Downloaded 39 times







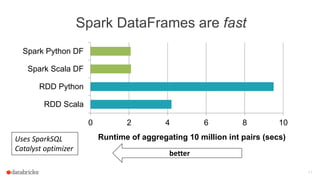



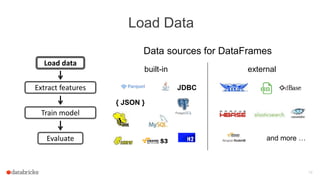
![Extract Features
22
Train model
Evaluate
Load data
label: Int
text: String
Current data schema
Tokenizer
Hashed Term Freq.
features: Vector
words: Seq[String]
Transformer](https://image.slidesharecdn.com/josephbradley-dataframesandpipelines-150426220630-conversion-gate02/85/Joseph-Bradley-Software-Engineer-Databricks-Inc-at-MLconf-SEA-5-01-15-22-320.jpg)
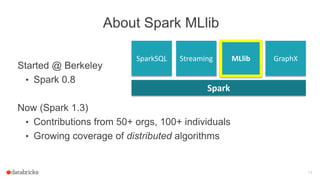
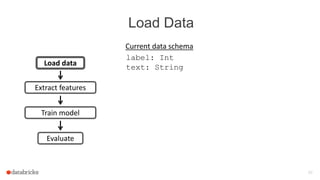
![Train a Model
23
Logistic Regression
Evaluate
label: Int
text: String
Current data schema
Tokenizer
Hashed Term Freq.
features: Vector
words: Seq[String]
prediction: Int
Estimator
Load data
Transformer](https://image.slidesharecdn.com/josephbradley-dataframesandpipelines-150426220630-conversion-gate02/85/Joseph-Bradley-Software-Engineer-Databricks-Inc-at-MLconf-SEA-5-01-15-23-320.jpg)
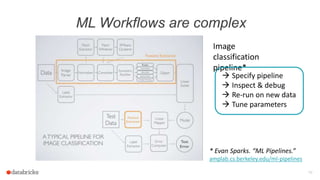
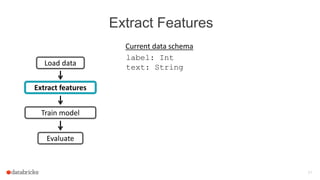
![Evaluate the Model
24
Logistic Regression
Evaluate
label: Int
text: String
Current data schema
Tokenizer
Hashed Term Freq.
features: Vector
words: Seq[String]
prediction: Int
Load data
Transformer
Evaluator
Estimator
By default, always
append new columns
Can go back & inspect
intermediate results
Made efficient by
DataFrame
optimizations](https://image.slidesharecdn.com/josephbradley-dataframesandpipelines-150426220630-conversion-gate02/85/Joseph-Bradley-Software-Engineer-Databricks-Inc-at-MLconf-SEA-5-01-15-24-320.jpg)
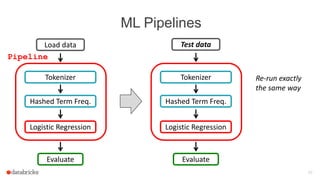
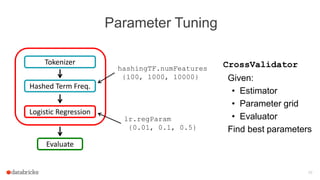


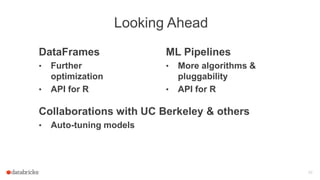


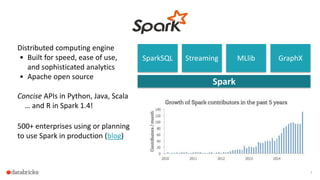
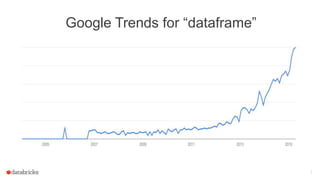
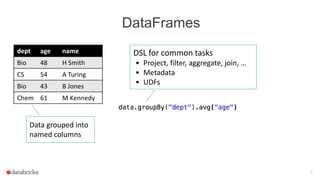
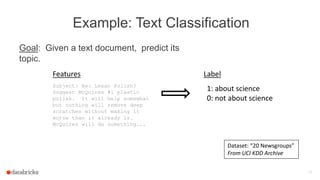
The document discusses Apache Spark's dataframes and machine learning pipelines, highlighting their ease of use and speed in handling structured data. It outlines the API inspiration from R and Python's Pandas, the functionalities of dataframes, and various machine learning algorithms available in Spark's MLlib. The presentation emphasizes the integration of dataframes with machine learning workflows, including model training, evaluation, and parameter tuning.











































































































