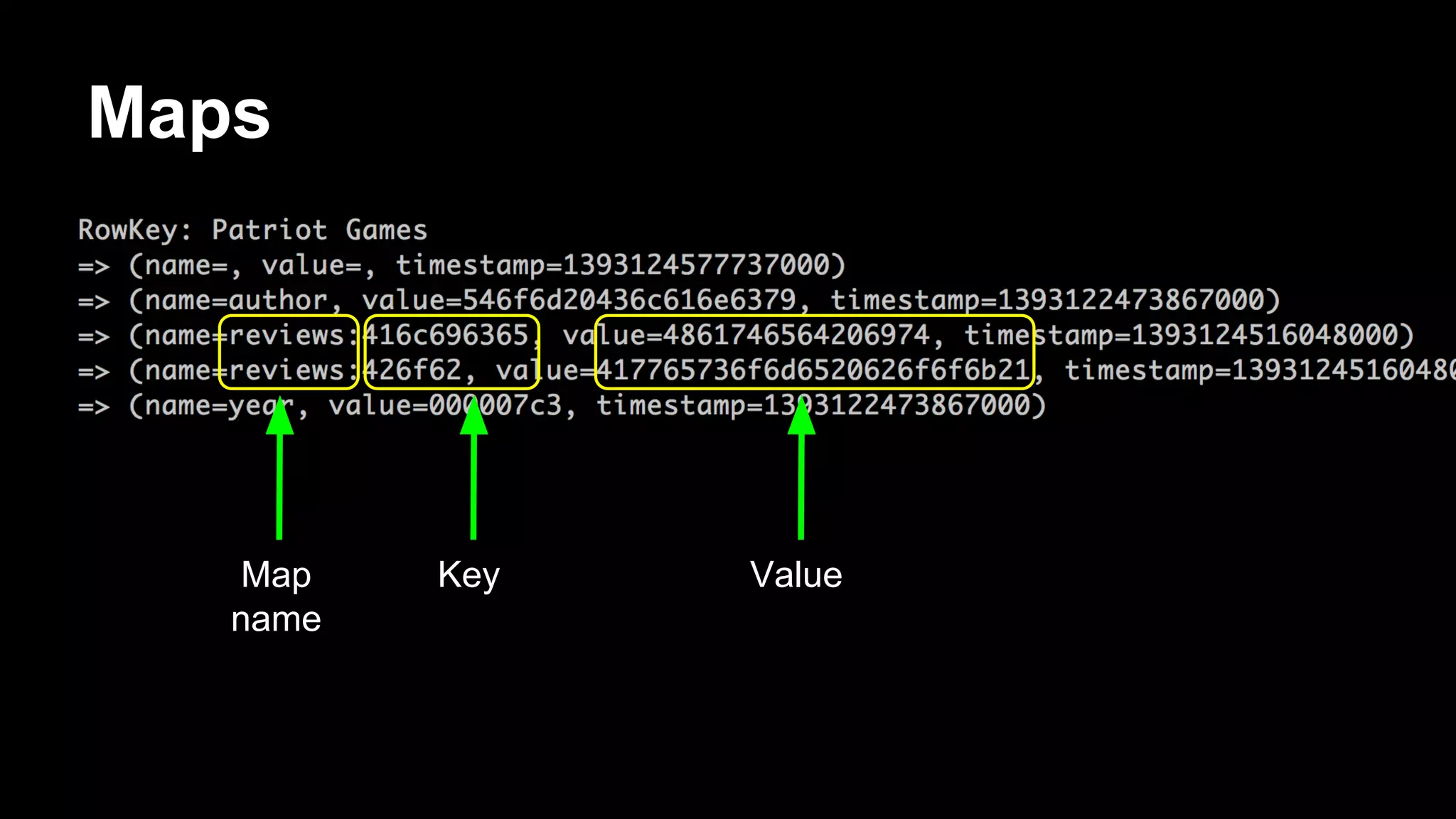


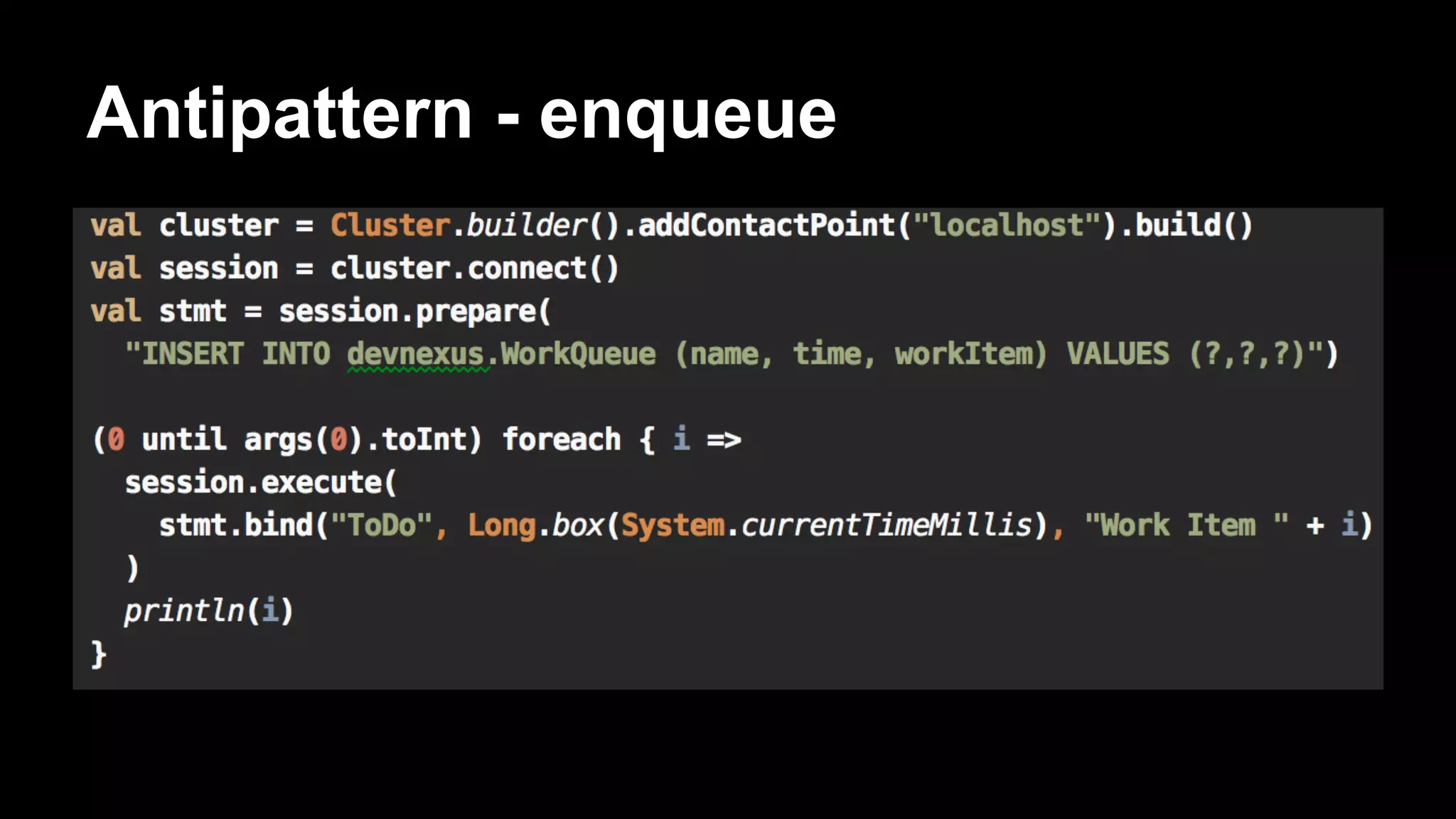
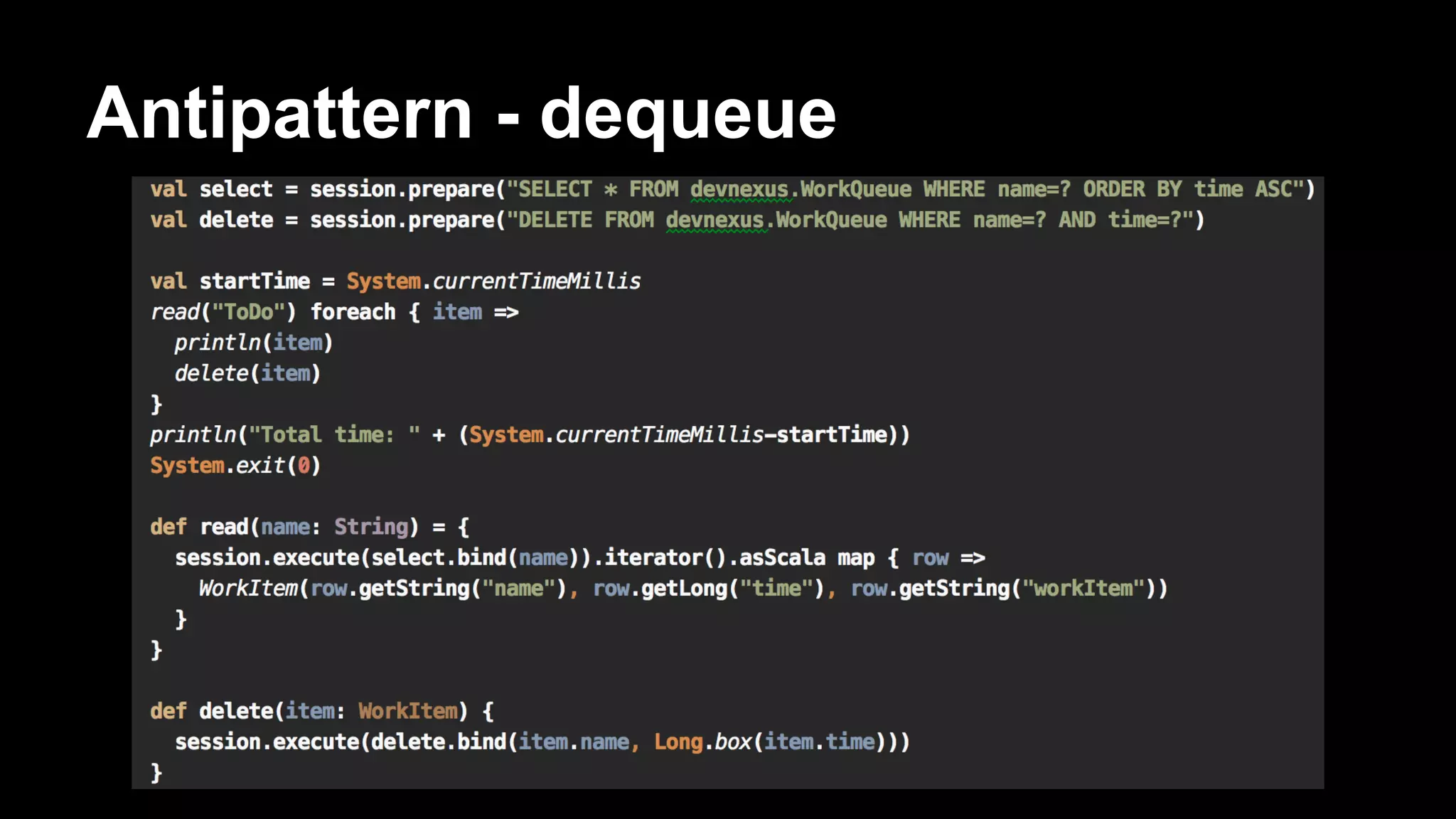
![Antipattern
CREATE TABLE WorkQueue (
name varchar,
time bigint,
workItem varchar,
PRIMARY KEY (name, time)
)
… do a bunch of inserts ...
SELECT * FROM WorkQueue WHERE name='ToDo' ORDER BY time ASC;
DELETE FROM WorkQueue WHERE name=’ToDo’ AND time=[some_time]](https://image.slidesharecdn.com/bigdatagrowsupdevnexus-140225120726-phpapp02/75/Big-Data-Grows-Up-A-re-introduction-to-Cassandra-62-2048.jpg)






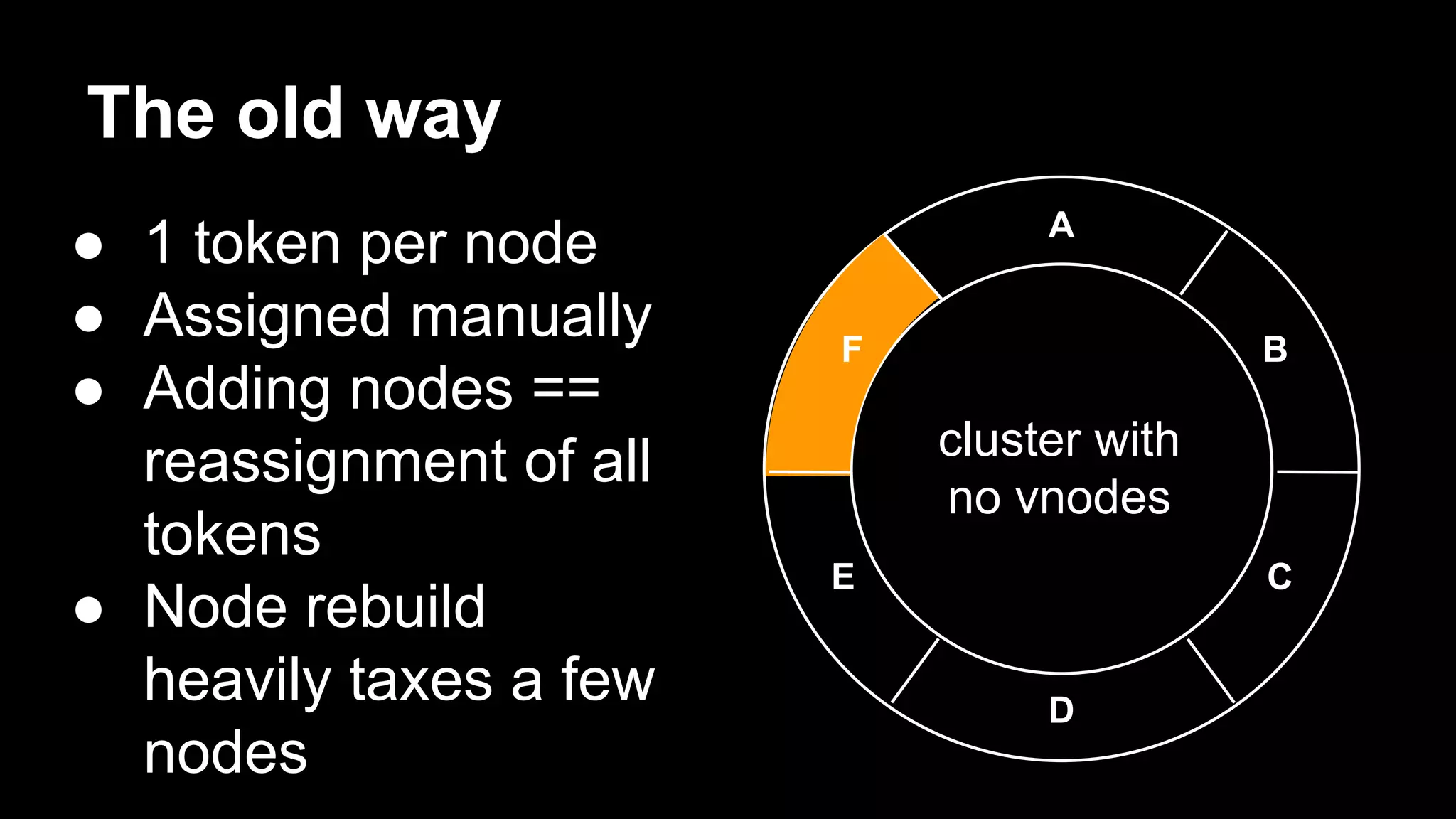
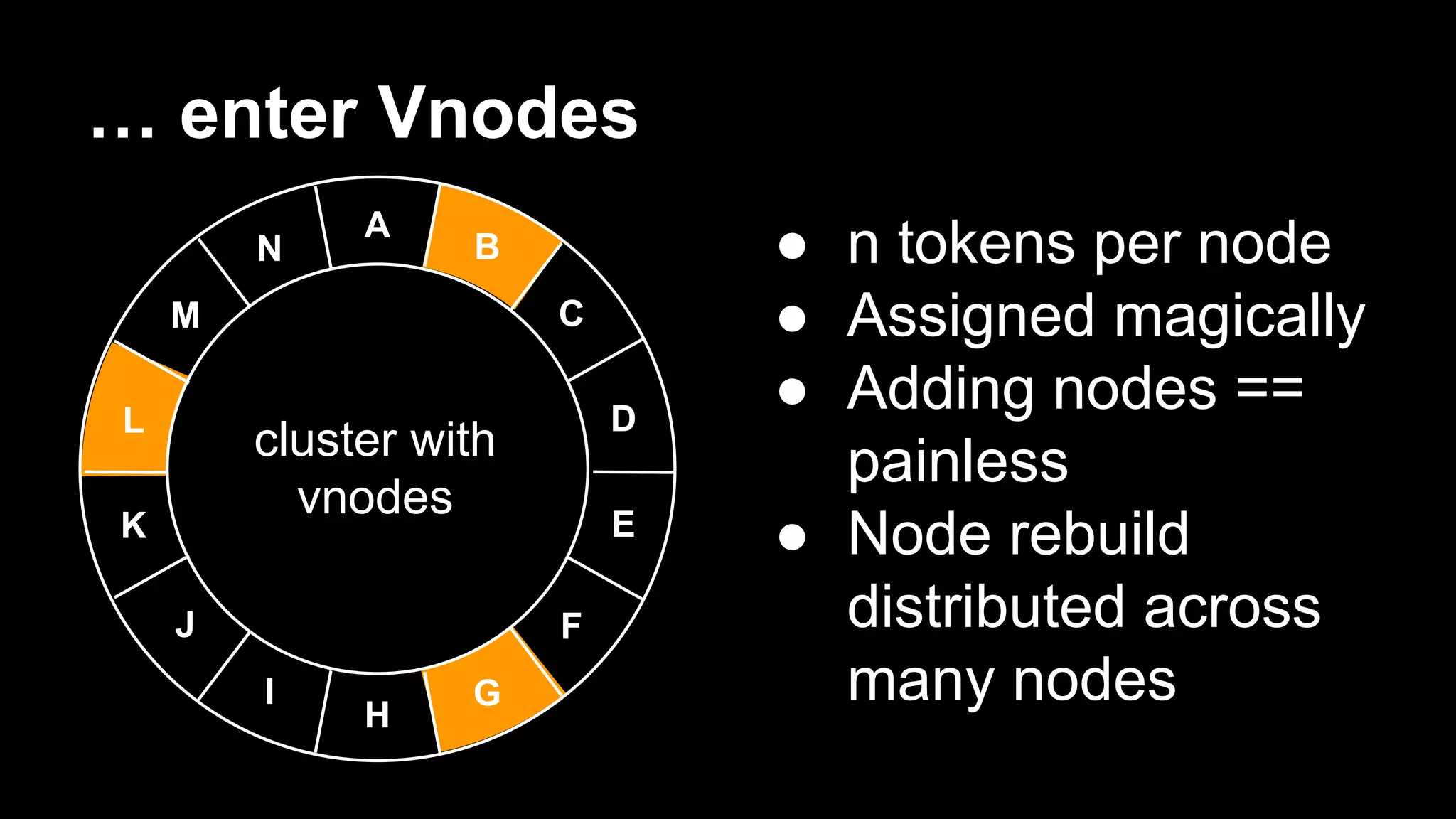
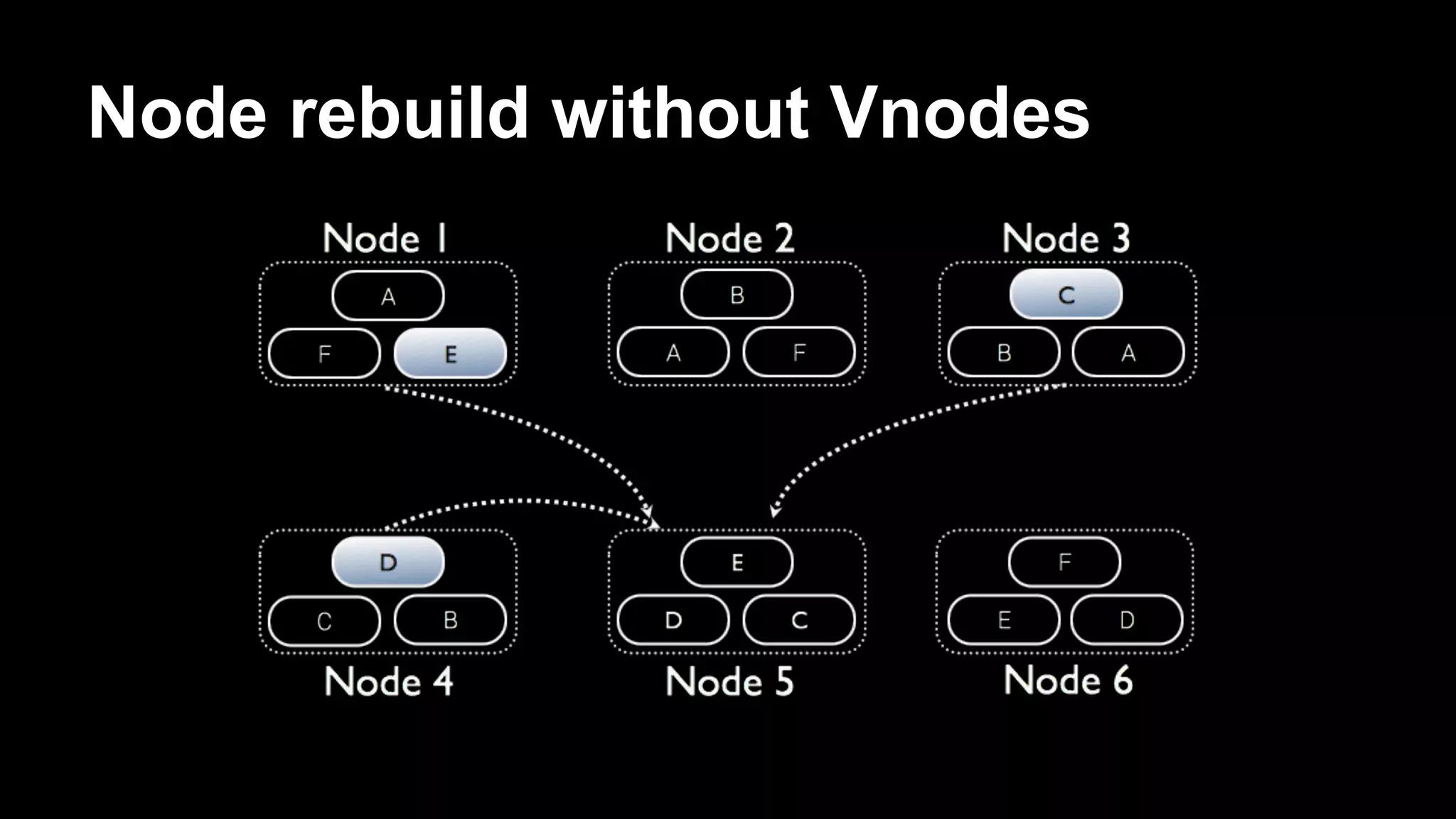
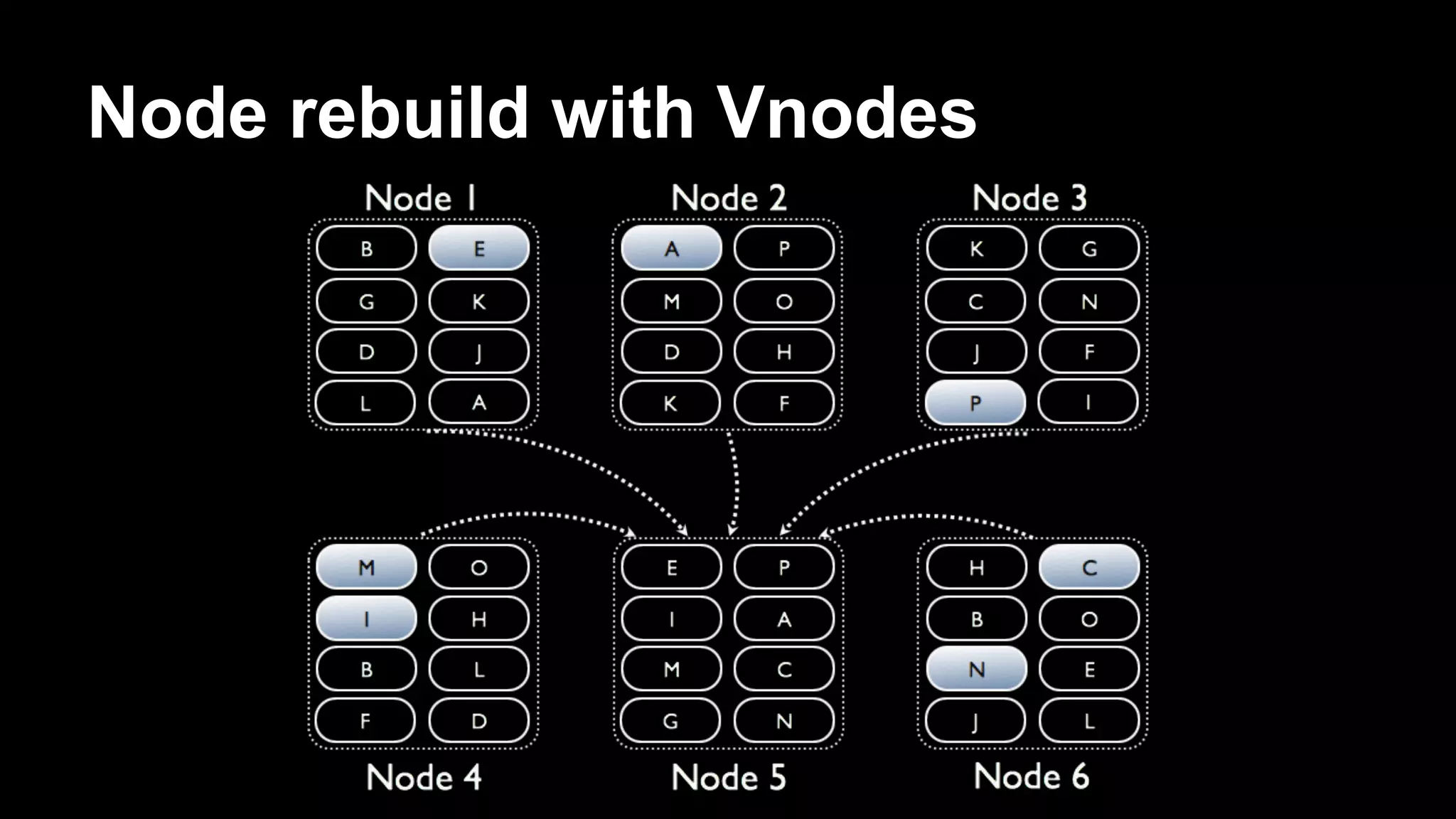
Robbie Strickland provides an overview of Apache Cassandra, highlighting its speed, scalability, and fault tolerance as key advantages. The document discusses recent advancements in Cassandra, including virtual nodes, the native protocol, and the Cassandra Query Language (CQL), which makes the database more user-friendly while retaining its core principles. Strickland also addresses the challenges of managing data in Cassandra and offers insights on best practices for implementing the system.


























































![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)







![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)
