Download as PDF, PPTX



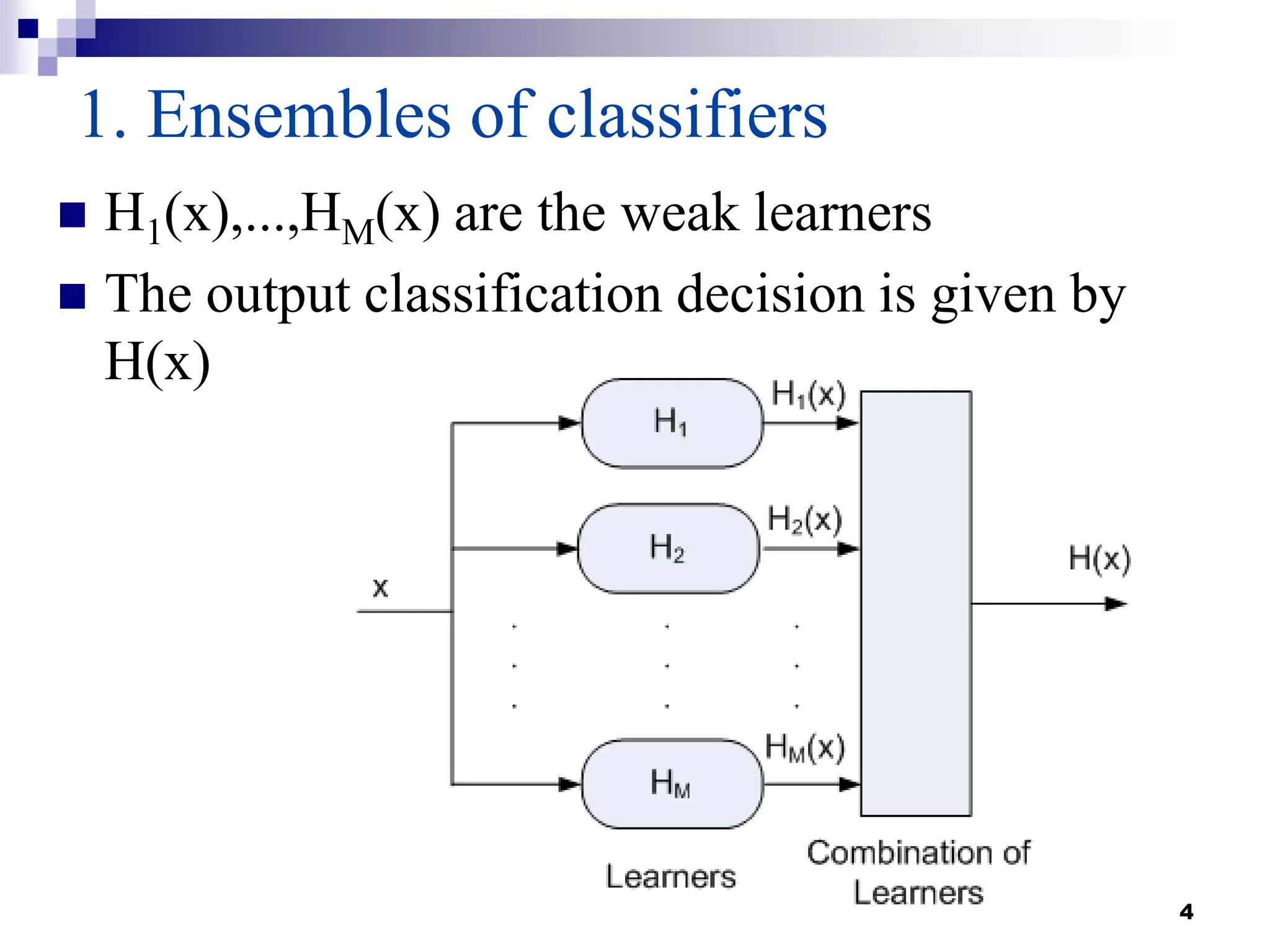
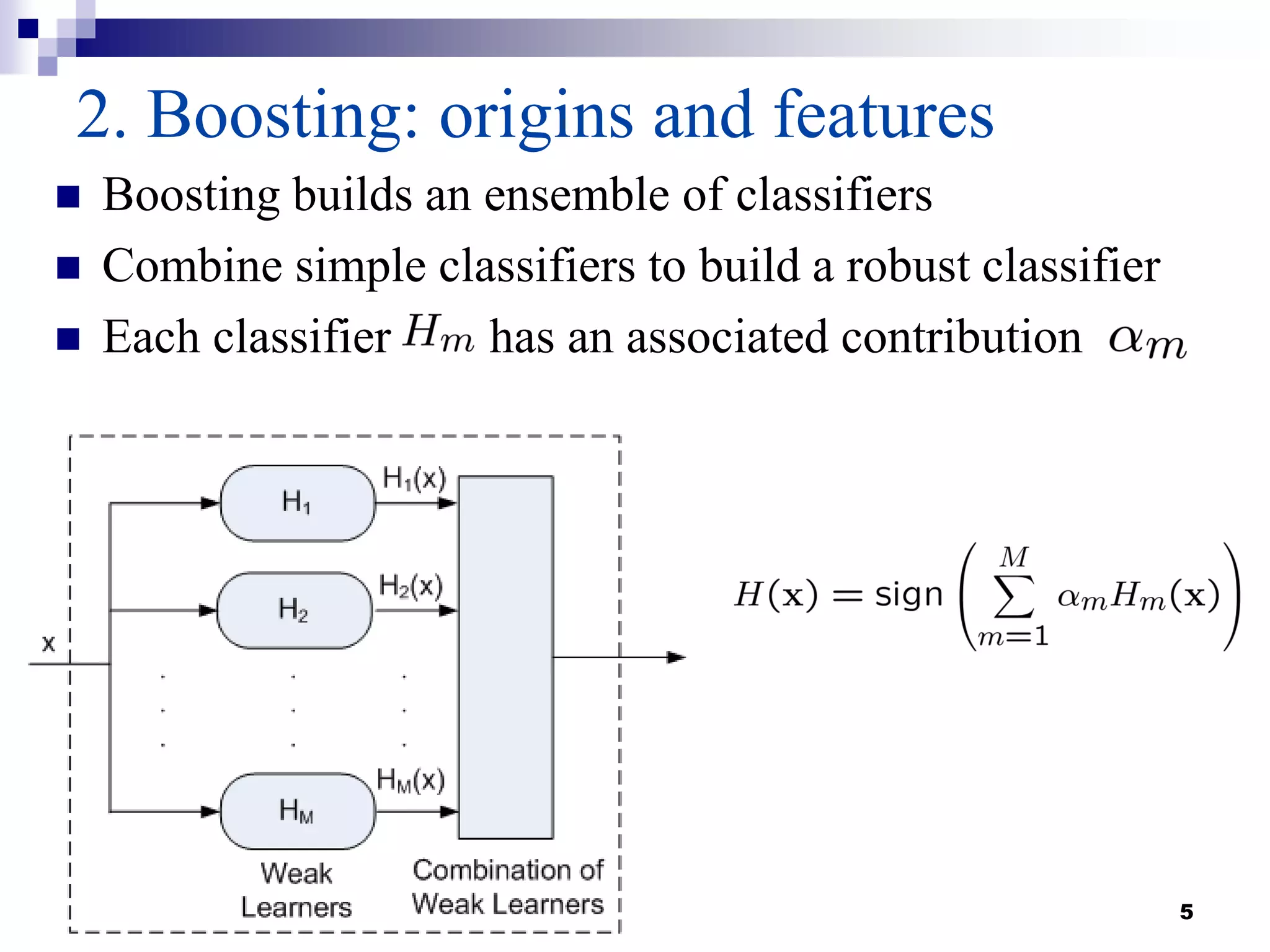


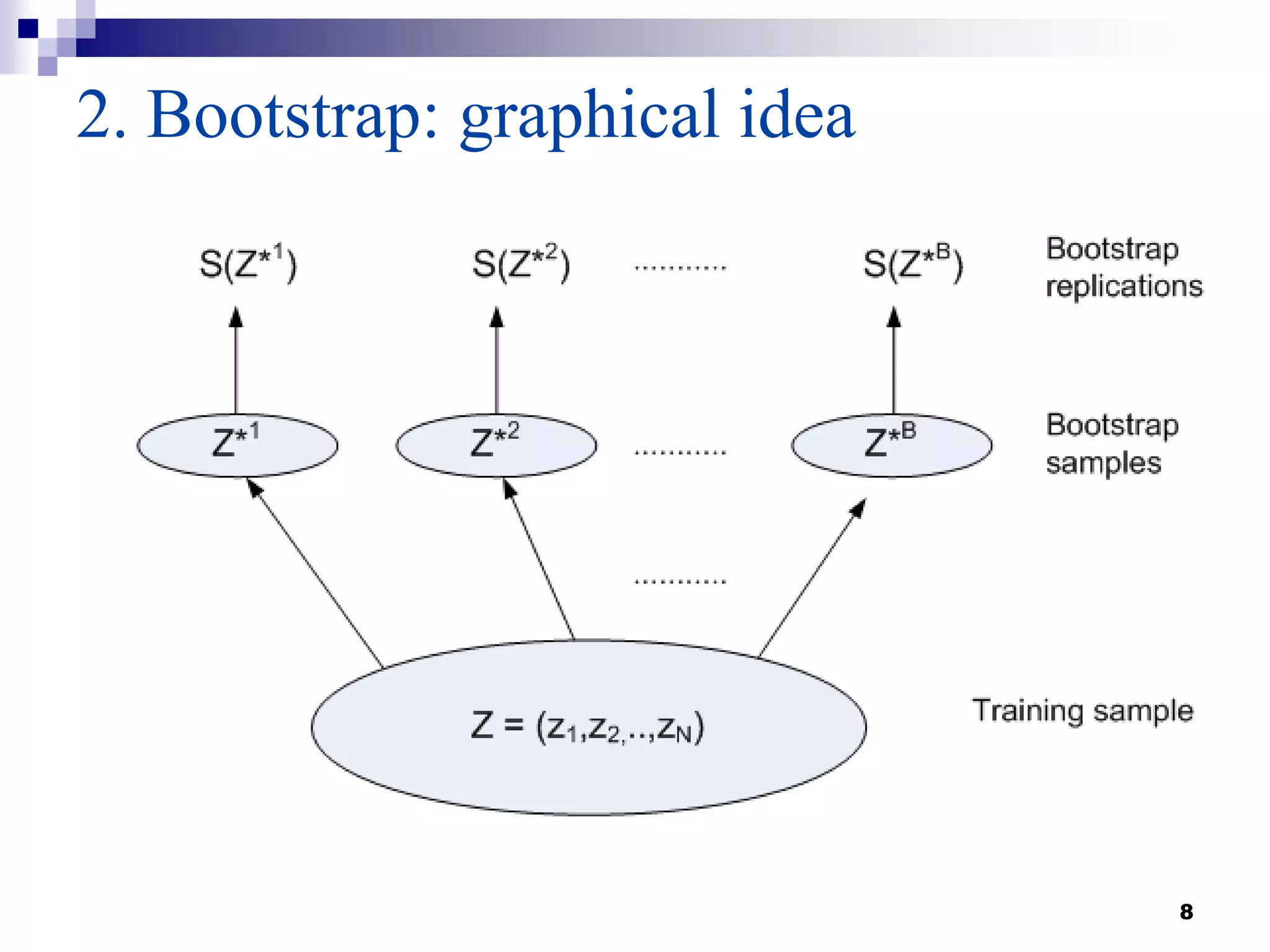





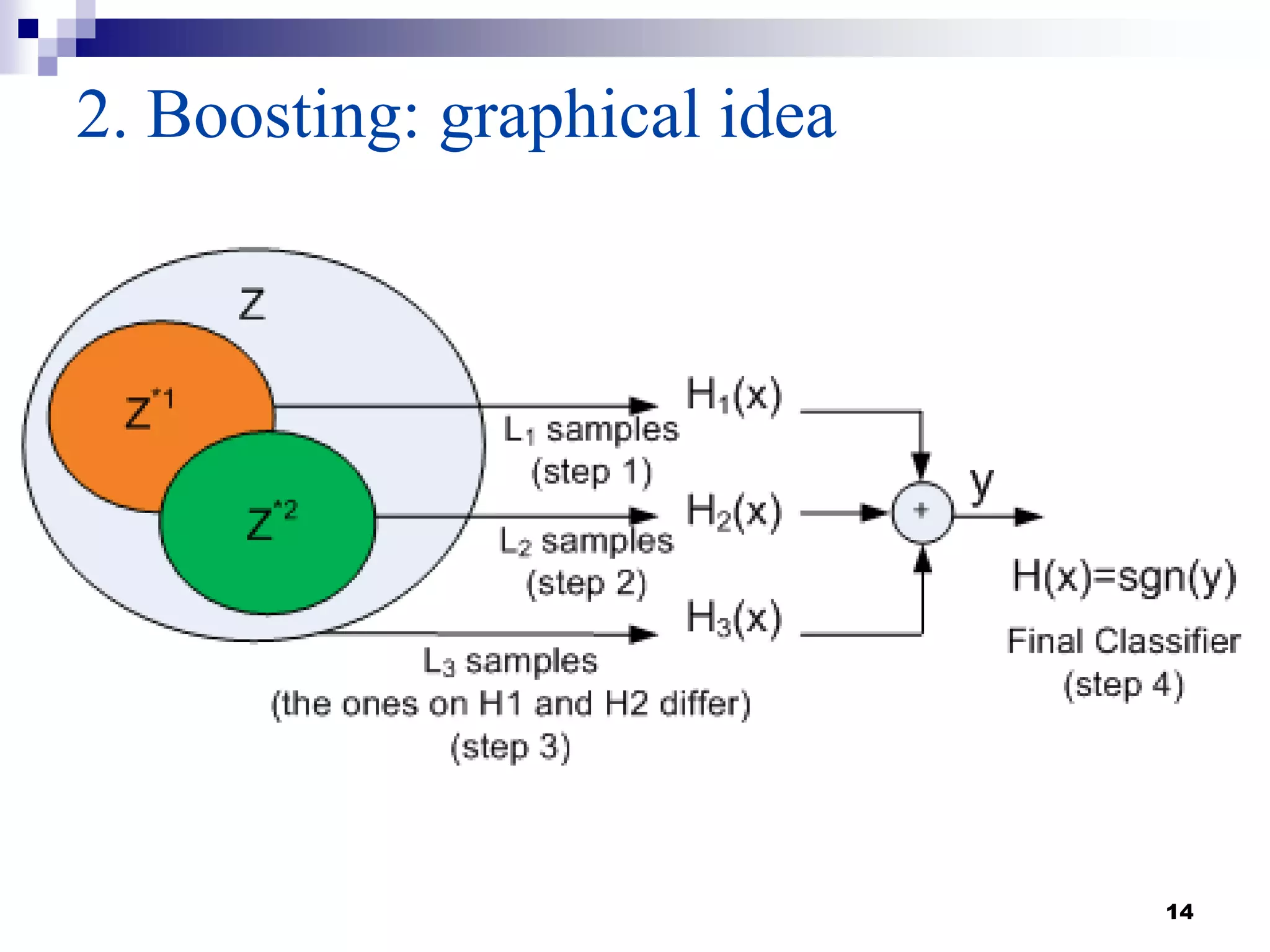

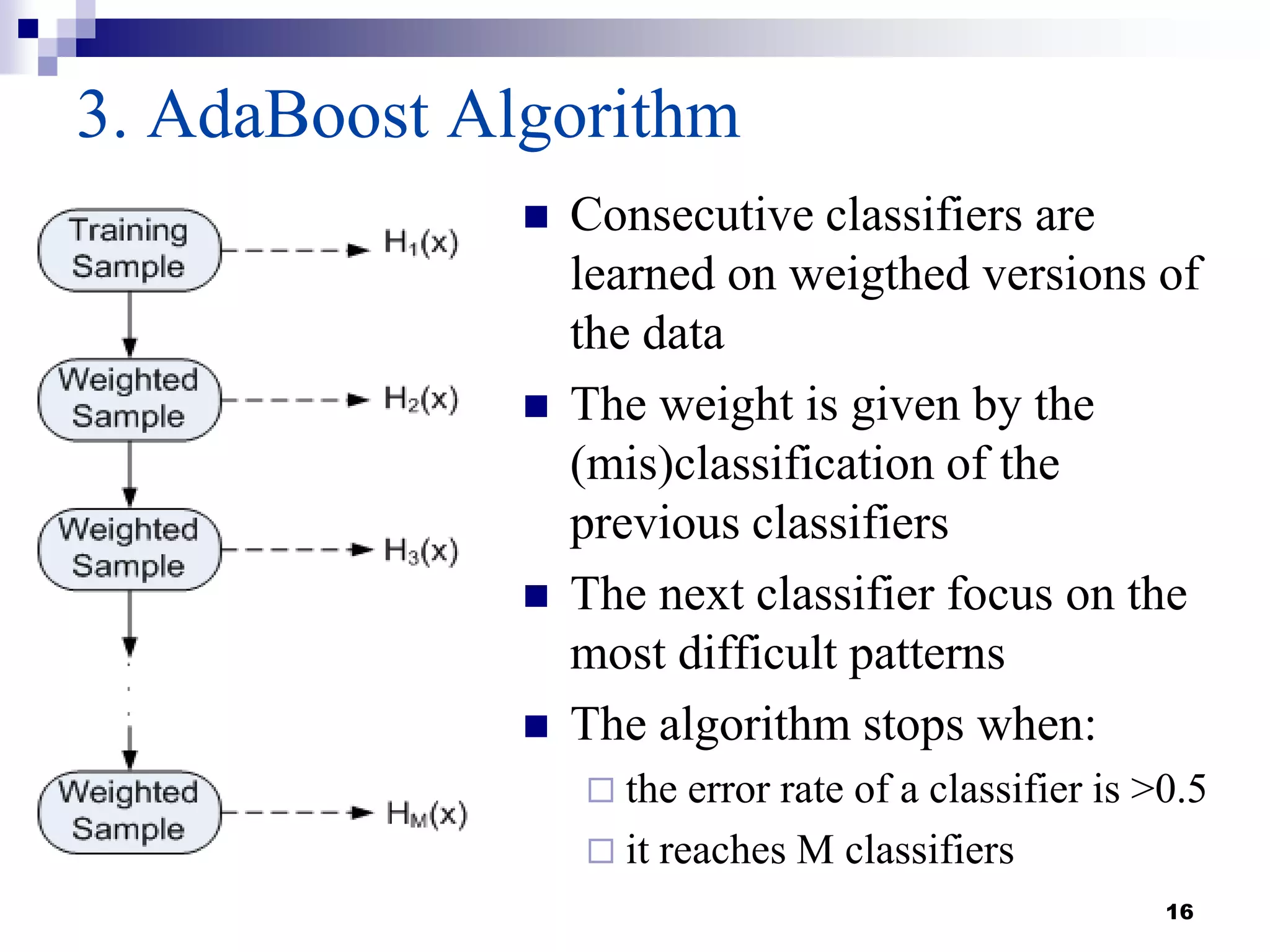

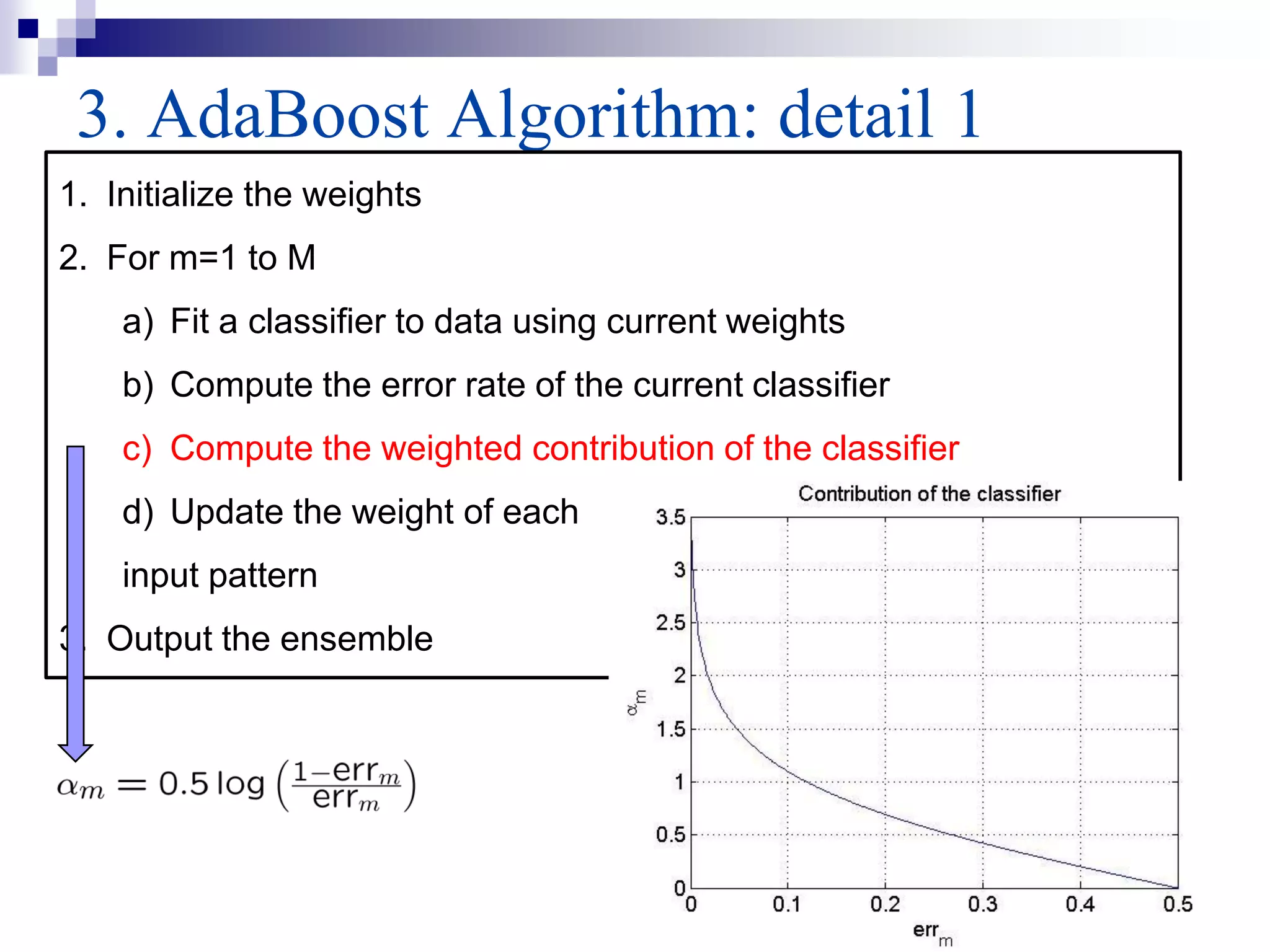


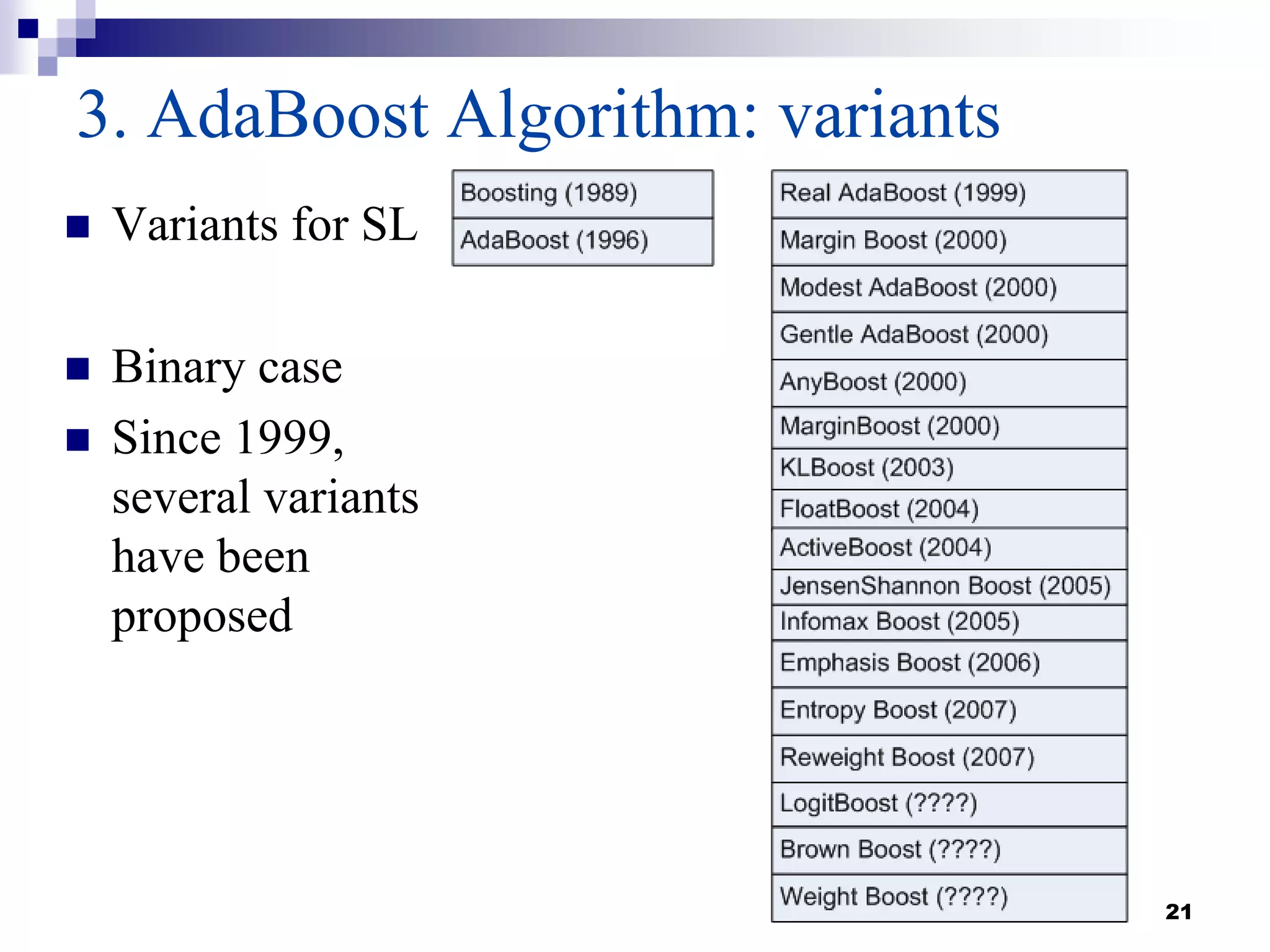











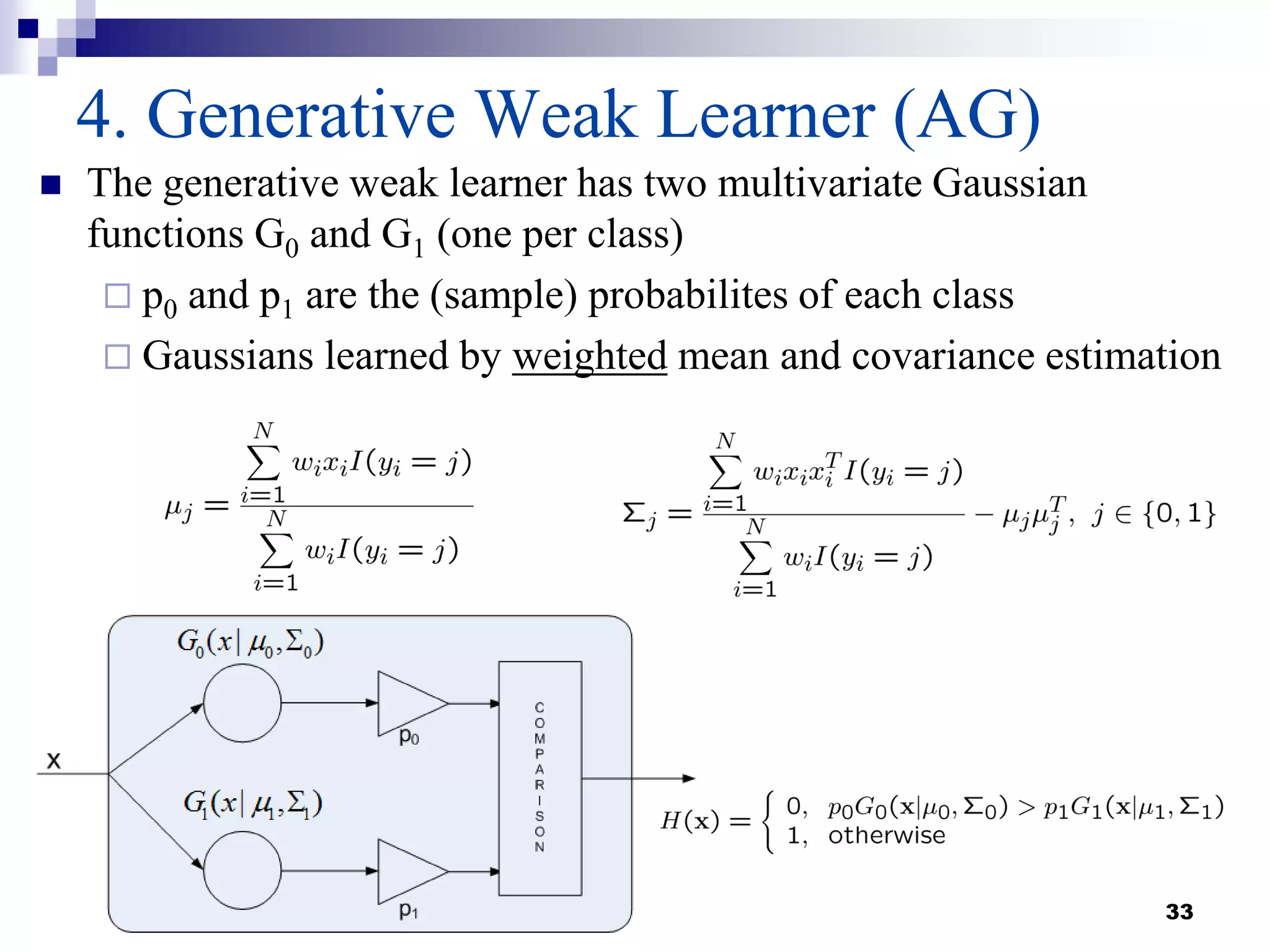
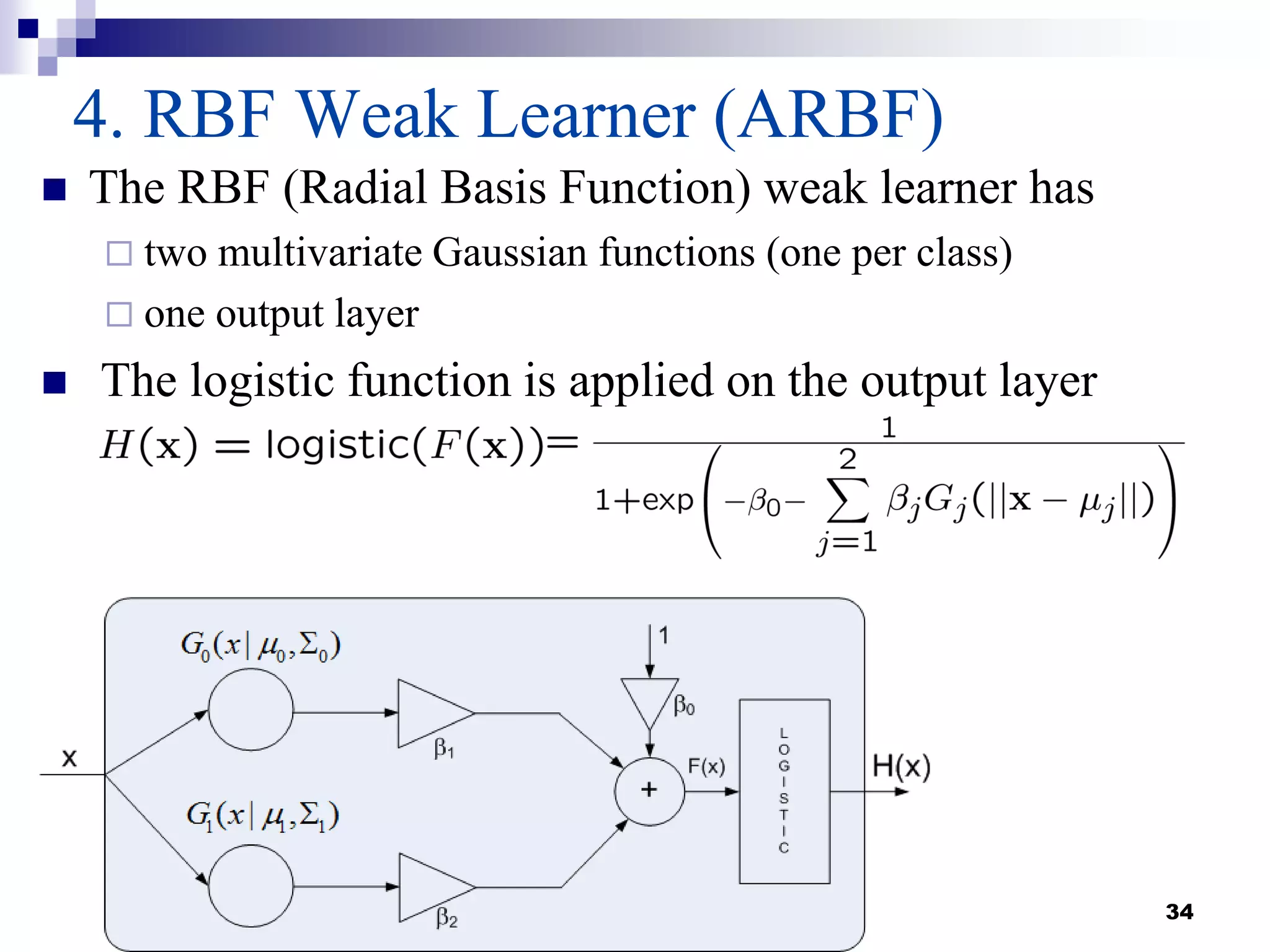

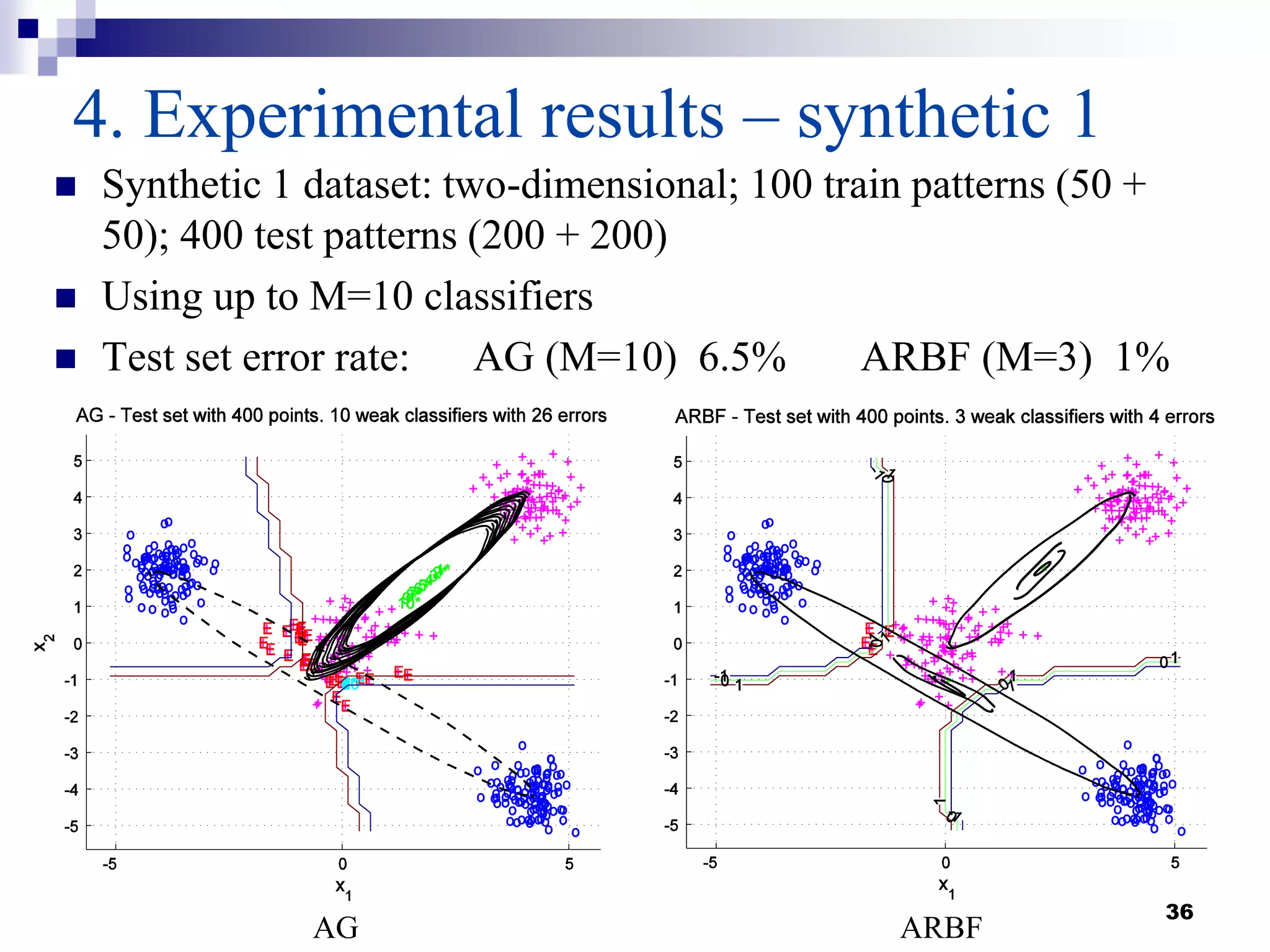
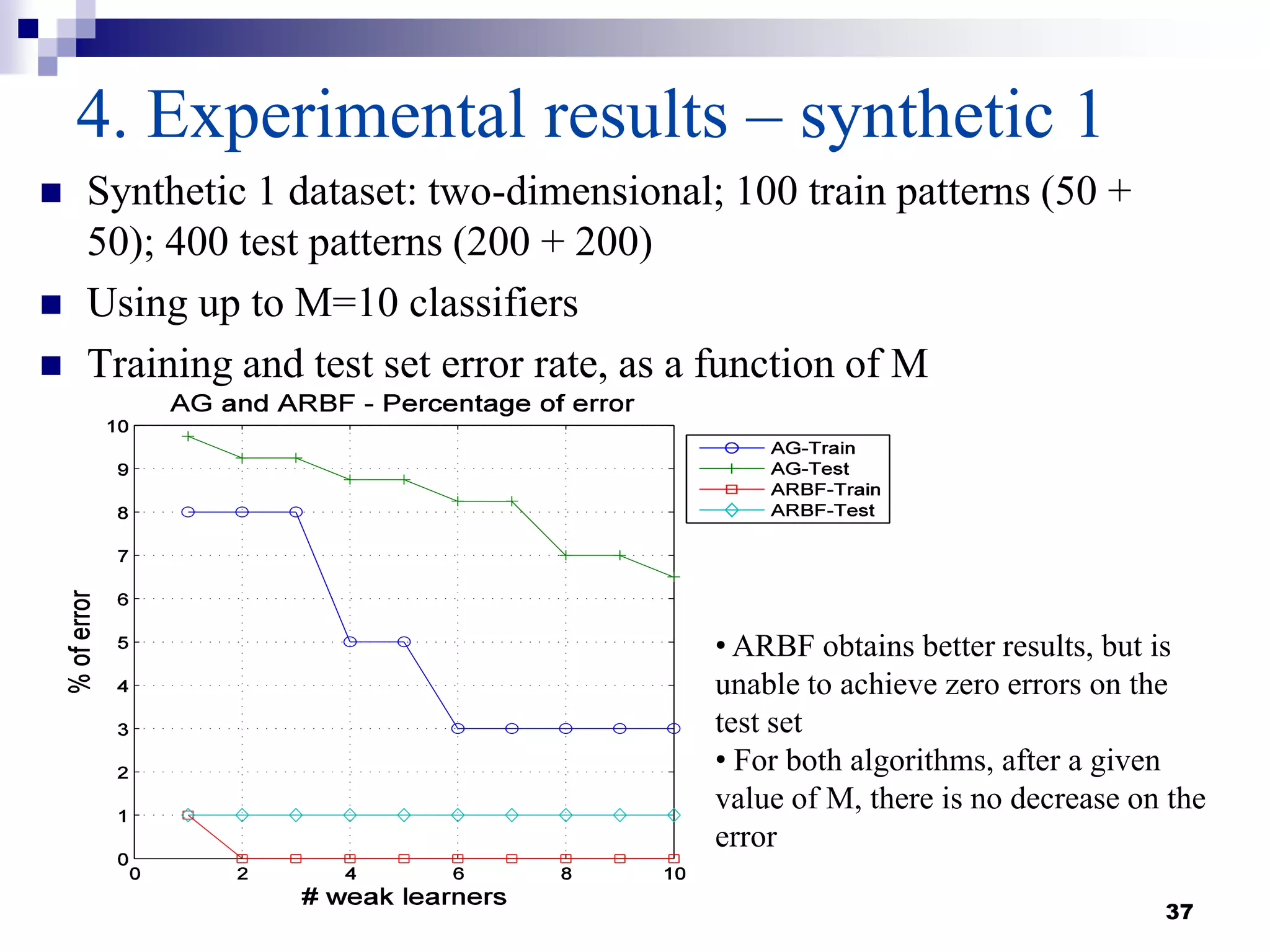
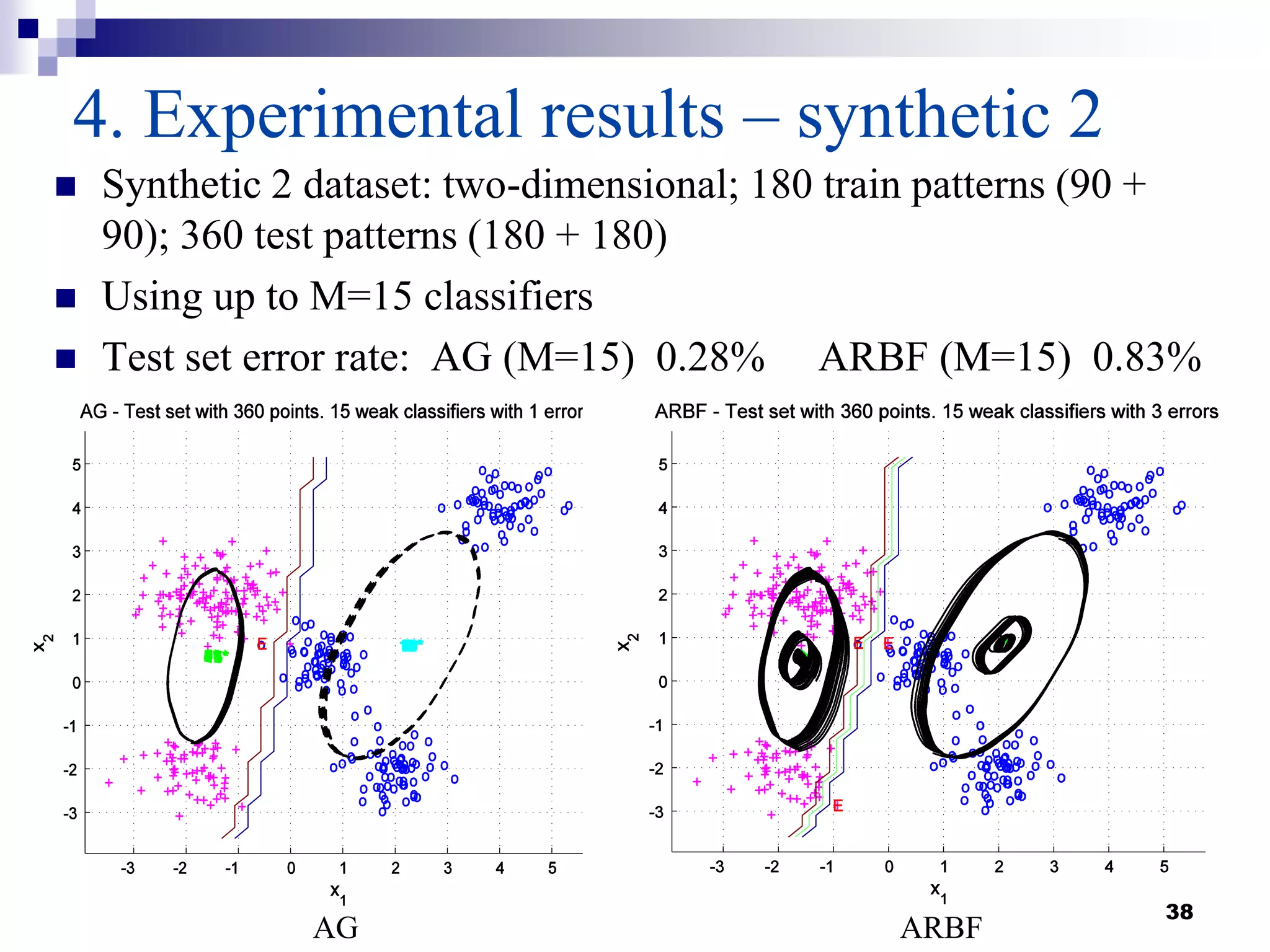
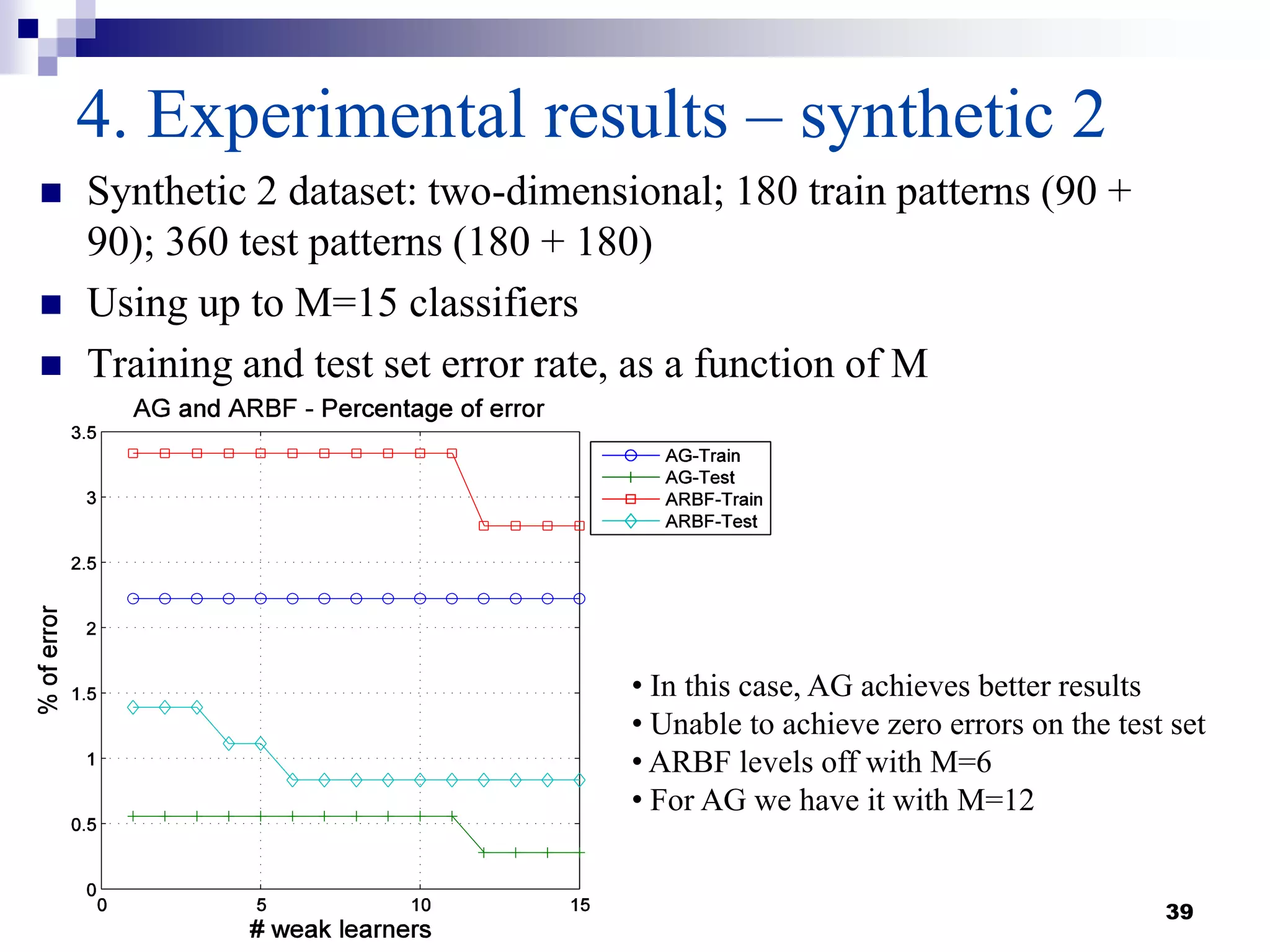
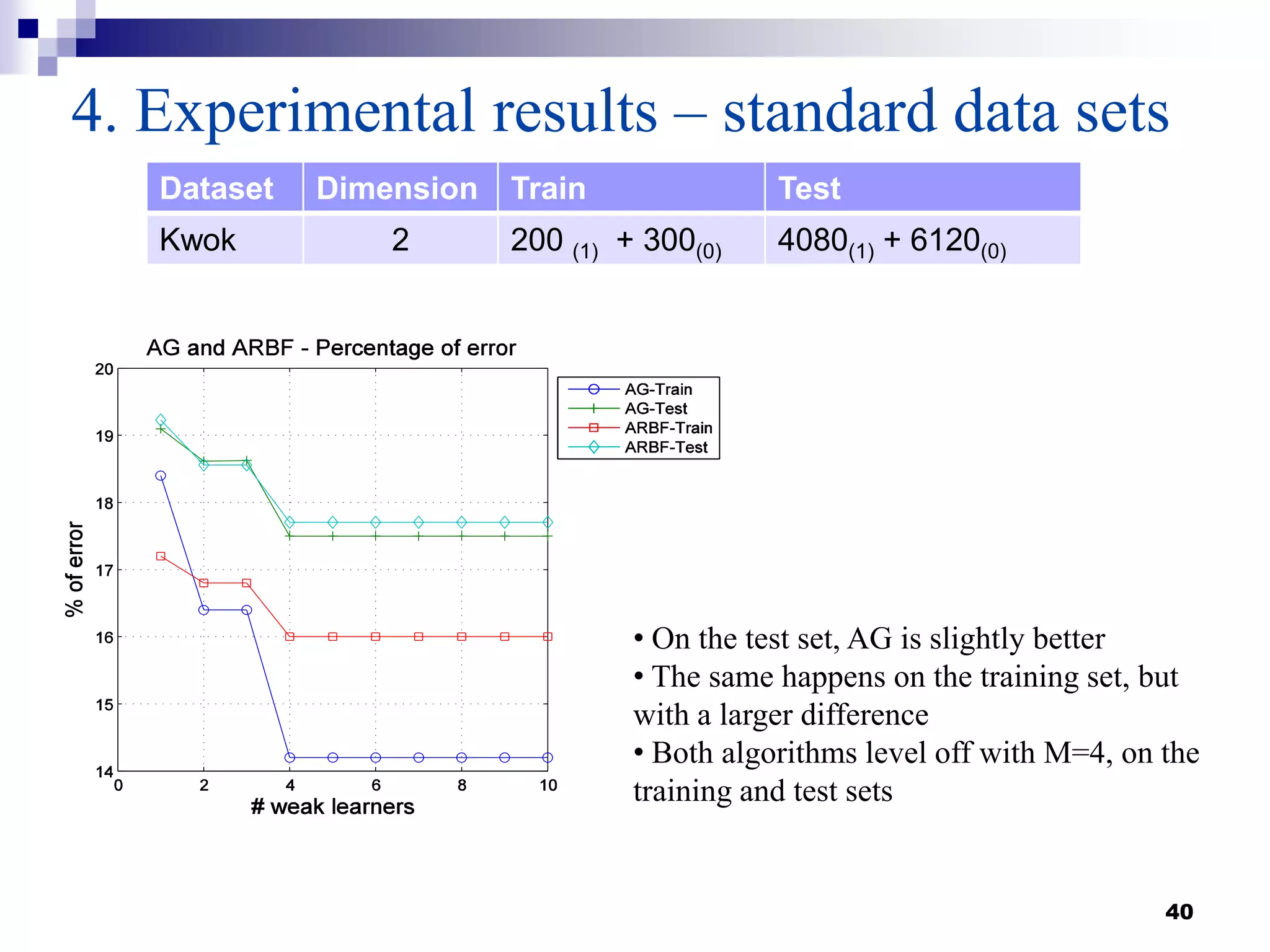
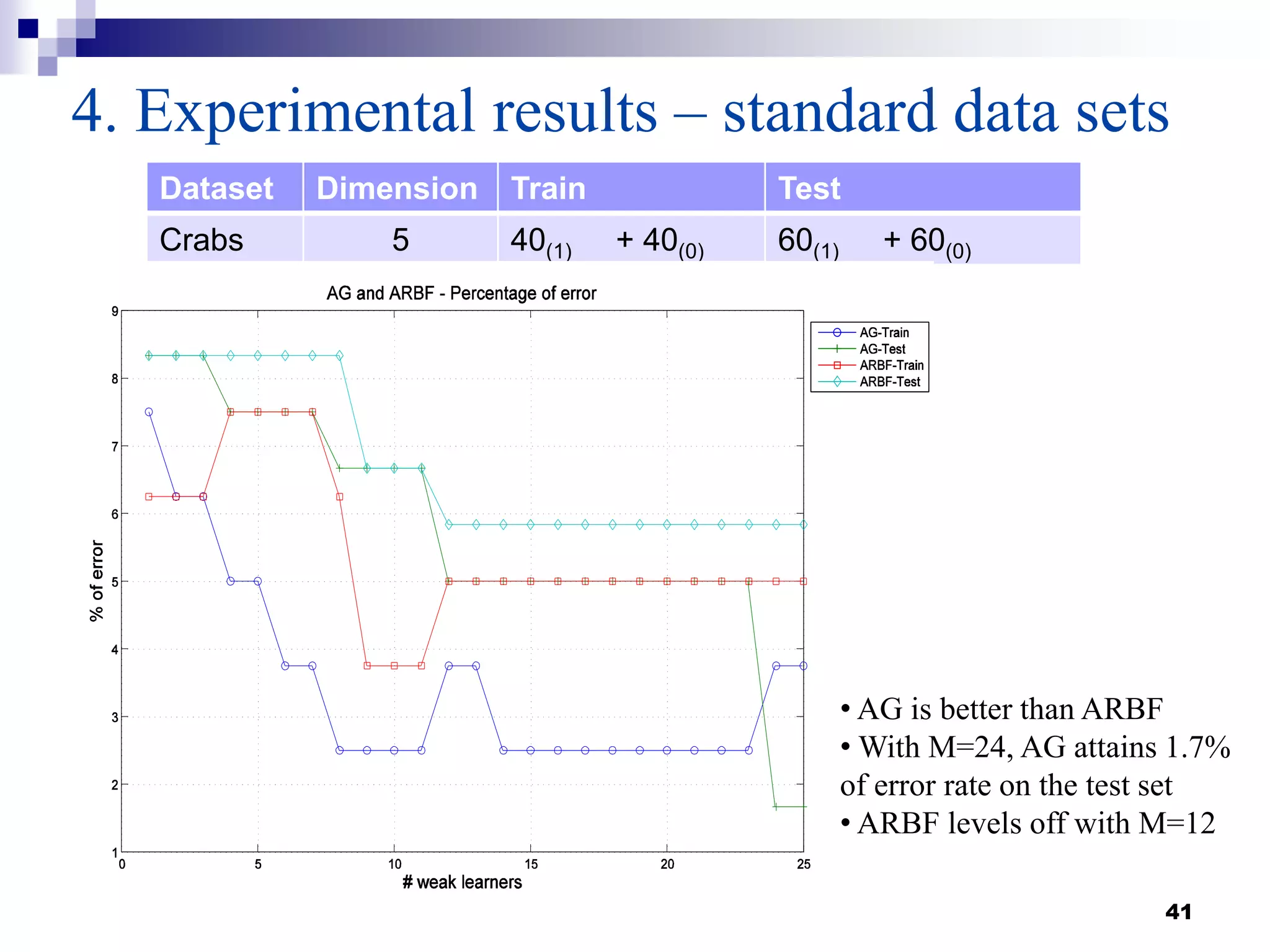
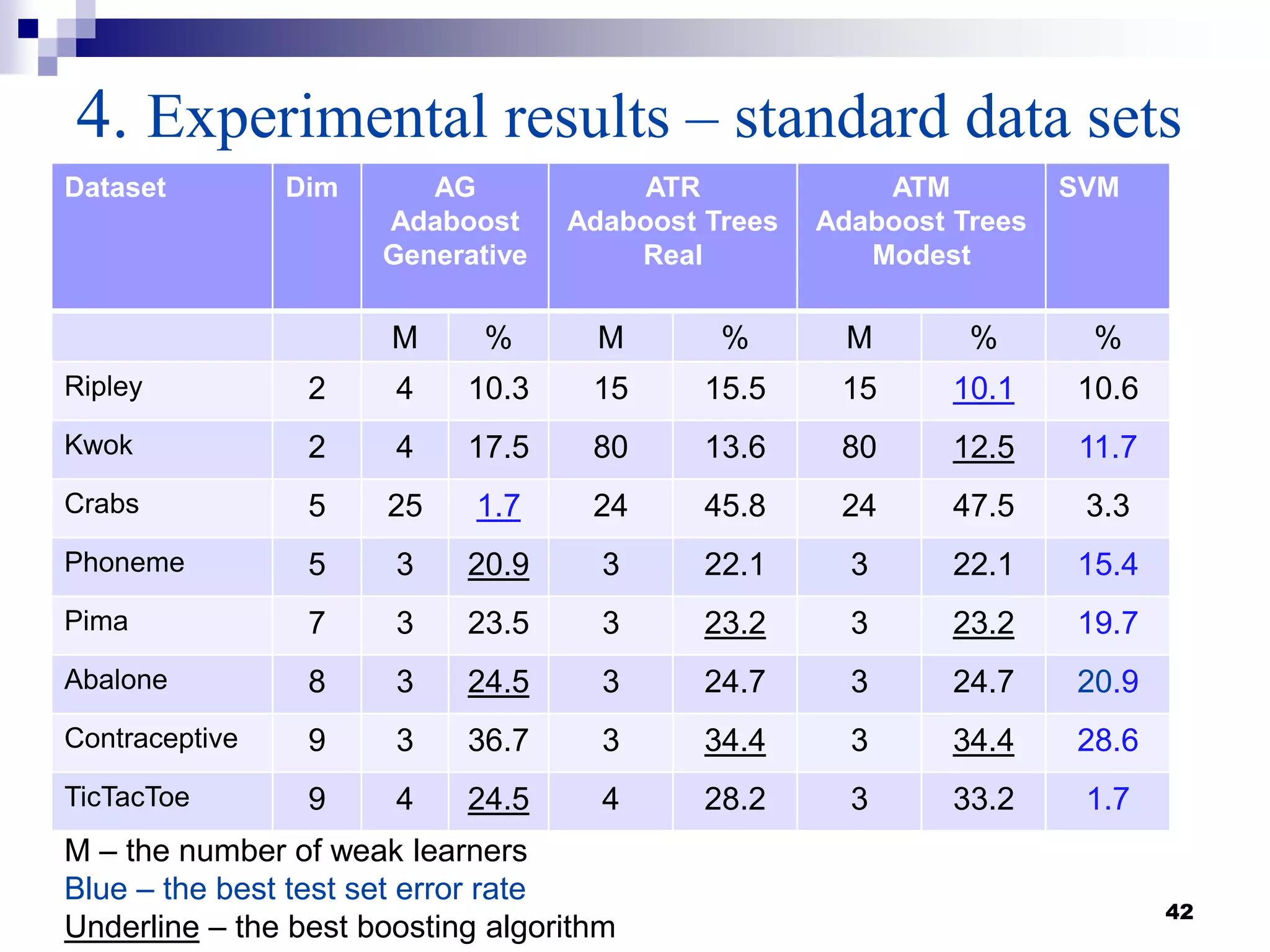



This document summarizes a survey on boosting algorithms for supervised learning. It begins with an introduction to ensembles of classifiers and boosting, describing how boosting builds ensembles by combining simple classifiers with associated contributions. The AdaBoost algorithm and its variants are then explained in detail. Experimental results on synthetic and standard datasets are presented, comparing boosting with generative and RBF weak learners. The results show that boosting algorithms can achieve low error rates, with AdaBoost performing well when weak learners are only slightly better than random.



































































































