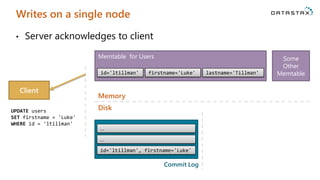
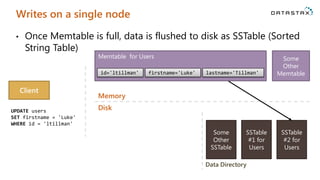
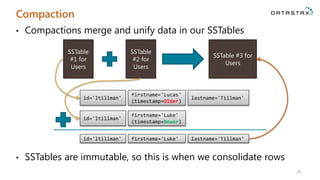
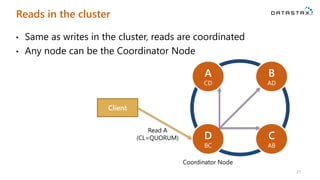
Download as PDF, PPTX
































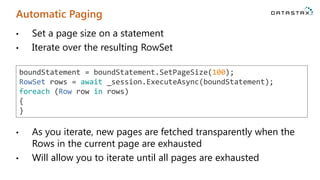
![Lightweight Transactions (LWT)
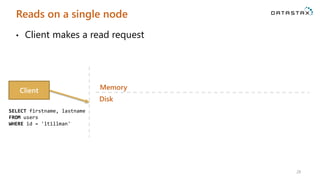
• Returns a column called [applied] indicating success/failure
• Different from the relational world where you might expect an
Exception (i.e. PrimaryKeyViolationException or similar)
var statement = new SimpleStatement("INSERT INTO user_credentials (email,
password) VALUES (?, ?) IF NOT EXISTS");
statement = statement.Bind("user1@killrvideo.com", "Password1!");
RowSet rows = await _session.ExecuteAsync(statement);
var userInserted = rows.Single().GetValue<bool>("[applied]");](https://image.slidesharecdn.com/deepdivefornetdevelopers-141119173359-conversion-gate01/85/A-Deep-Dive-into-Apache-Cassandra-for-NET-Developers-64-320.jpg)



![.NET and Cassandra
• Mapping results to DTOs: if you like LINQ, use built-in LINQ
provider
[Table("users")]
public class User
{
[Column("userid"), PartitionKey]
public Guid UserId { get; set; }
[Column("name")]
public string Name { get; set; }
}
var user = session.GetTable<User>()
.SingleOrDefault(u => u.UserId == someUserId)
.Execute();
70](https://image.slidesharecdn.com/deepdivefornetdevelopers-141119173359-conversion-gate01/85/A-Deep-Dive-into-Apache-Cassandra-for-NET-Developers-70-320.jpg)















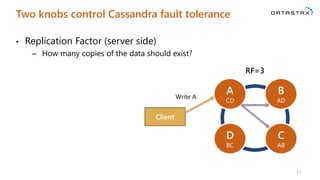
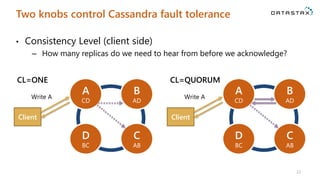
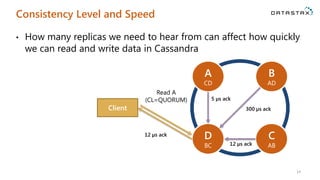
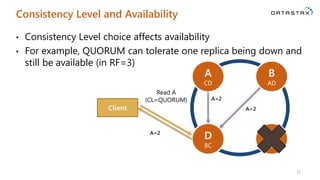
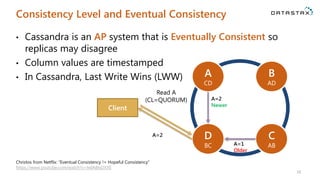
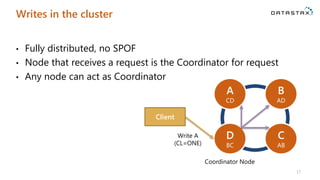
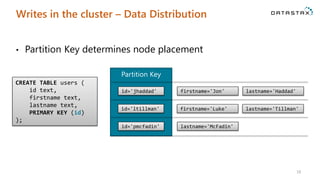
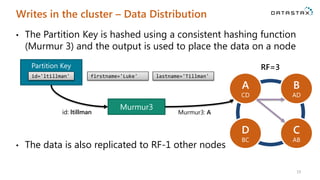
The document is a comprehensive guide on Apache Cassandra tailored for .NET developers, covering its core principles like ease of use, scalability, and fault tolerance. It explains Cassandra's architecture, data modeling strategies, consistency levels, and how .NET developers can integrate and utilize the Cassandra database effectively through its .NET driver. Key concepts such as the CAP theorem, partition keys, and data structure definitions are discussed in detail to provide insights into best practices for building applications with Cassandra.


















































































