Downloaded 146 times








![@maasg www. .com
DStream[T]
RDD[T] RDD[T] RDD[T] RDD[T] RDD[T]
t0 t1 t2 t3 ti ti+1
Spark Streaming](https://image.slidesharecdn.com/diveintosparkstreamingspark-bemeetup-170312222559/85/Dive-into-Spark-Streaming-15-320.jpg)
![@maasg www. .com
DStream[T]
RDD[T] RDD[T] RDD[T] RDD[T] RDD[T]
t0 t1 t2 t3 ti ti+1
RDD[U] RDD[U] RDD[U] RDD[U] RDD[U]
Transformations
Spark Streaming](https://image.slidesharecdn.com/diveintosparkstreamingspark-bemeetup-170312222559/85/Dive-into-Spark-Streaming-16-320.jpg)
![@maasg www. .com
DStream[T]
RDD[T] RDD[T] RDD[T] RDD[T] RDD[T]
t0 t1 t2 t3 ti ti+1
RDD[U] RDD[U] RDD[U] RDD[U] RDD[U]
Actions
Transformations
Spark Streaming](https://image.slidesharecdn.com/diveintosparkstreamingspark-bemeetup-170312222559/85/Dive-into-Spark-Streaming-17-320.jpg)
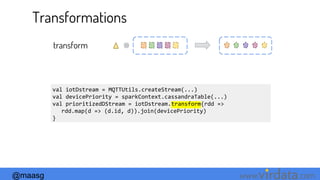





![@maasg www. .com
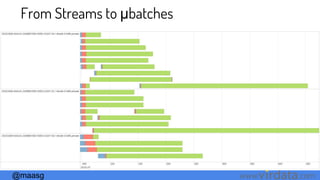
Windows - Inverse Function Optimization
reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval,[numTasks])
1 2 3 4 5 6 7 8 9
1,2,3,4,5,6
+
+ -](https://image.slidesharecdn.com/diveintosparkstreamingspark-bemeetup-170312222559/85/Dive-into-Spark-Streaming-32-320.jpg)
![@maasg www. .com
Windows- Inverse Function Optimization
reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval,[numTasks])
1 2 3 4 5 6 7 8 9
1,2,3,4,5,6
4,5,6,7,8,9
-
+ -
+ 7 8 9
1 2 3](https://image.slidesharecdn.com/diveintosparkstreamingspark-bemeetup-170312222559/85/Dive-into-Spark-Streaming-33-320.jpg)




![@maasg www. .com
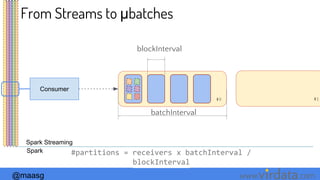
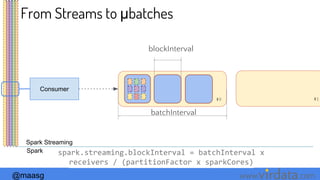
Deployment Options
M
Local
Standalone
Cluster
WW W
Using a Cluster
Manager
W
spark.master=local[*] spark.master=spark://host:port spark.master=mesos://host:port
M
M
D
W
D
W
W](https://image.slidesharecdn.com/diveintosparkstreamingspark-bemeetup-170312222559/85/Dive-into-Spark-Streaming-38-320.jpg)
![@maasg www. .com
Deployment Options
M
Local
Standalone
Cluster
Using a Cluster
Manager
spark.master=local[*] spark.master=mesos://host:port
M
M
DD
Rec
Exec
Rec
Exec
Exec
Exec
Rec
Exec
Rec
Exec
ExecExec
spark.master=spark://host:port](https://image.slidesharecdn.com/diveintosparkstreamingspark-bemeetup-170312222559/85/Dive-into-Spark-Streaming-39-320.jpg)



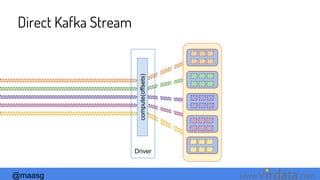
![@maasg www. .com
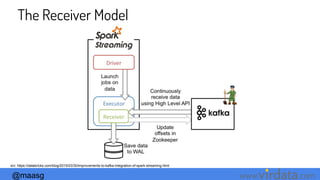
Kafka:The Receiver-less model
Simplified Parallelism
Efficiency
Exactly-once semantics
Less degrees of freedom
val directKafkaStream =
KafkaUtils.createDirectStream[
[key class],
[value class],
[key decoder class],
[value decoder class] ](
streamingContext, [map of Kafka parameters], [set
of topics to consume]
)
spark.streaming.kafka.maxRatePerPartition](https://image.slidesharecdn.com/diveintosparkstreamingspark-bemeetup-170312222559/85/Dive-into-Spark-Streaming-56-320.jpg)







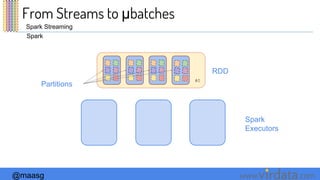
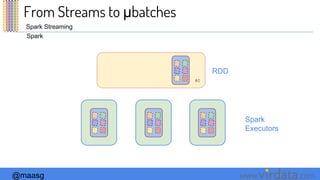
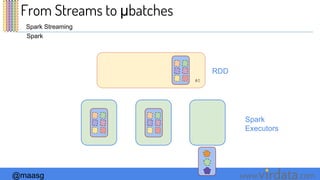
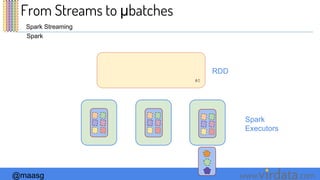
The document discusses Spark Streaming and its execution model. It describes how Spark Streaming receives data streams, divides them into micro-batches, and processes the micro-batches using Spark. It also covers transformations and actions that can be performed on DStreams, window operations, and deployment options for Spark Streaming including local, standalone, and cluster modes.























































































