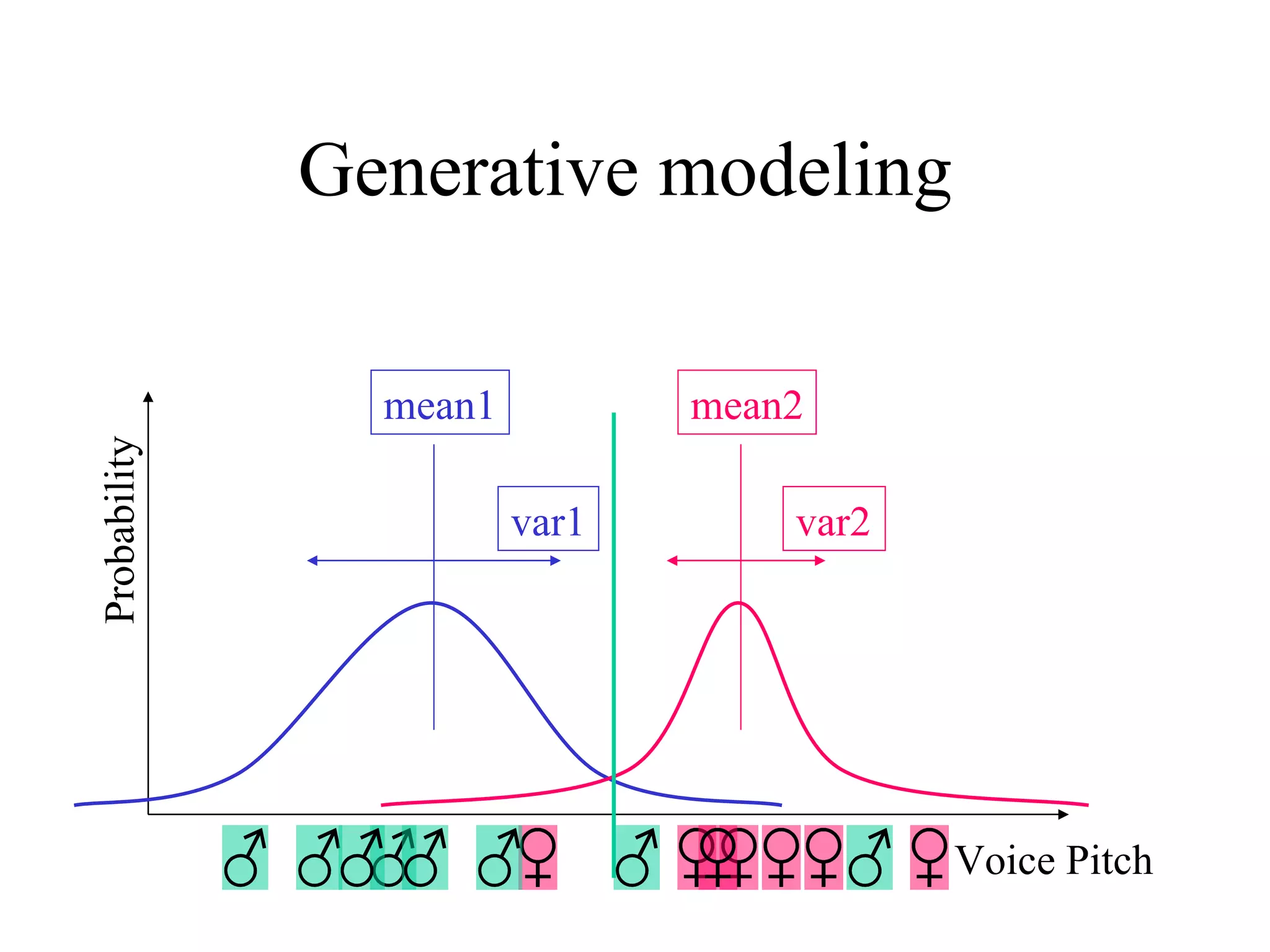
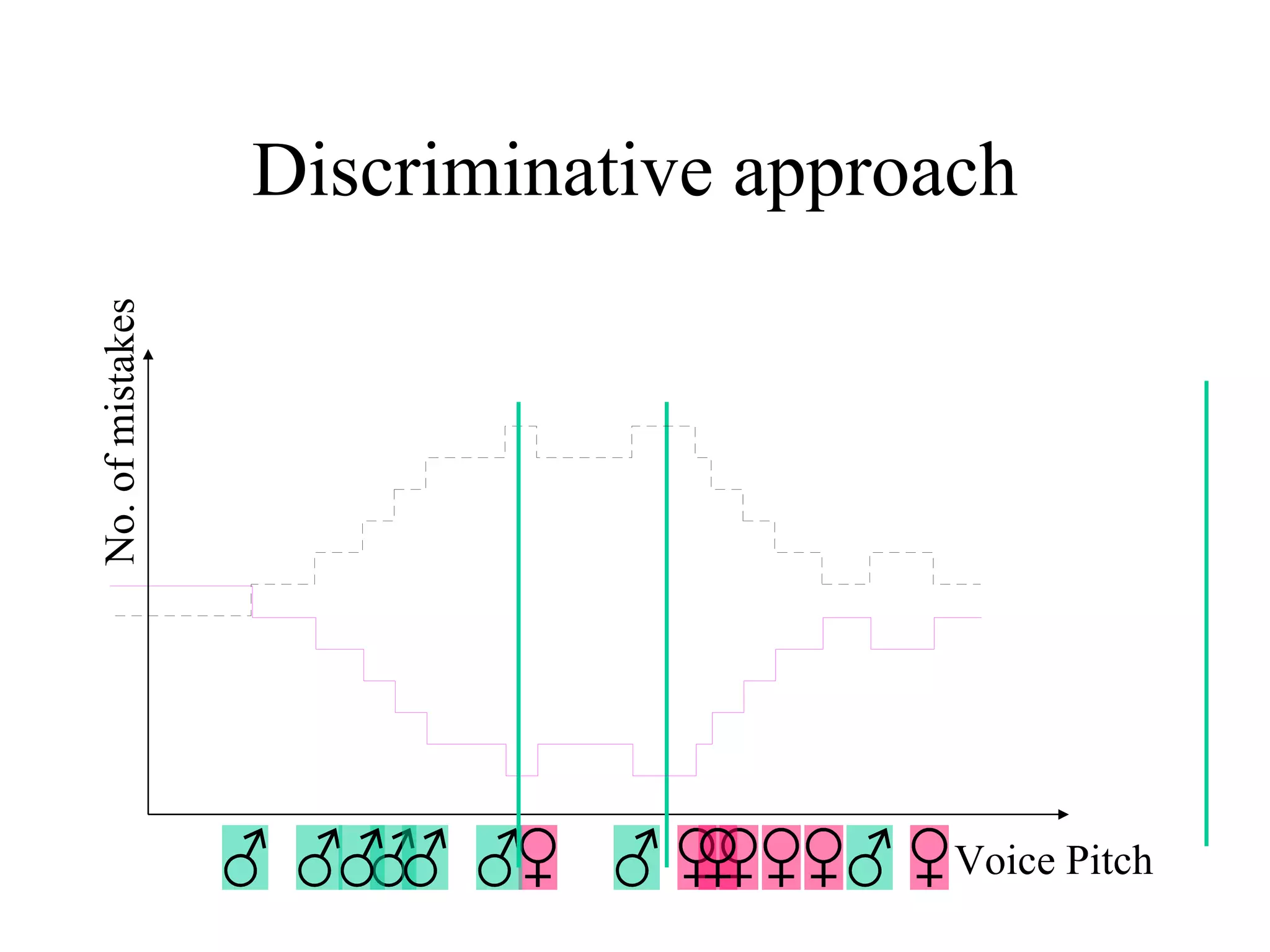
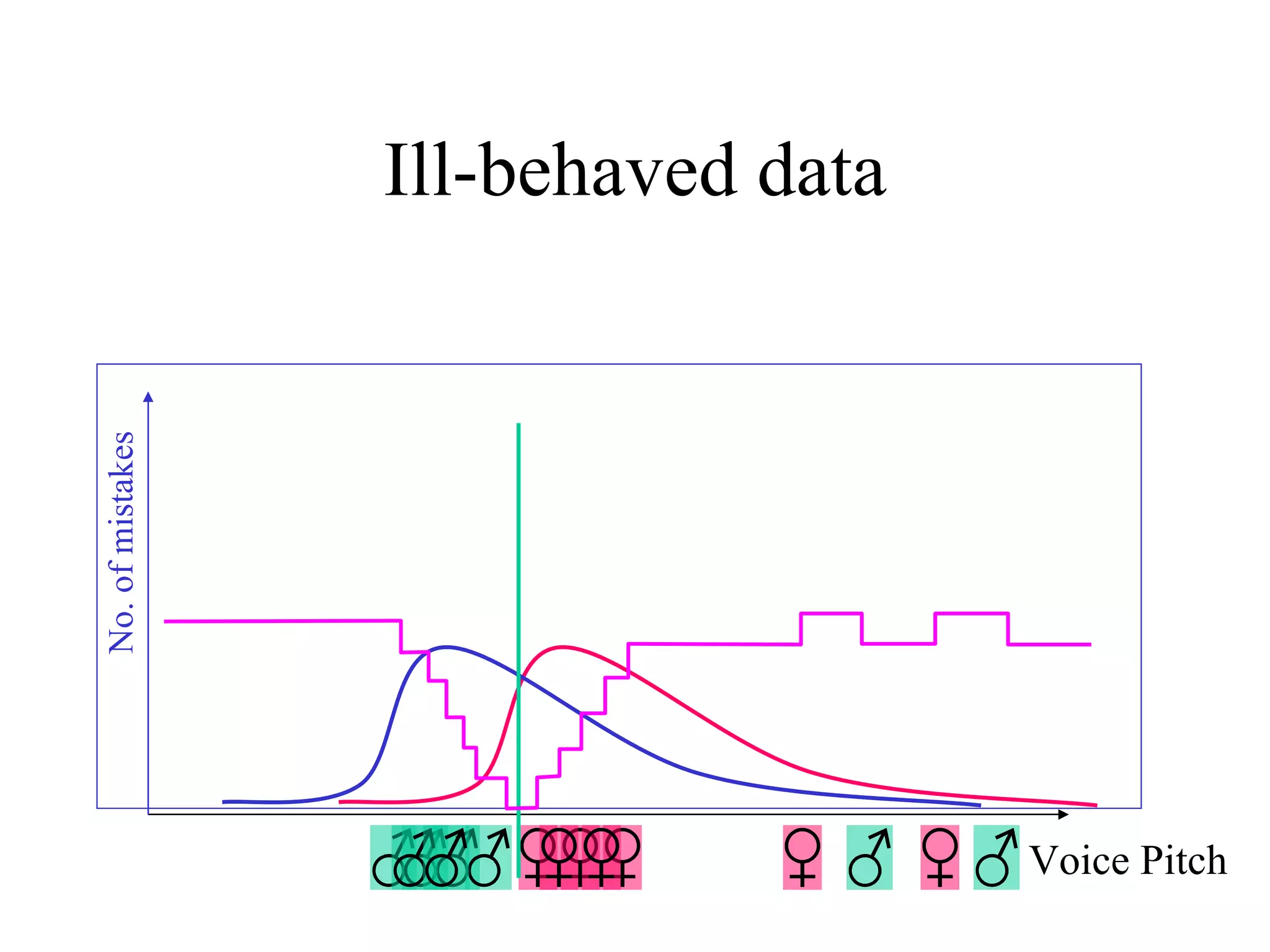
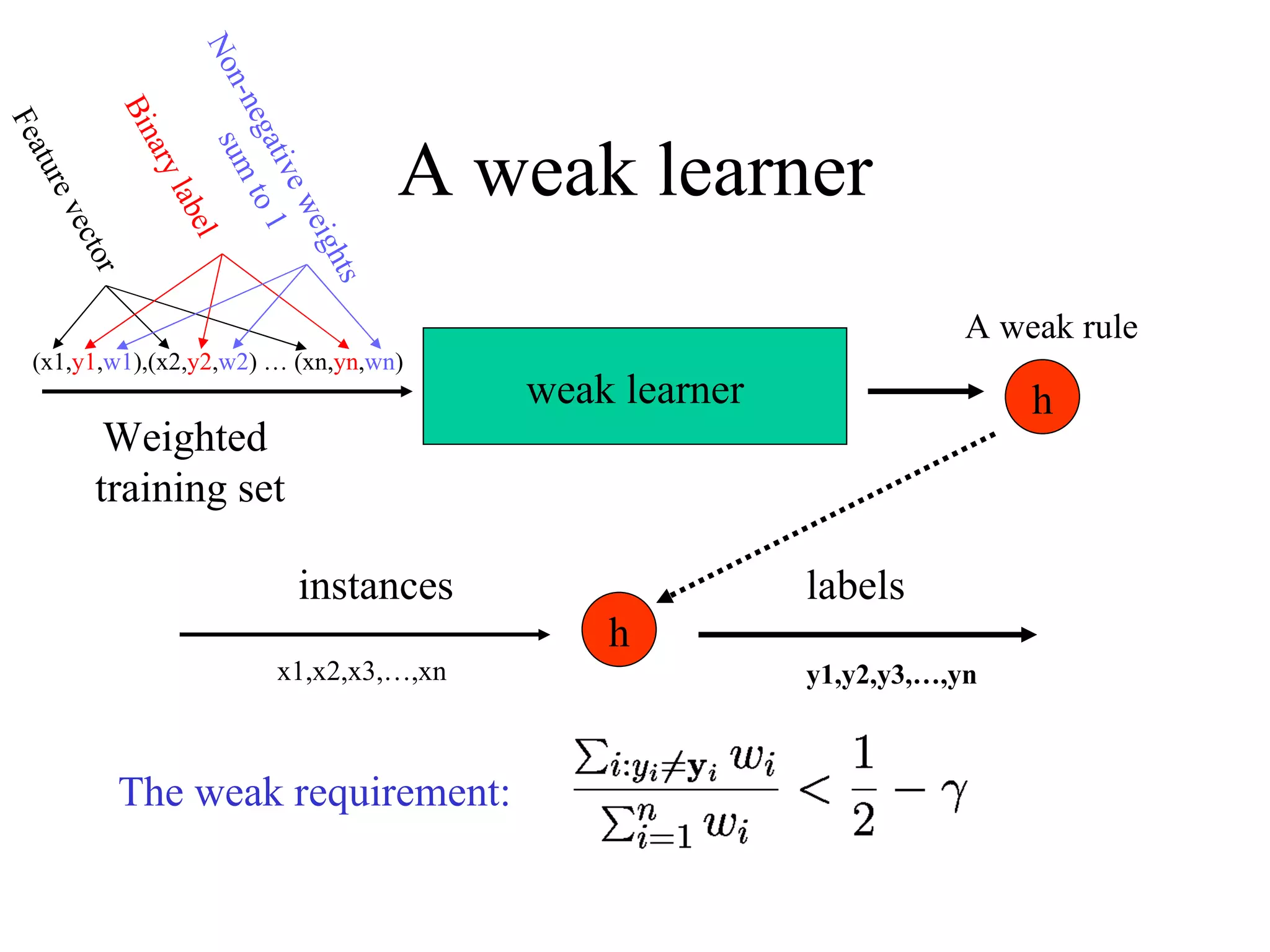
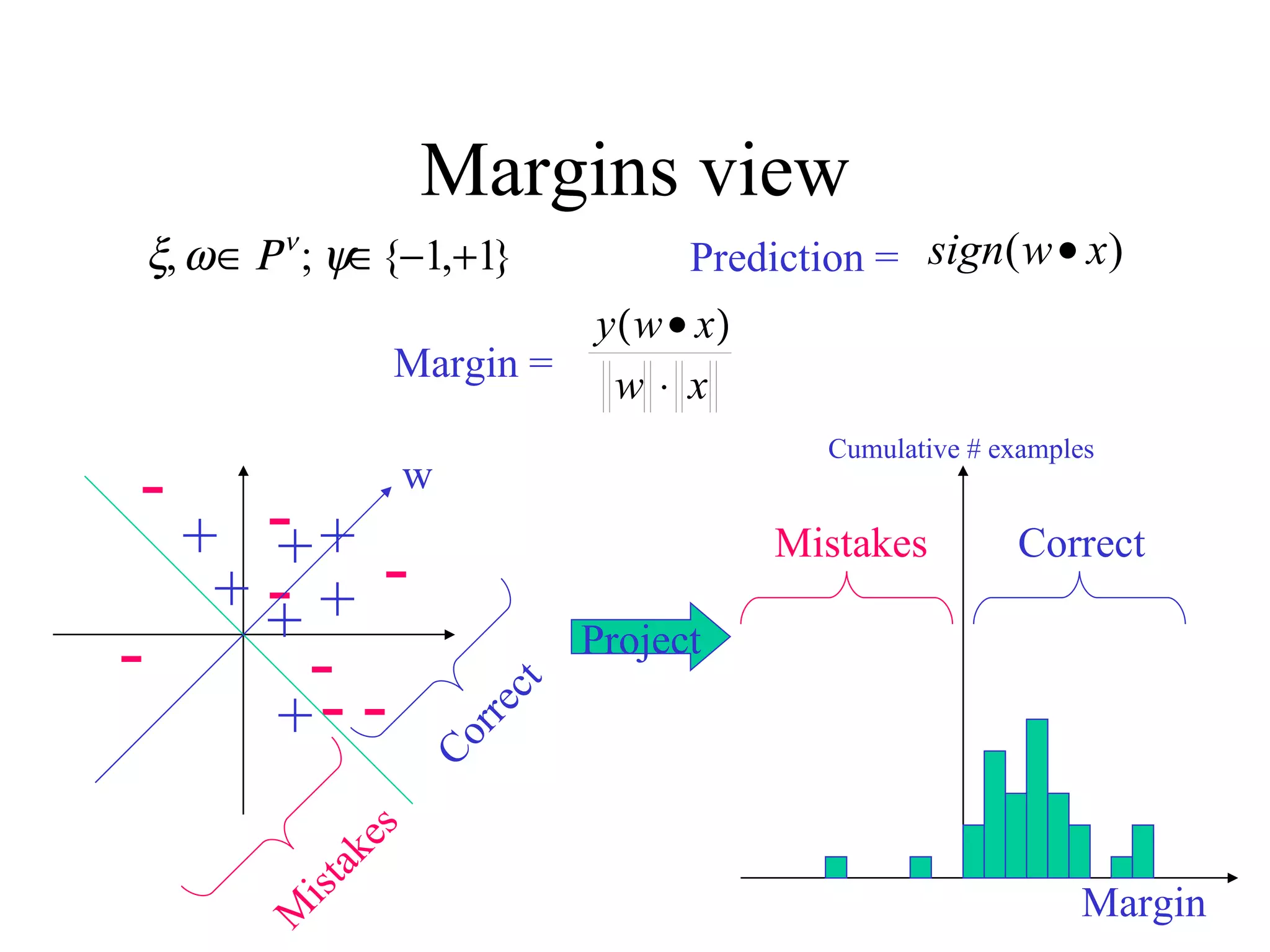
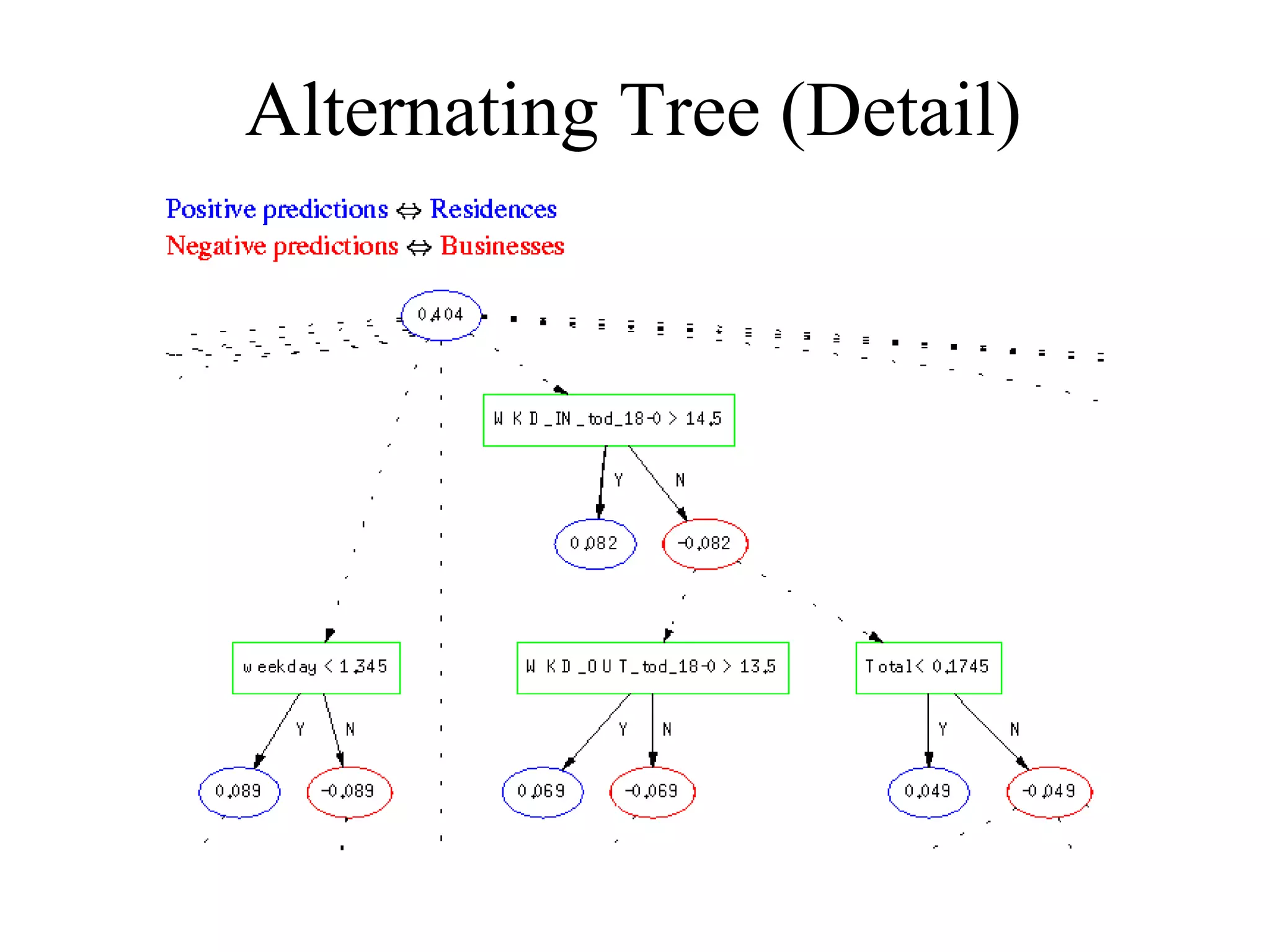
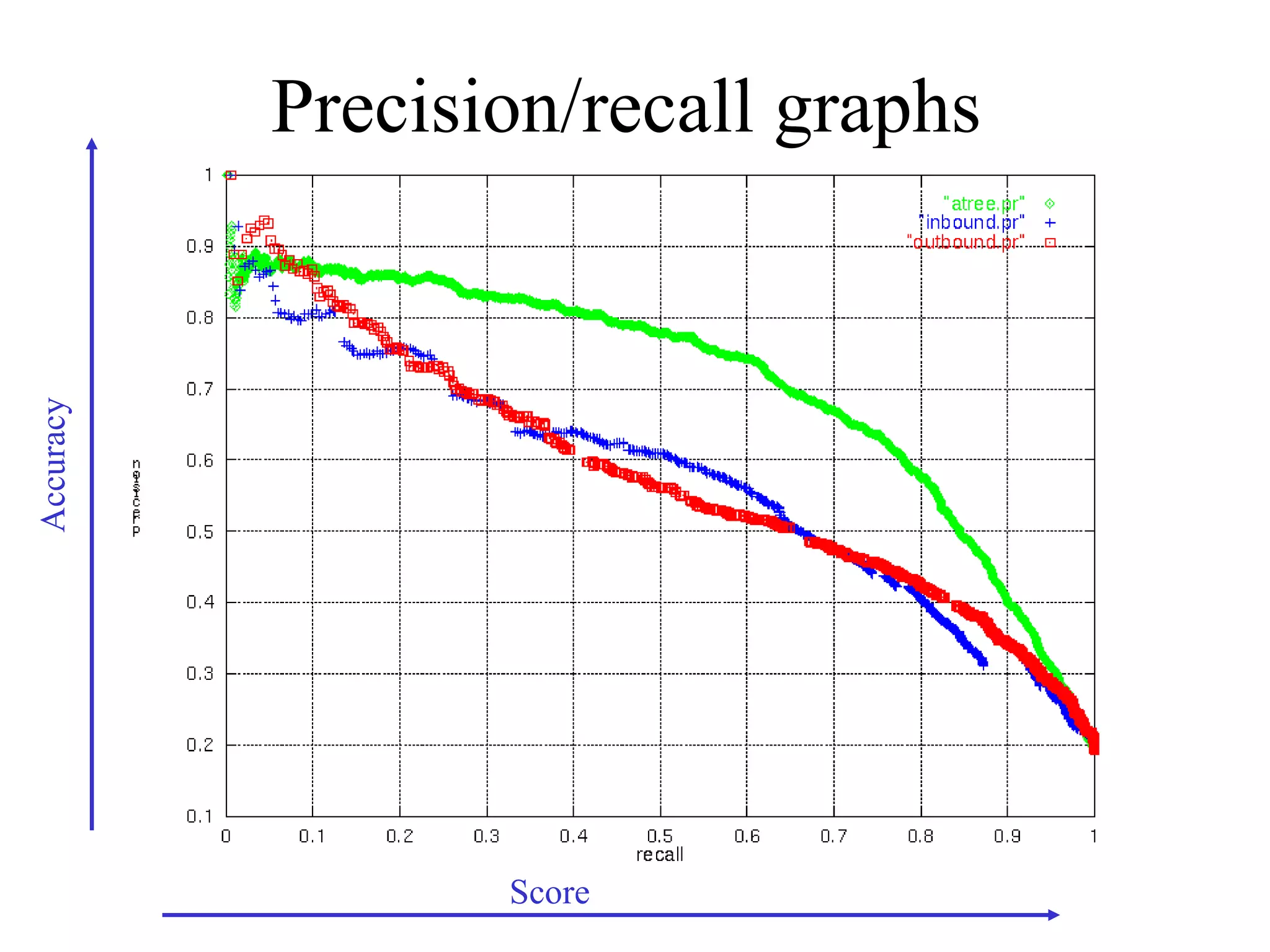
Boosting is a machine learning technique that combines weak learners into a strong learner. It works by training weak learners on weighted versions of the data and incrementally adding them to produce a final strong learner. Boosting is resistant to overfitting due to its focus on training examples with large margins. It has been successfully applied to problems such as optical character recognition, speech recognition, and customer classification.





![The boosting process Final rule: Sign [ ] h1 h2 hT weak learner h1 (x1,y1, 1/n ), … (xn,yn, 1/n ) weak learner h2 (x1,y1, w1 ), … (xn,yn, wn ) h3 (x1,y1, w1 ), … (xn,yn, wn ) h4 (x1,y1, w1 ), … (xn,yn, wn ) h5 (x1,y1, w1 ), … (xn,yn, wn ) h6 (x1,y1, w1 ), … (xn,yn, wn ) h7 (x1,y1, w1 ), … (xn,yn, wn ) h8 (x1,y1, w1 ), … (xn,yn, wn ) h9 (x1,y1, w1 ), … (xn,yn, wn ) hT (x1,y1, w1 ), … (xn,yn, wn )](https://image.slidesharecdn.com/an-introduction-to-boosting3936/75/An-Introduction-to-boosting-11-2048.jpg)
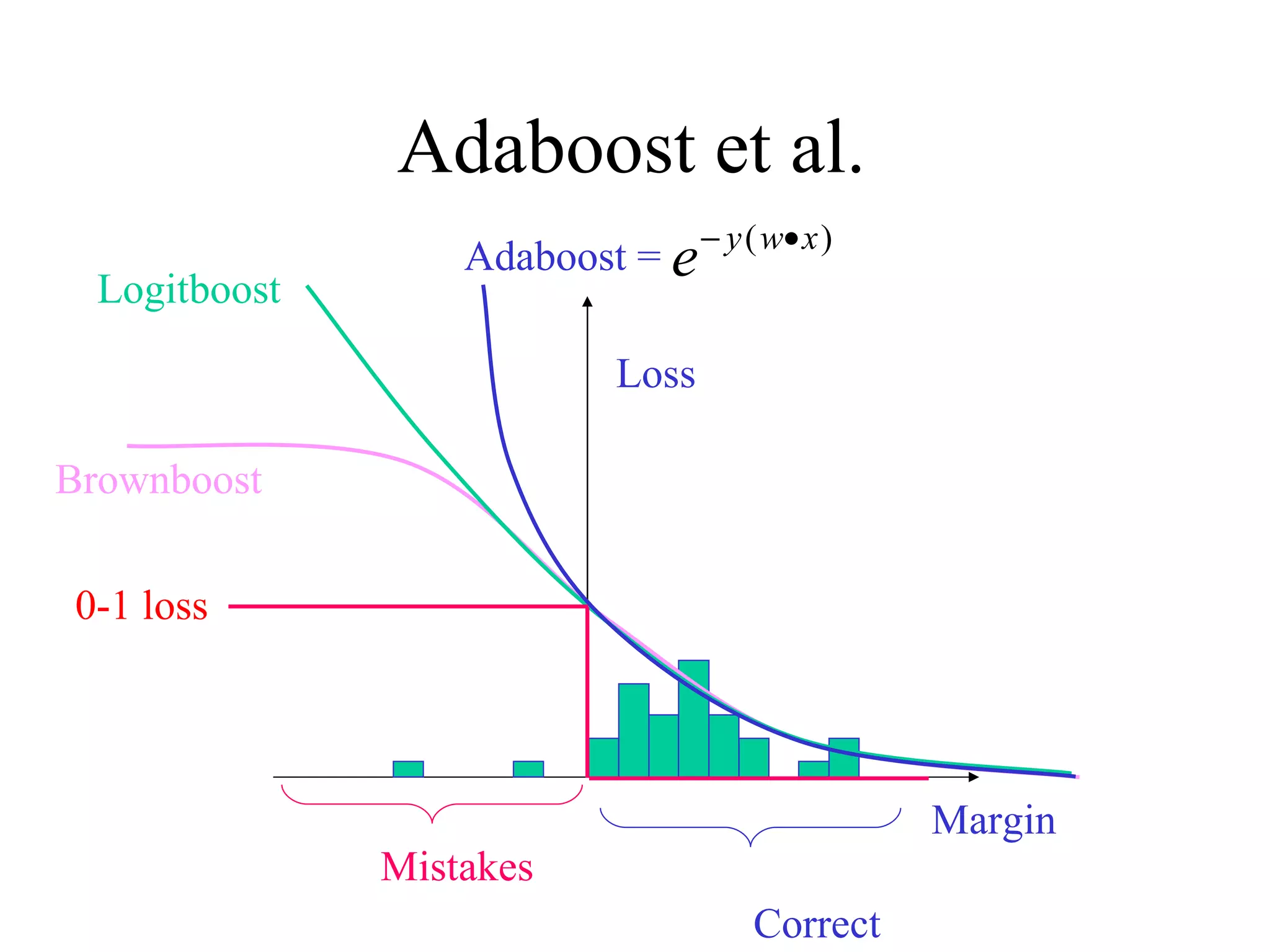
![Adaboost Binary labels y = -1,+1 margin ( x,y ) = y [ t t h t (x) ] P(x,y) = (1/Z) exp (-margin(x,y)) Given h t , we choose t to minimize (x,y) exp (-margin (x,y) )](https://image.slidesharecdn.com/an-introduction-to-boosting3936/75/An-Introduction-to-boosting-12-2048.jpg)









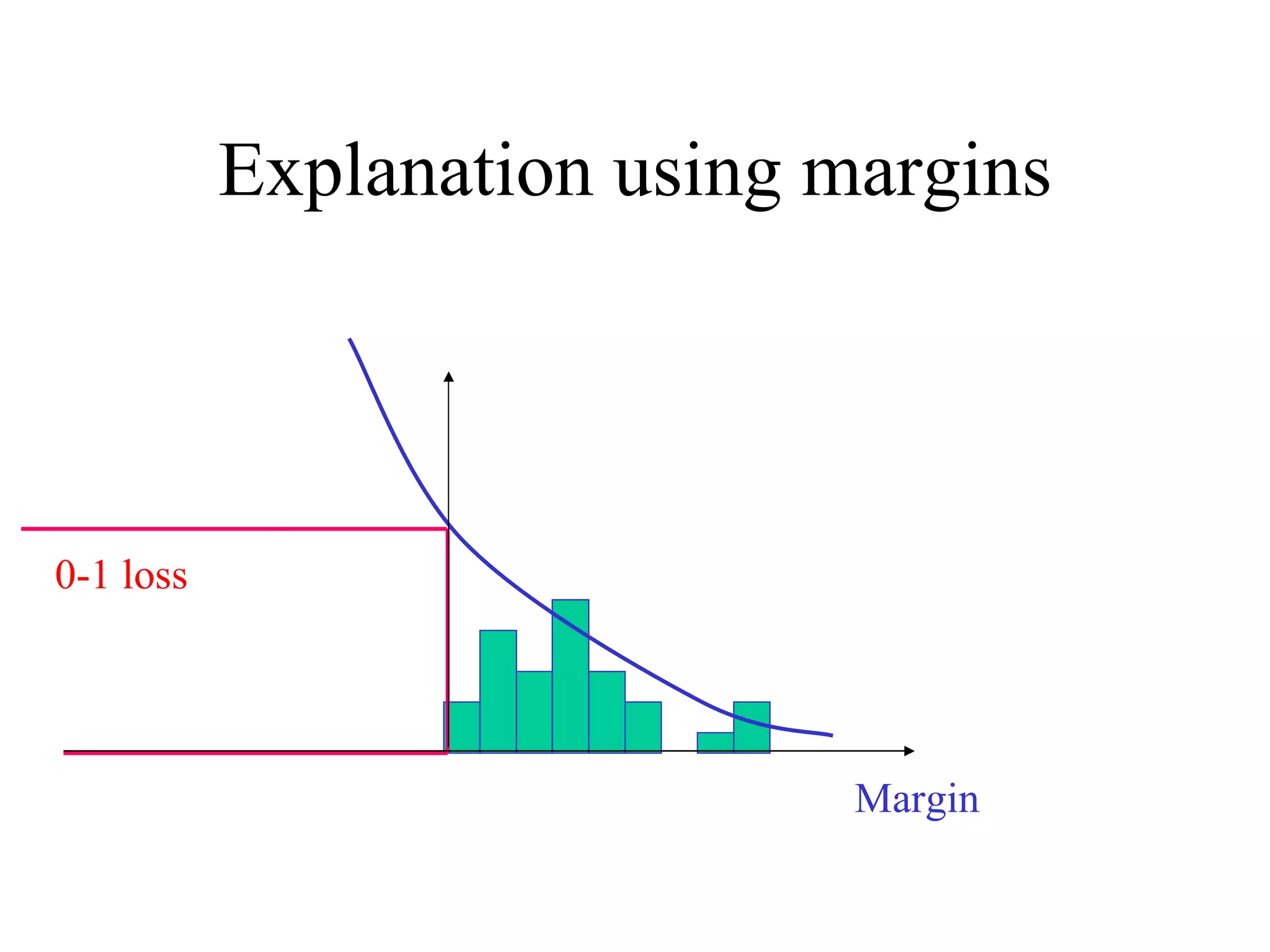
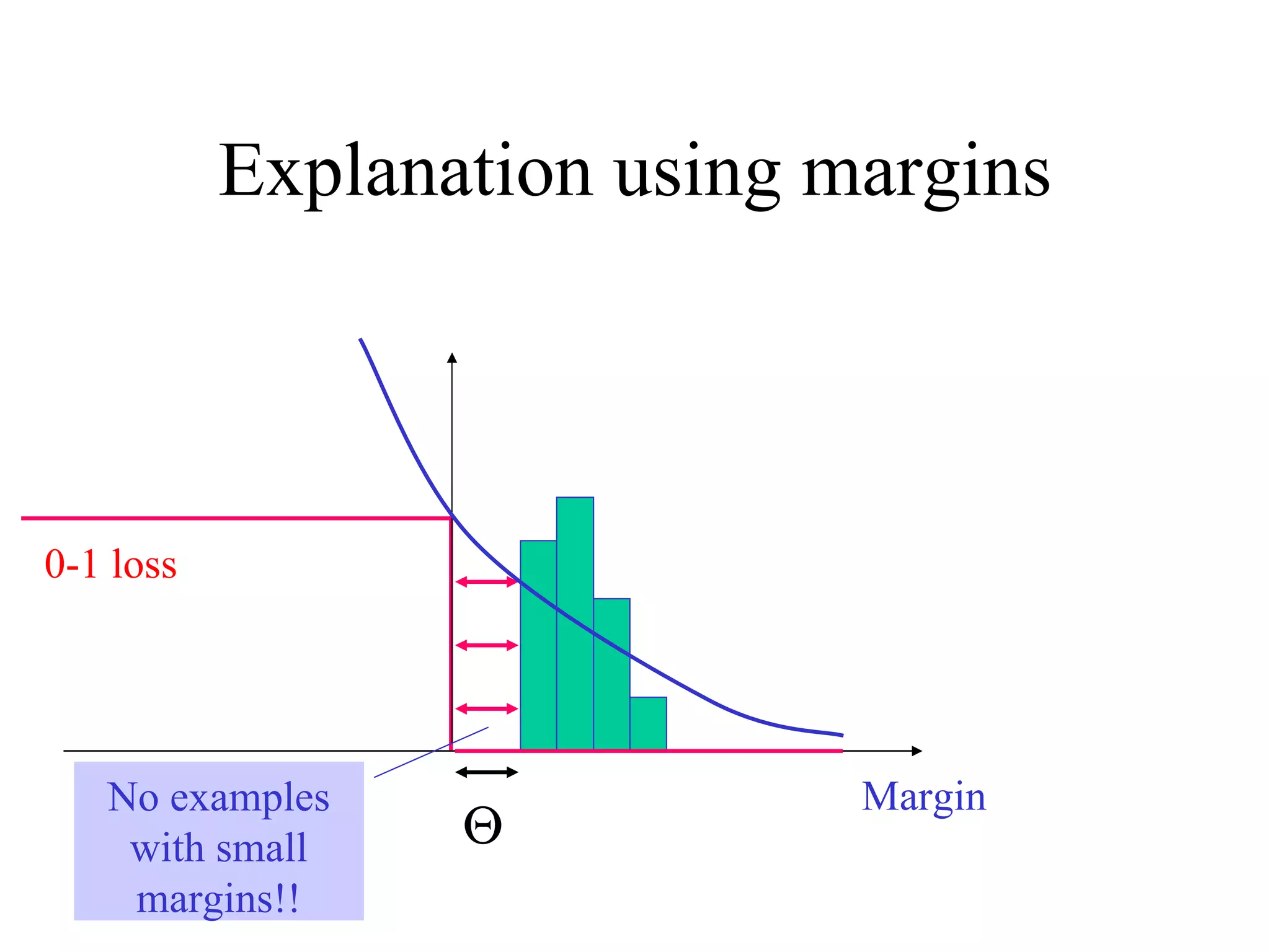
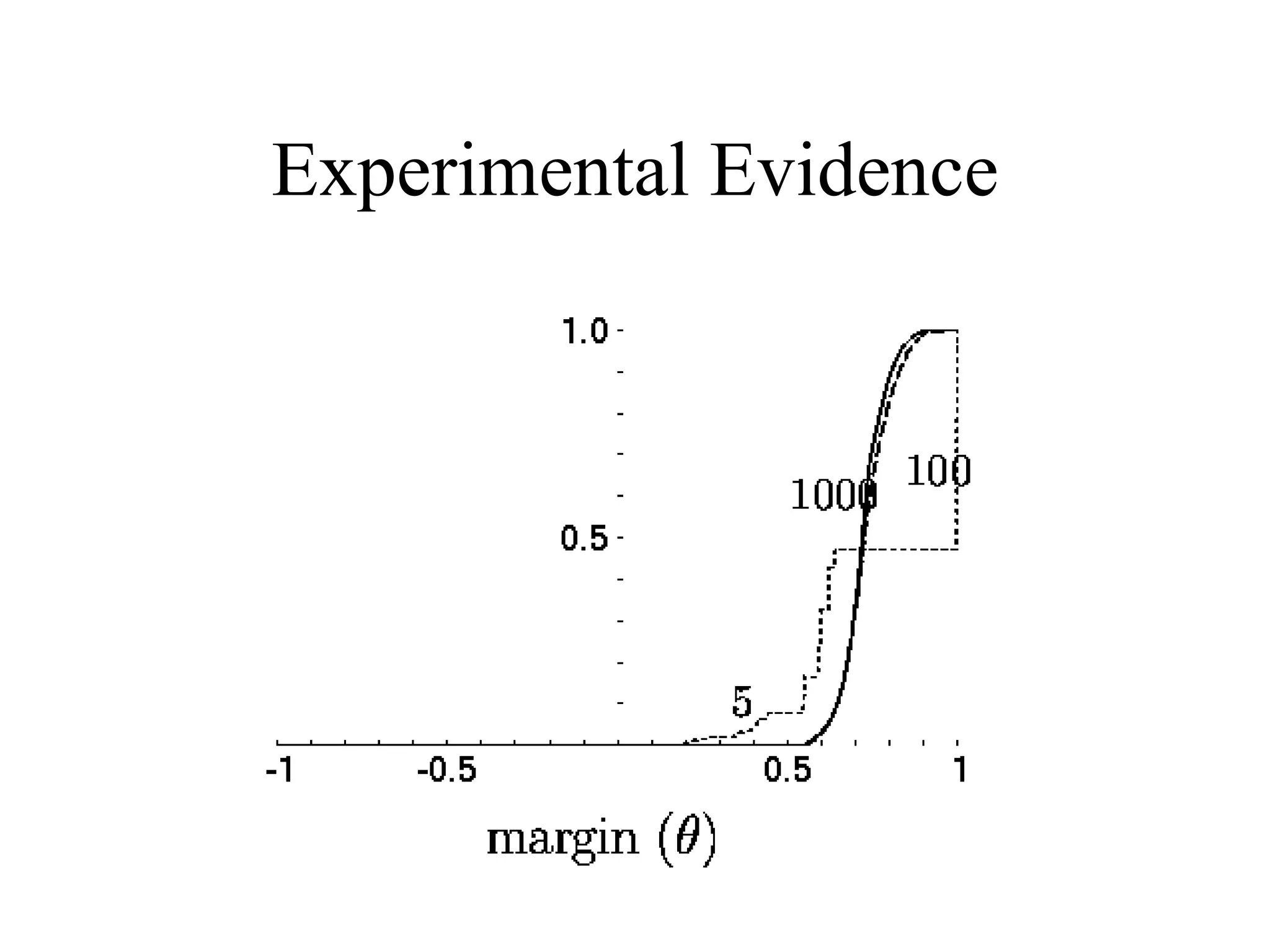

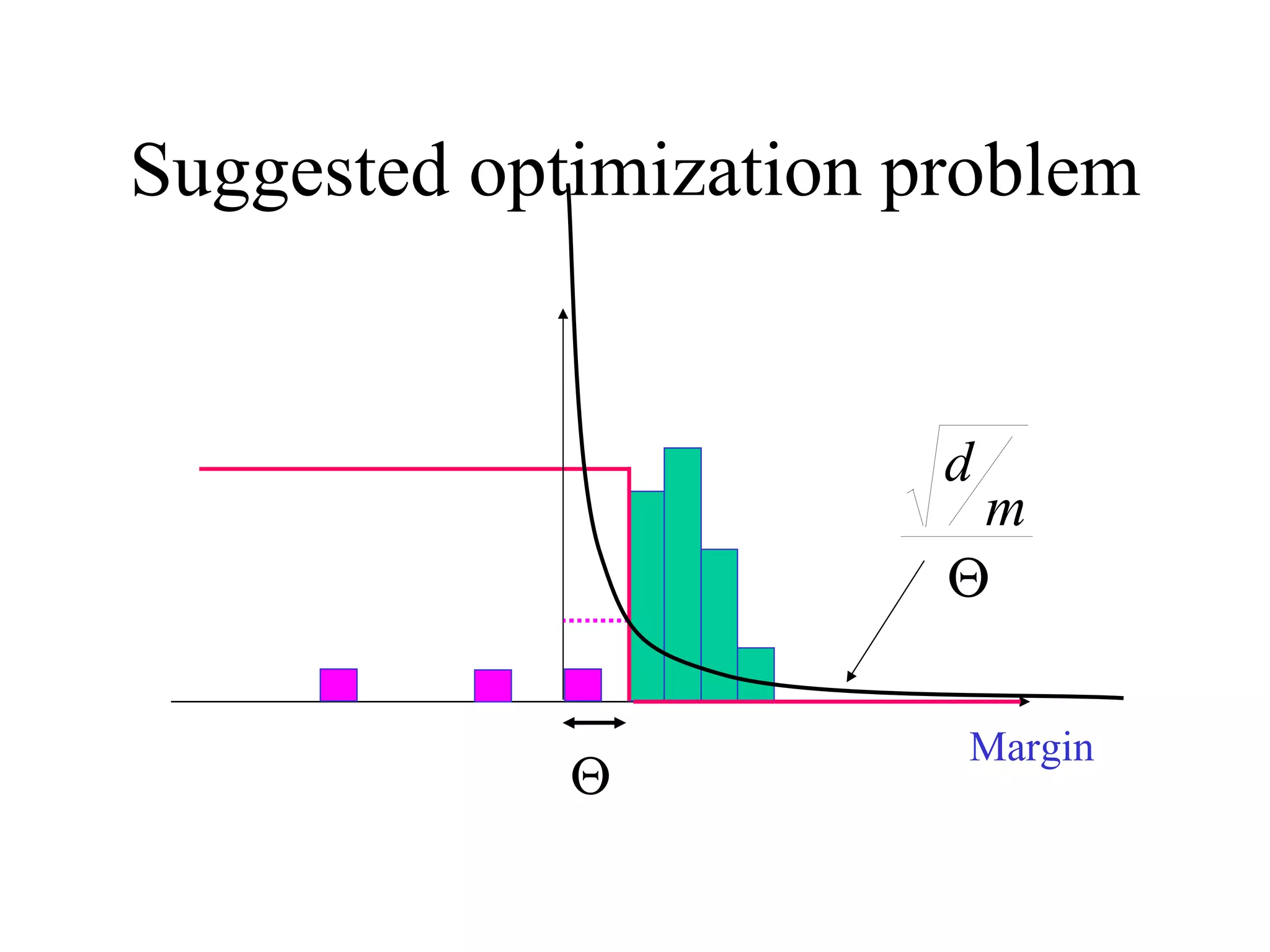
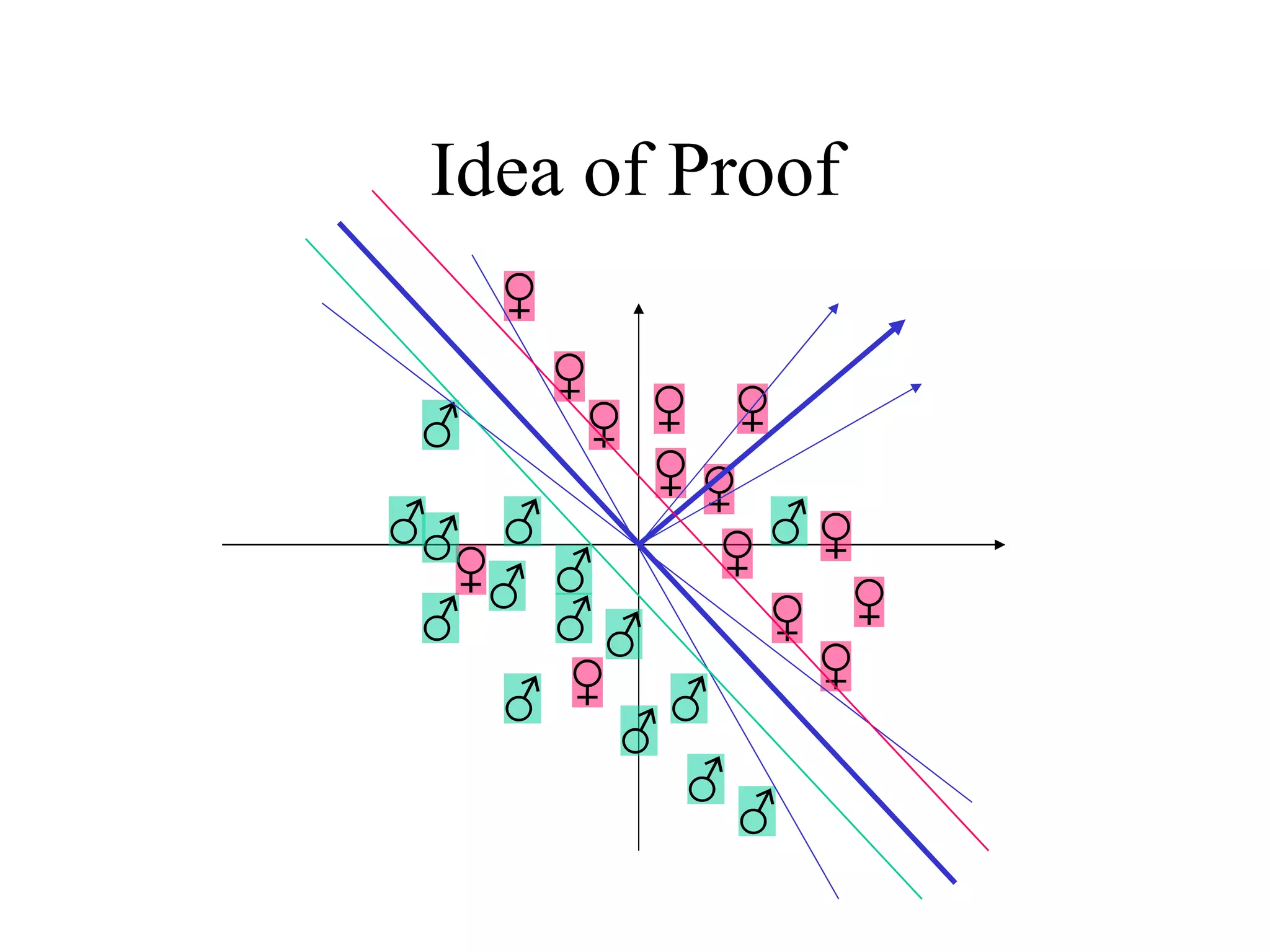


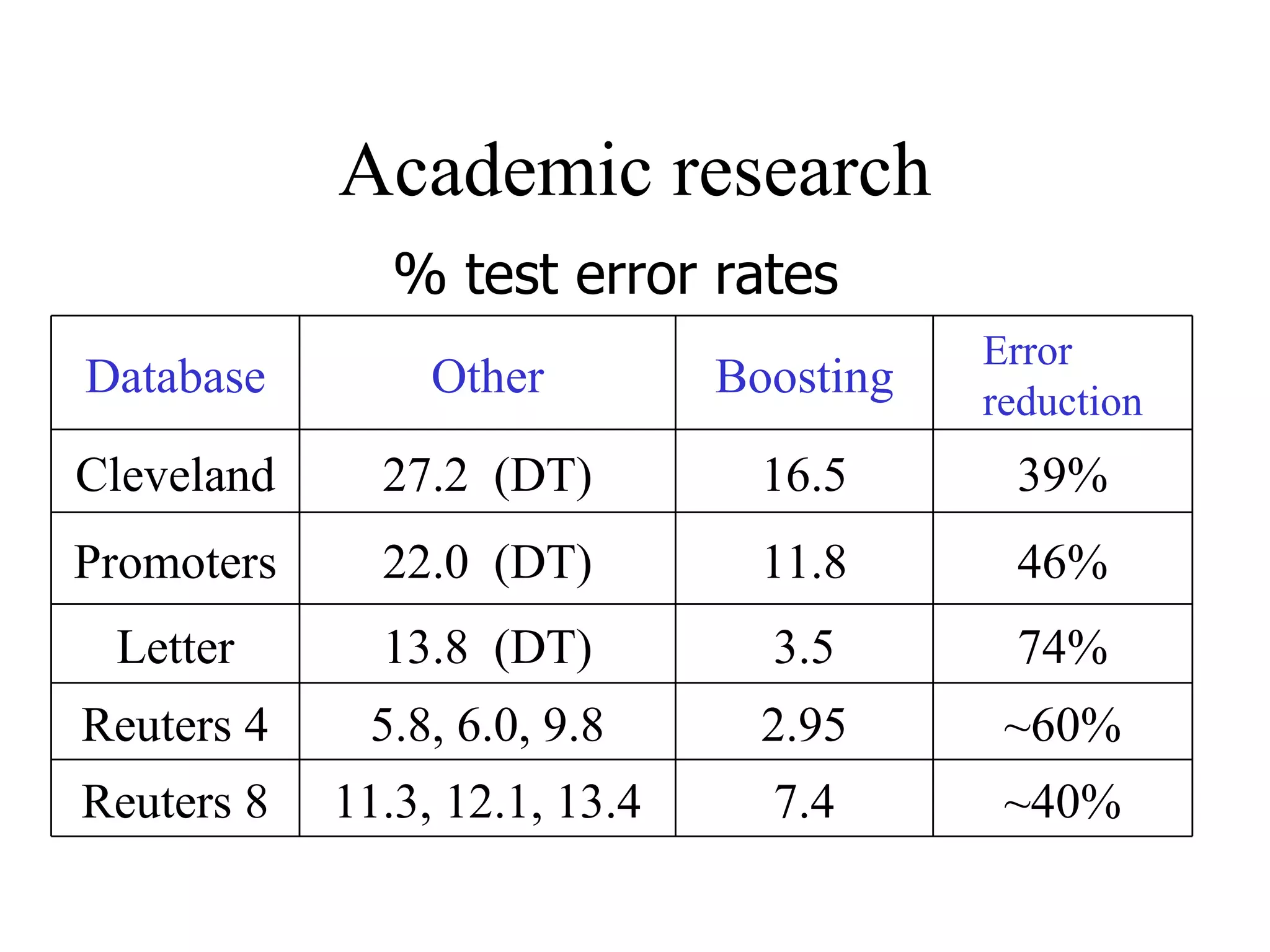


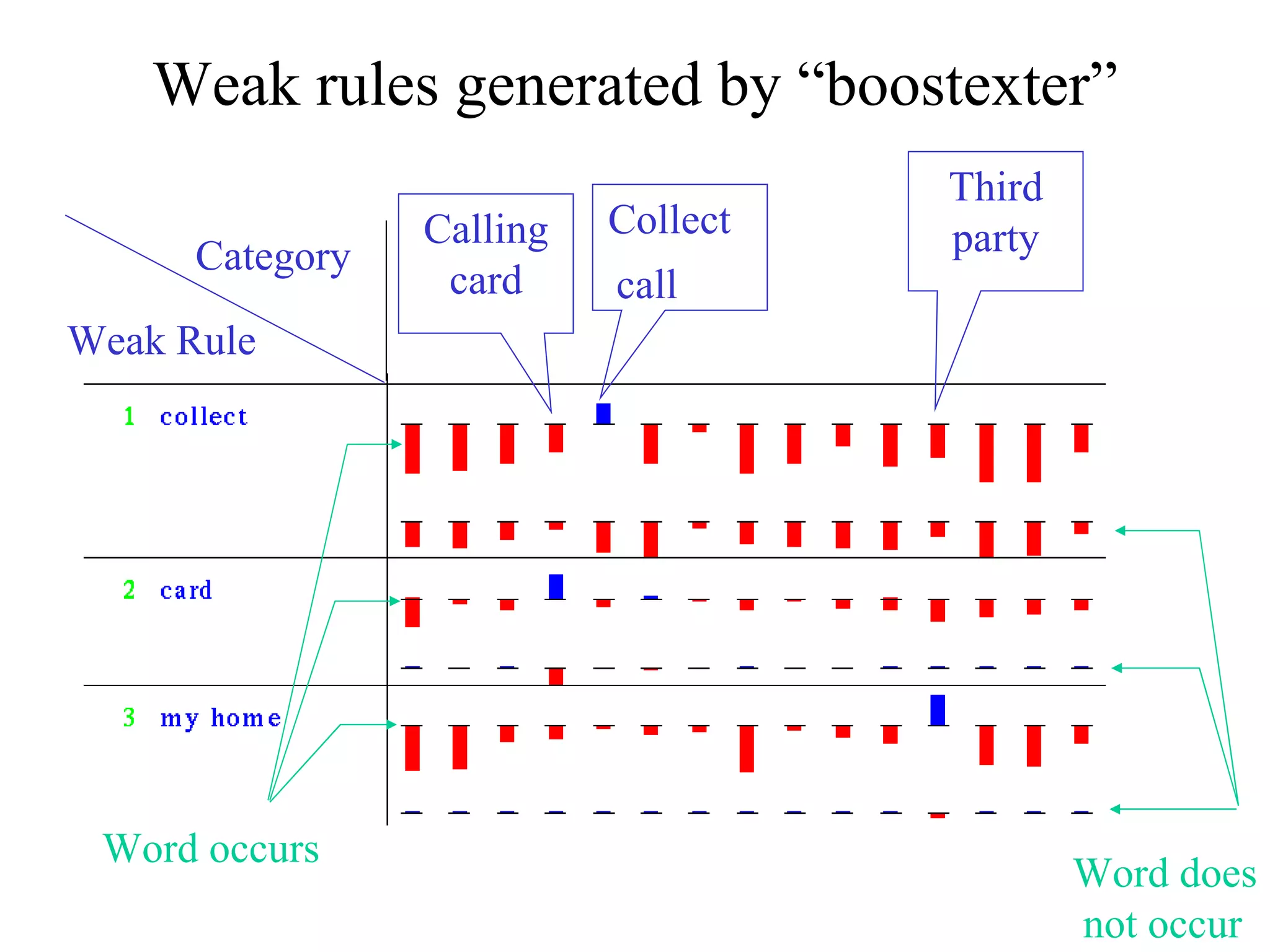



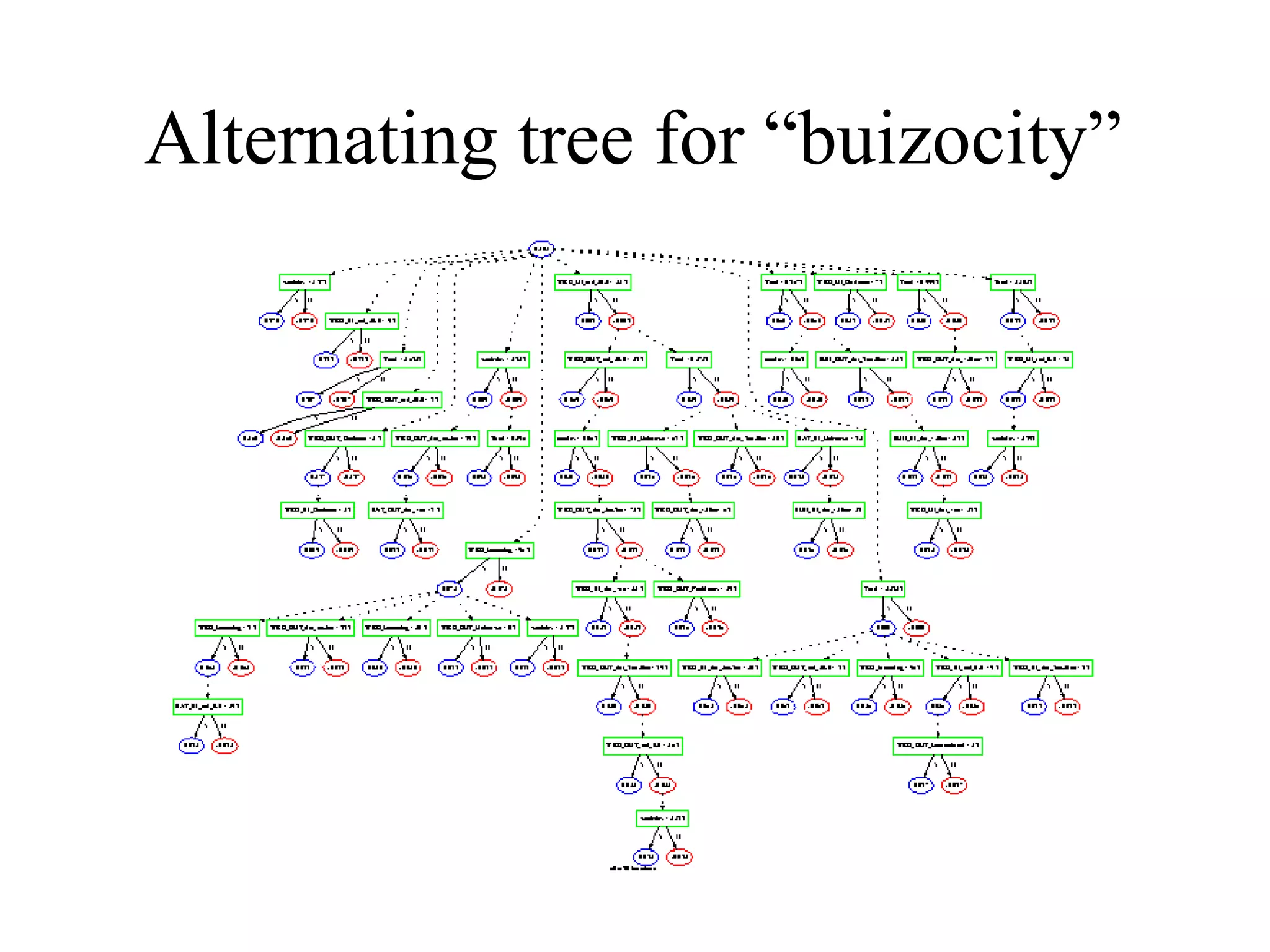


![Come talk with me! [email_address] http://www.cs.huji.ac.il/~yoavf](https://image.slidesharecdn.com/an-introduction-to-boosting3936/75/An-Introduction-to-boosting-49-2048.jpg)






















































































