Download as PDF, PPTX








![Discrete AdaBoost Classification Algorithm
Given an input training set, (xi , yi )n
i=1, a weighted loss function L(y, F(x), w) where F(·) is a weak classifier, and a number of
estimators, M.
1. Initialize the observation weights: wi = 1
N , i = 1, 2, . . . , N
2. For m = 1 to M estimators:
(a) Fit a weak classifier Fm(x): (e.g., decision tree of depth 1) to the weighted training data
that minimizes the weighted loss function, L(y, Fm(·), w).
(b) Compute the weighted error rate for classifier m:
εm =
N
i wi · I [yi = Fm(xi )]
N
i wi
(c) Compute tree weighting factor:
αm = log
1 − εm
εm
(d) Update training data weights:
wi ← wi · exp {αm · I [yi = Fm(xi )]} , for i = 1, 2, . . . , N
3. Finally, output the sign of the weighted sum of models 1 . . . , M:
F(X) = sign
M
m=1
αmFm(X)
E.g., Fm(xi ) = arg min
F(·)
N
i wi · I [yi = F(xi )]
A measure of each
weak learner’s
classification success](https://image.slidesharecdn.com/boostingpresentation-180113040104/85/Boosting-An-Ensemble-Machine-Learning-Method-8-320.jpg)

![Gradient Descent Regressor Algorithm
Given an input training set, (xi , yi )n
i=1, a differentiable loss function L(y, G(X)) where G(·) is a weak regressor, and a number
of estimators, M.
1. Initialize model with a constant value:
G0(X) = arg min
γ
n
i
L(yi , γ)
= ¯y
2. For m = 1 to M:
(a) Compute the pseudo-residuals:
ri,m = −
∂L(yi , Gm−1(xi ))
∂Gm−1(xi )
for i = 1, . . . , n
(b) Fit a high-bias learner, Gm(X) to pseudo-residuals.
(c) Calculate a weighting multiplier:
γm = arg min
γ
n
i=1
L(yi , Gm−1(xi ) + γGm(xi ))
3. Finally, combine the weighted estimators:
G(X) =
M
m=1
γmGm(X)
E.g., L(y, G(X)) = i
1
2 [yi − G(xi )]2
,
where G(·) is a decision tree of depth 1
i.e., the gradient part!
Train with (xi , ri,m)n
i=1
(instead of y)
The greater the
loss-improvement, the
higher the weight](https://image.slidesharecdn.com/boostingpresentation-180113040104/85/Boosting-An-Ensemble-Machine-Learning-Method-10-320.jpg)
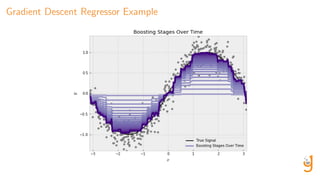



This document compares and contrasts boosting with other ensemble methods such as bagging and random forests. It discusses two specific boosting algorithms - AdaBoost, which fits models on weighted labels, and gradient boosting, which fits models on residuals from previous models. Both aim to produce low bias, low variance predictions by building models sequentially. The document provides pseudocode for AdaBoost classification and gradient boosting regression, and explains how boosting methods work to improve upon previous predictions at each step of the ensemble.



































































