Download as PDF, PPTX





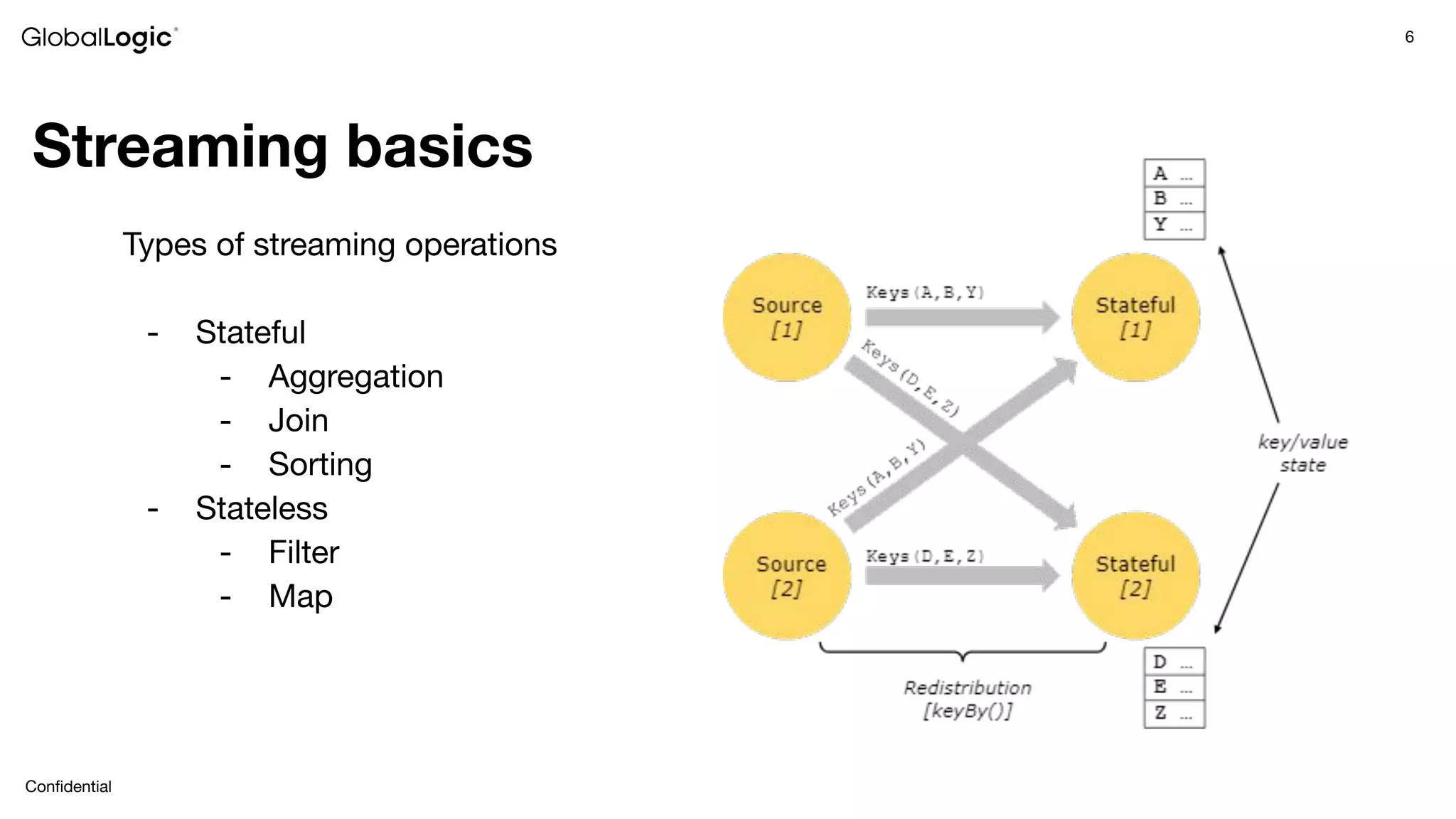


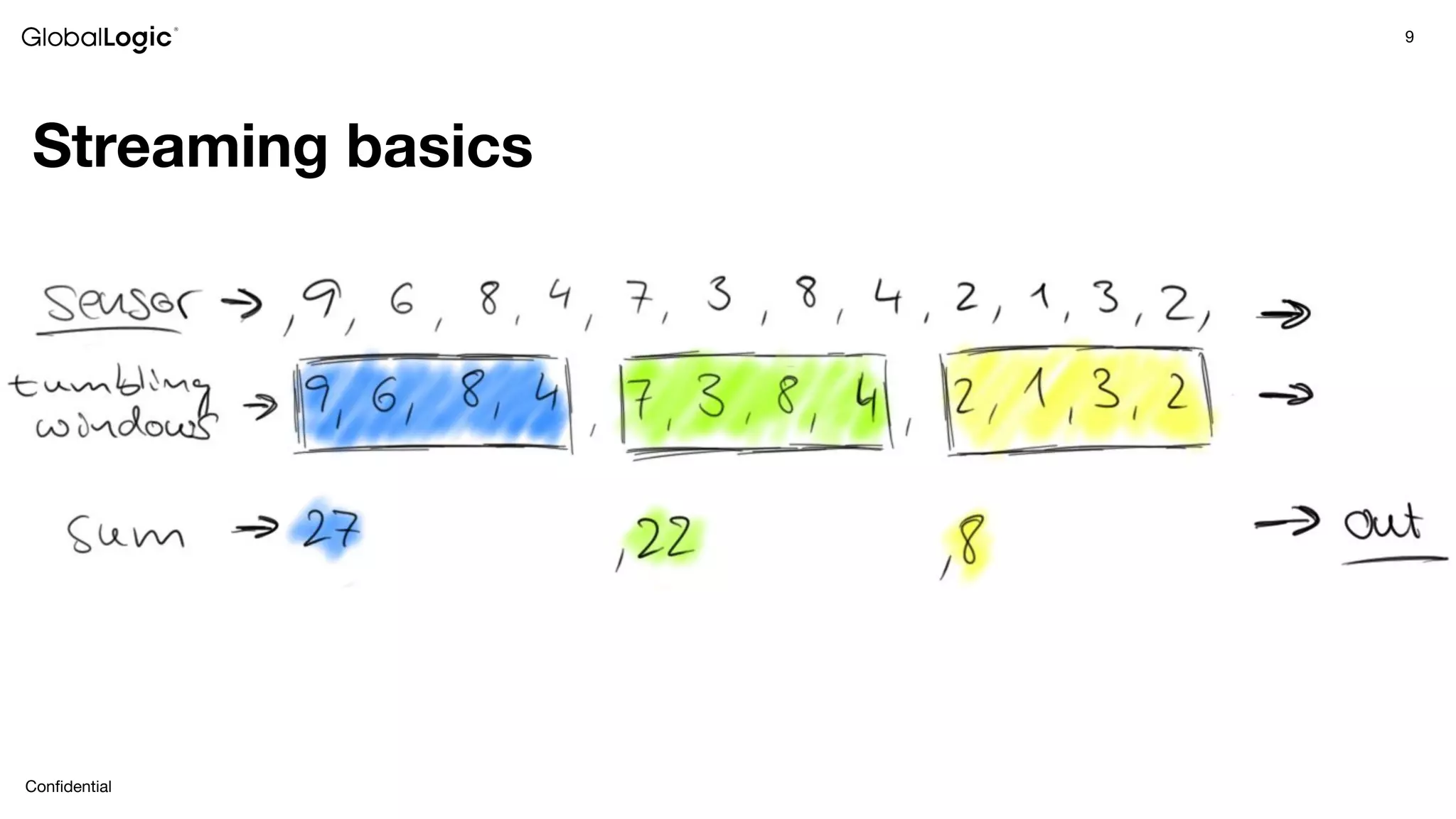
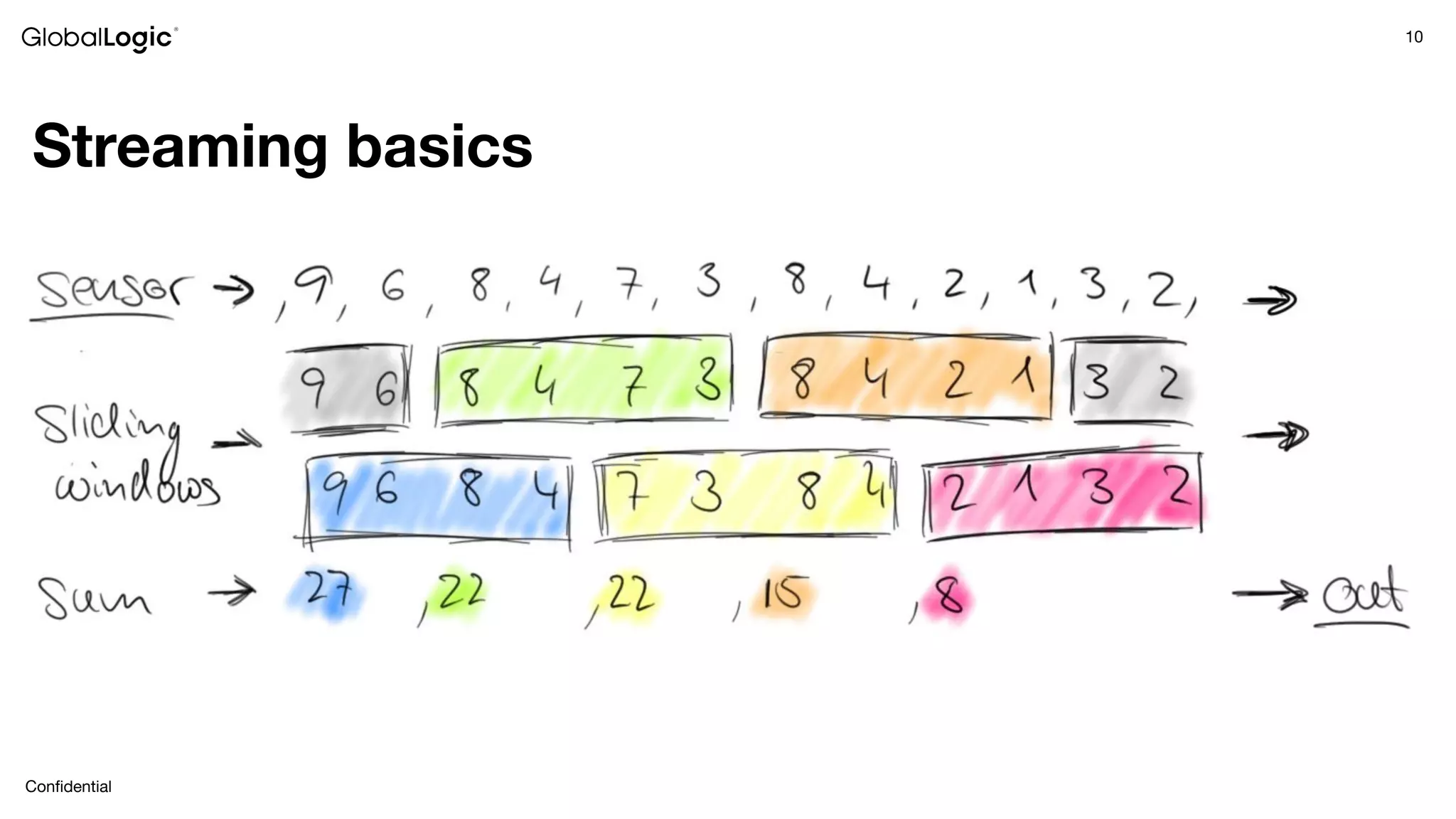
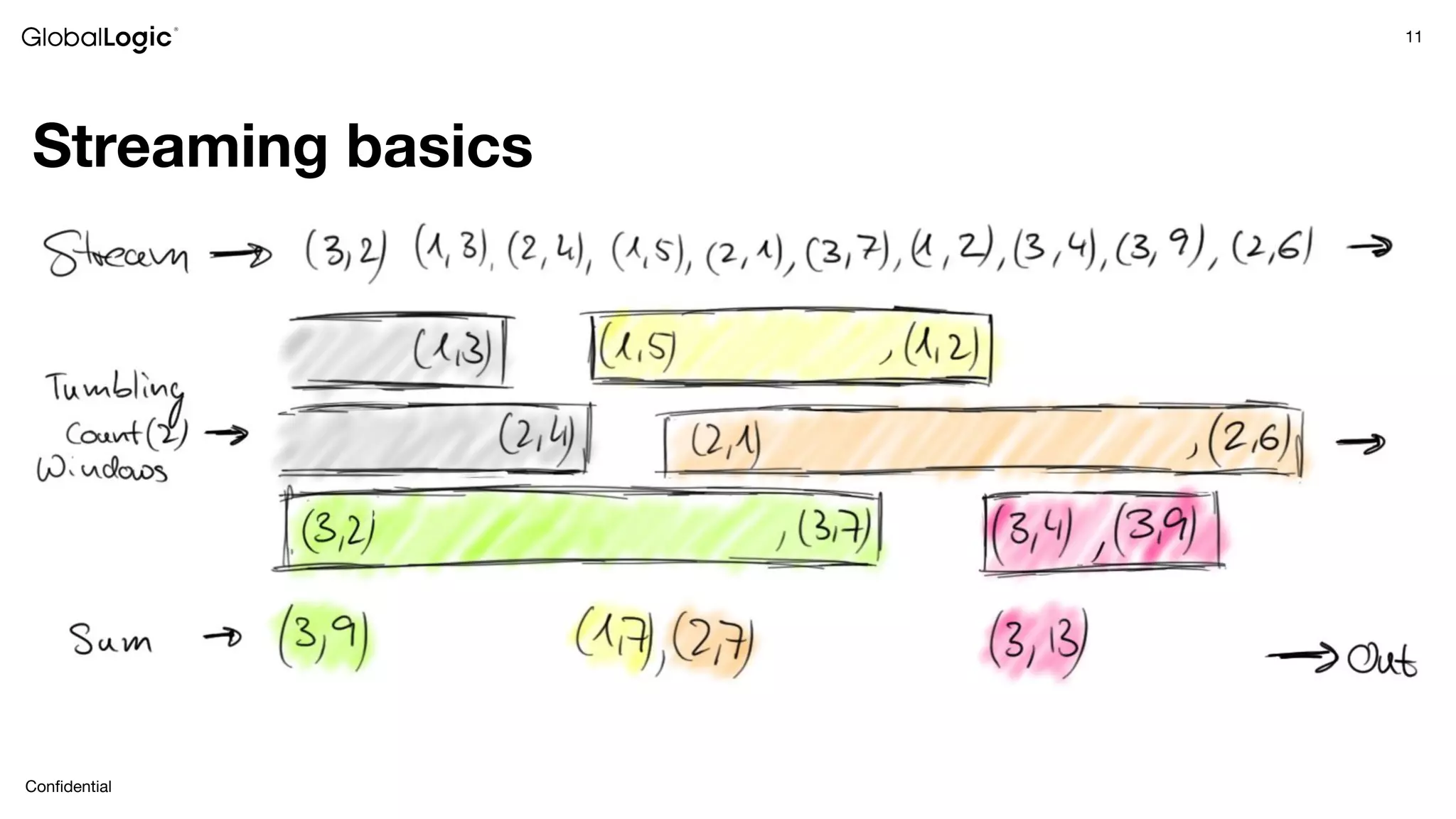





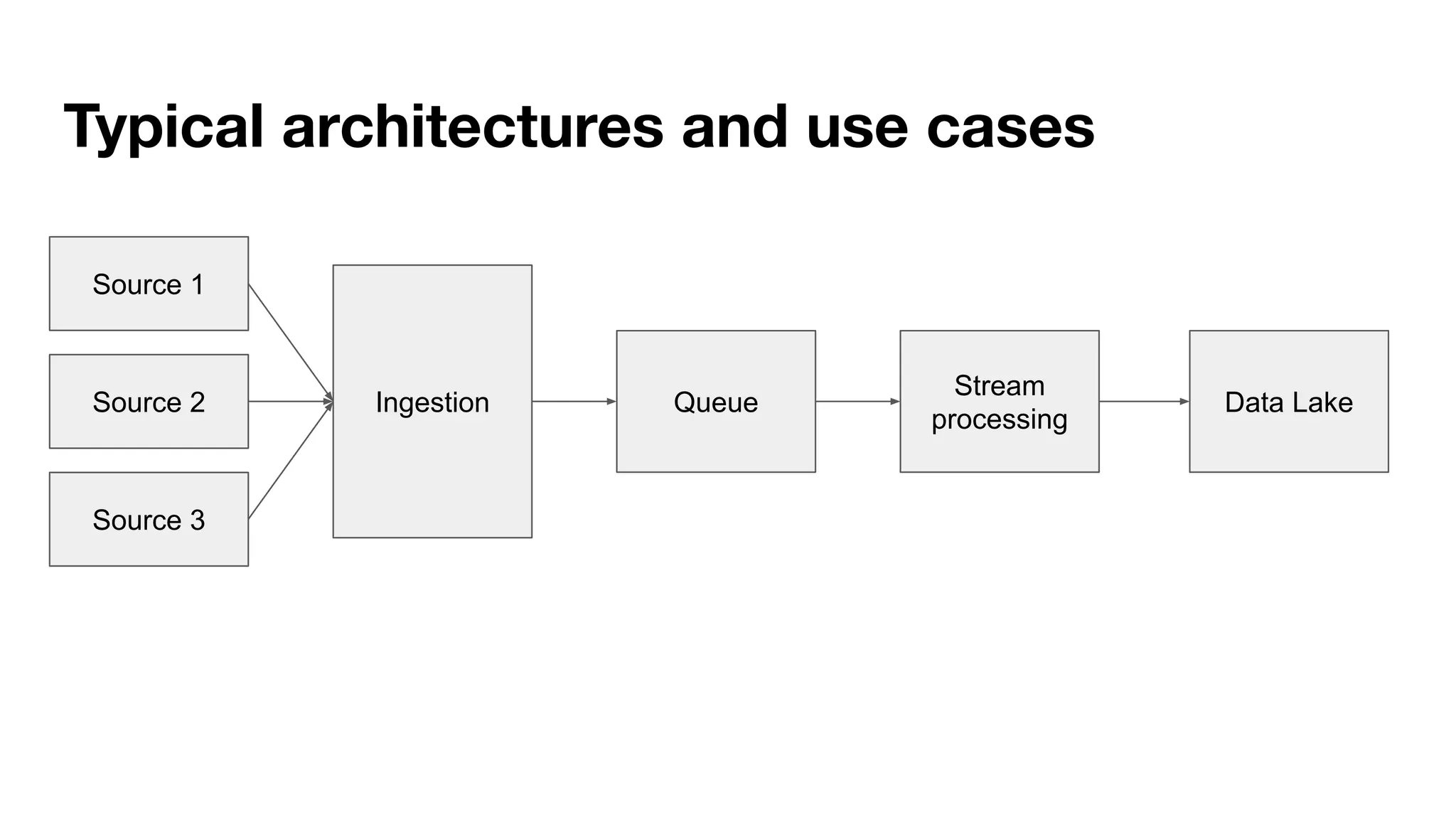
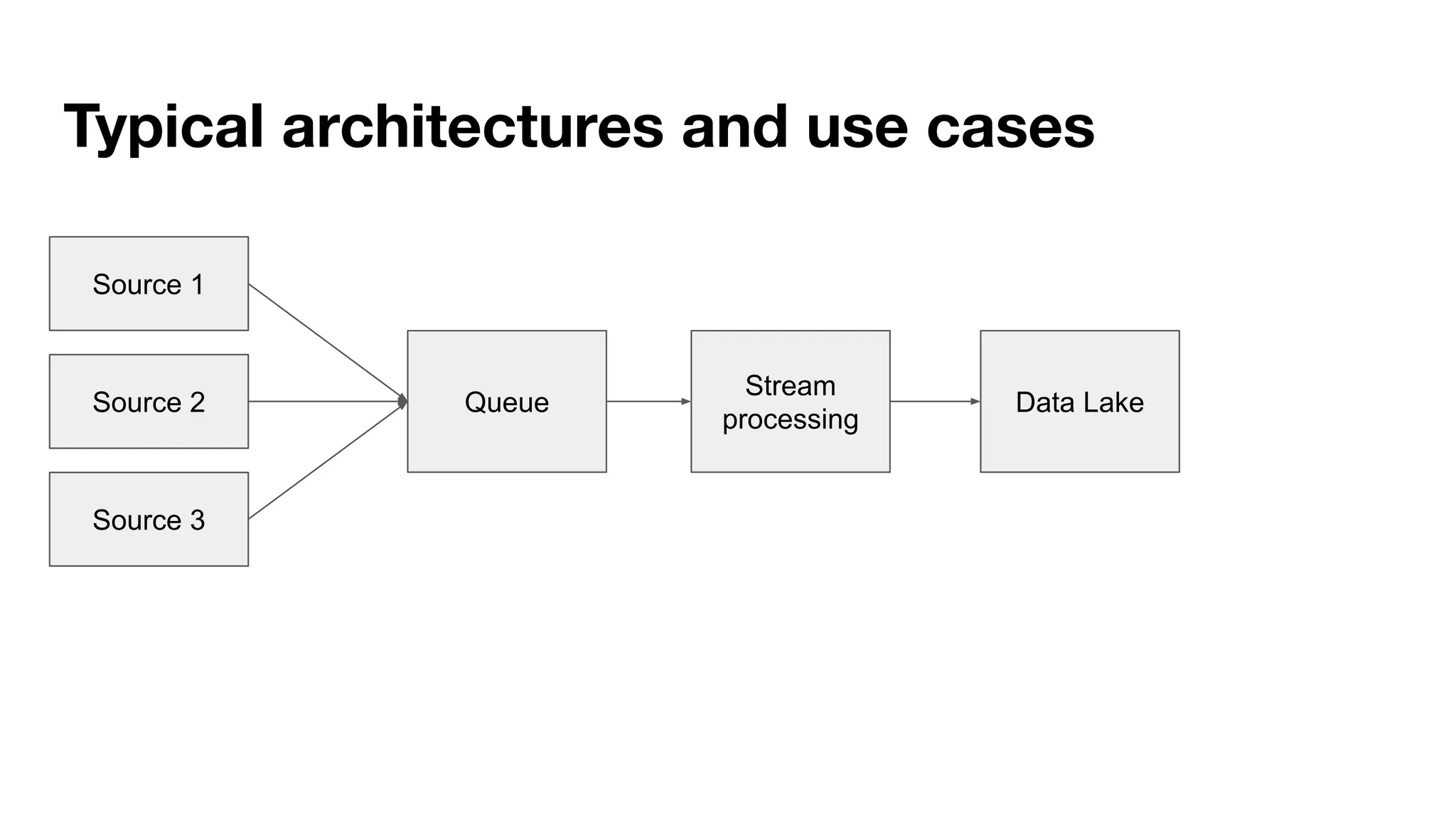
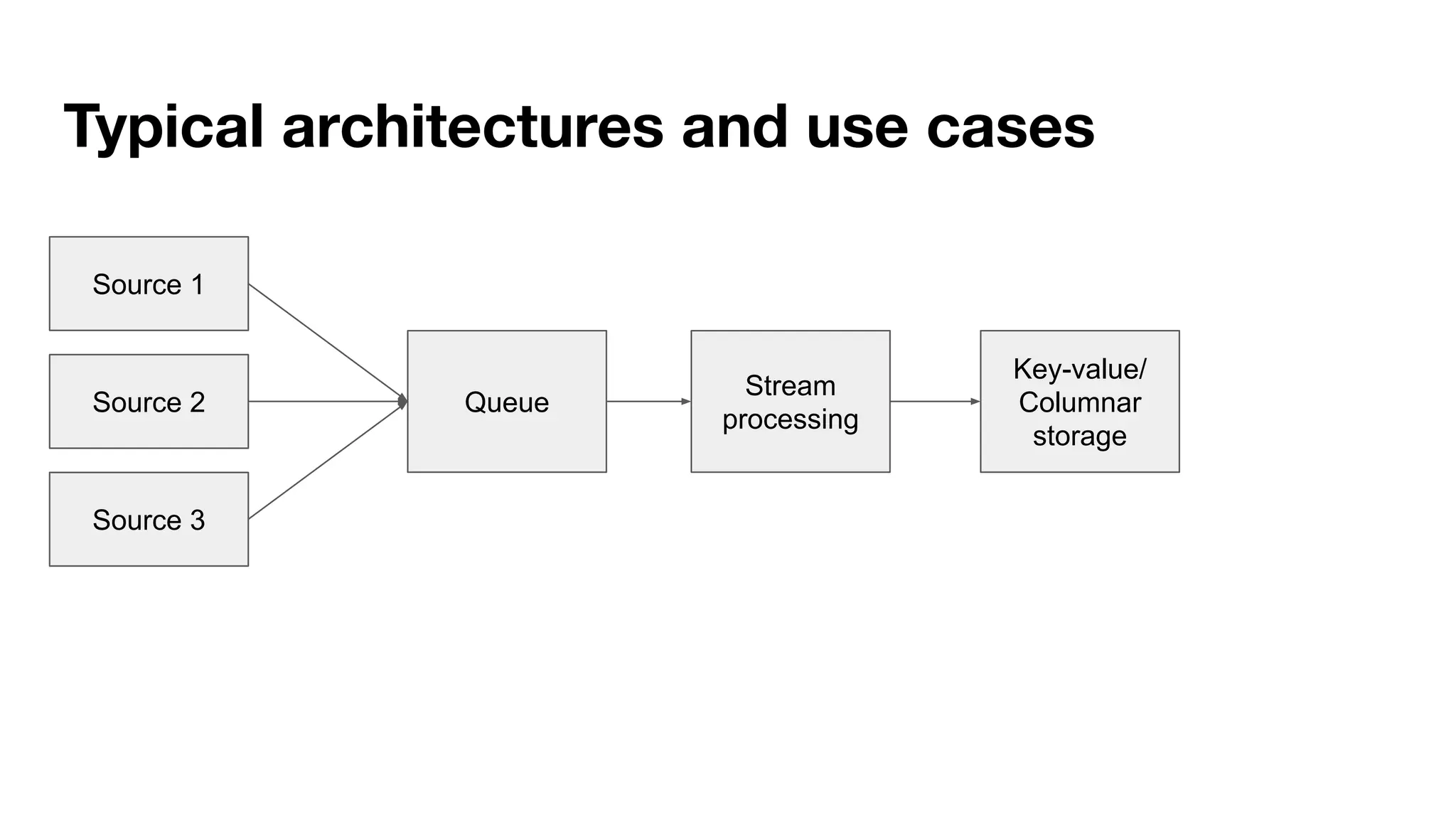
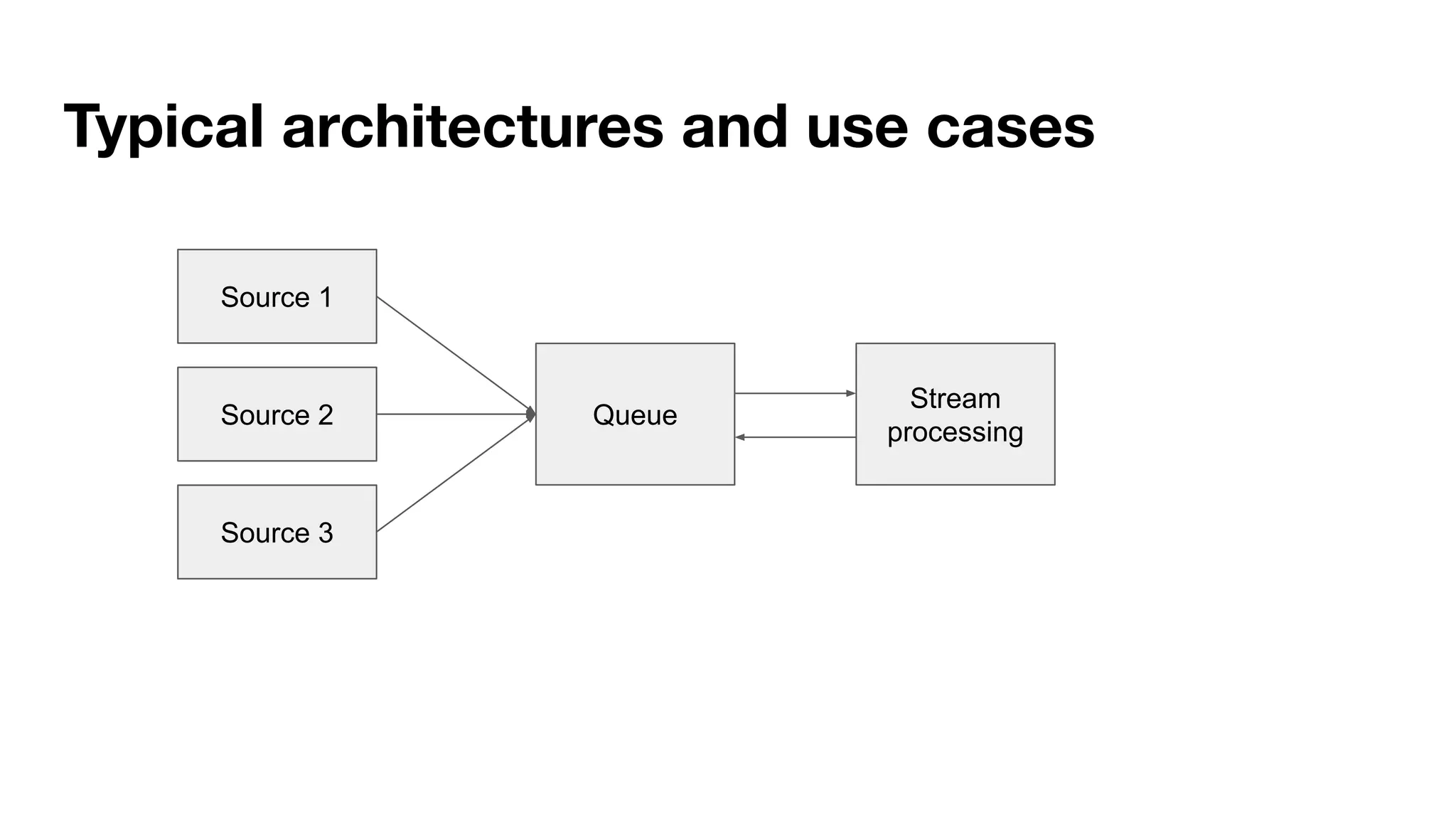
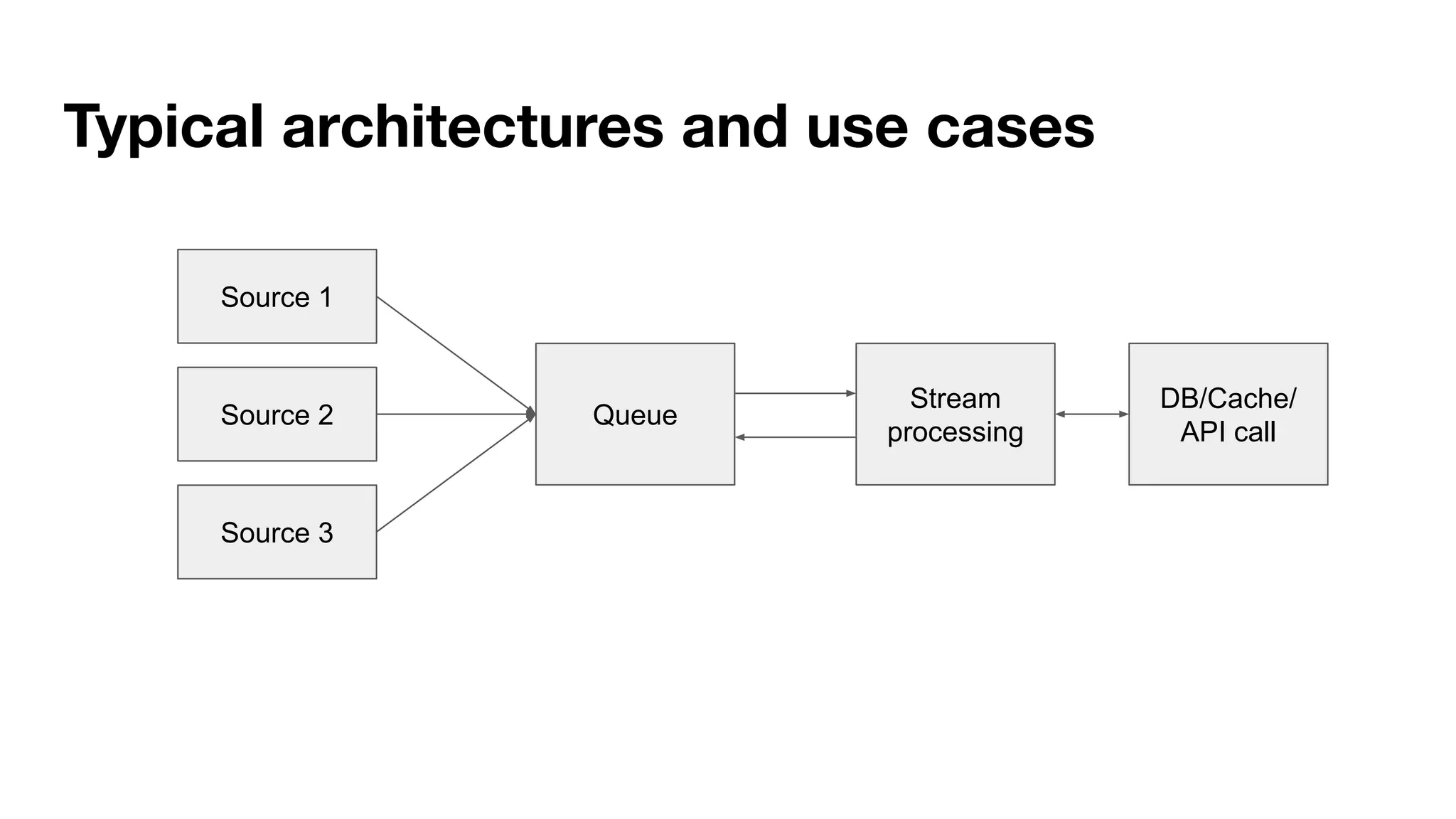











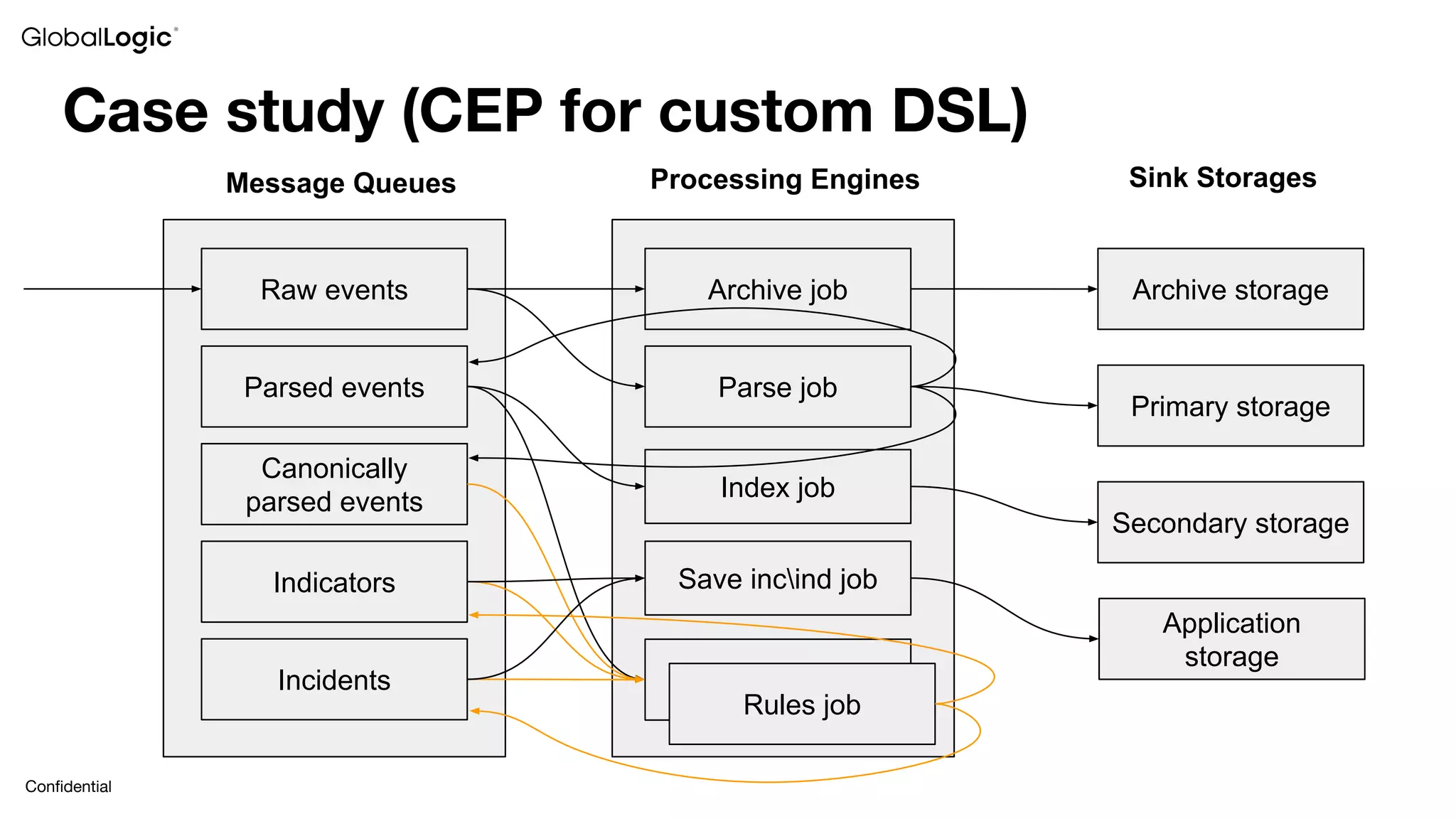




This document provides an overview of stream data processing and common stream processing tools. It discusses streaming basics like stateful and stateless operations. It also covers microbatch vs realtime streaming and compositional vs declarative stream processing engines. Typical stream processing architectures and use cases are presented. Main considerations for projects using stream processing are outlined. An overview of popular stream processing tools like Apache Spark, Storm, Flink, and cloud services from AWS, GCP and Azure is provided. The document concludes with a case study example and questions for discussion.








































![[WSO2Con EU 2018] The Rise of Streaming SQL](https://cdn.slidesharecdn.com/ss_thumbnails/1-181113084942-thumbnail.jpg?width=640&height=640&fit=bounds)














































