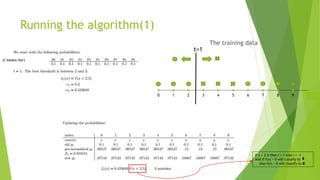
AdaBoost is an adaptive boosting algorithm that aggregates multiple weak learners, giving higher weight to misclassified examples. It reduces bias and models for low variance and high bias. The algorithm resamples the training data and runs multiple iterations, adjusting the weights each time to focus on problematic examples. As an example, it is used to classify 10 points into two classes by generating weak classifiers at each step that focus on the misclassified points from the previous step. AdaBoost achieves high precision but is sensitive to outliers.