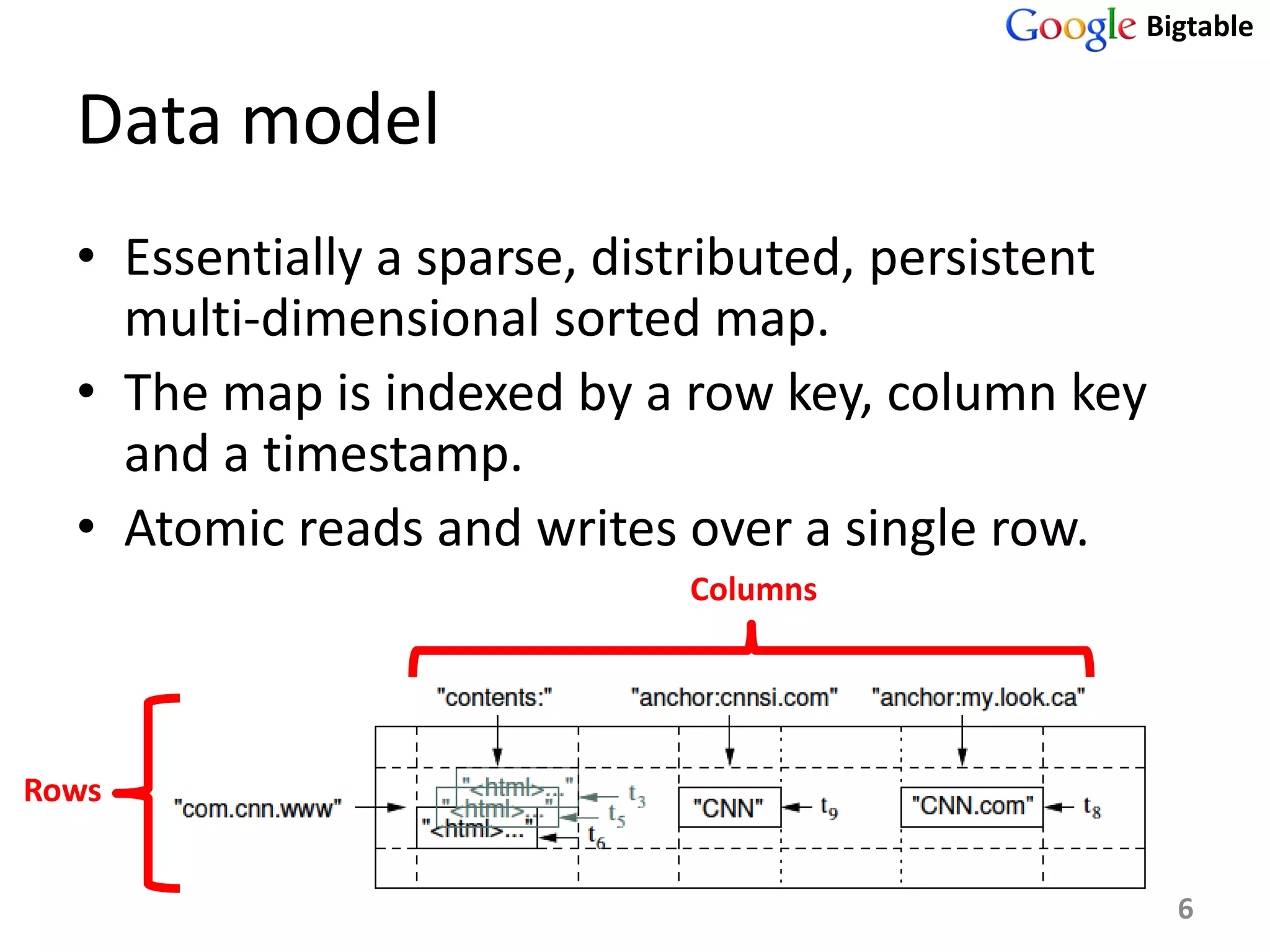
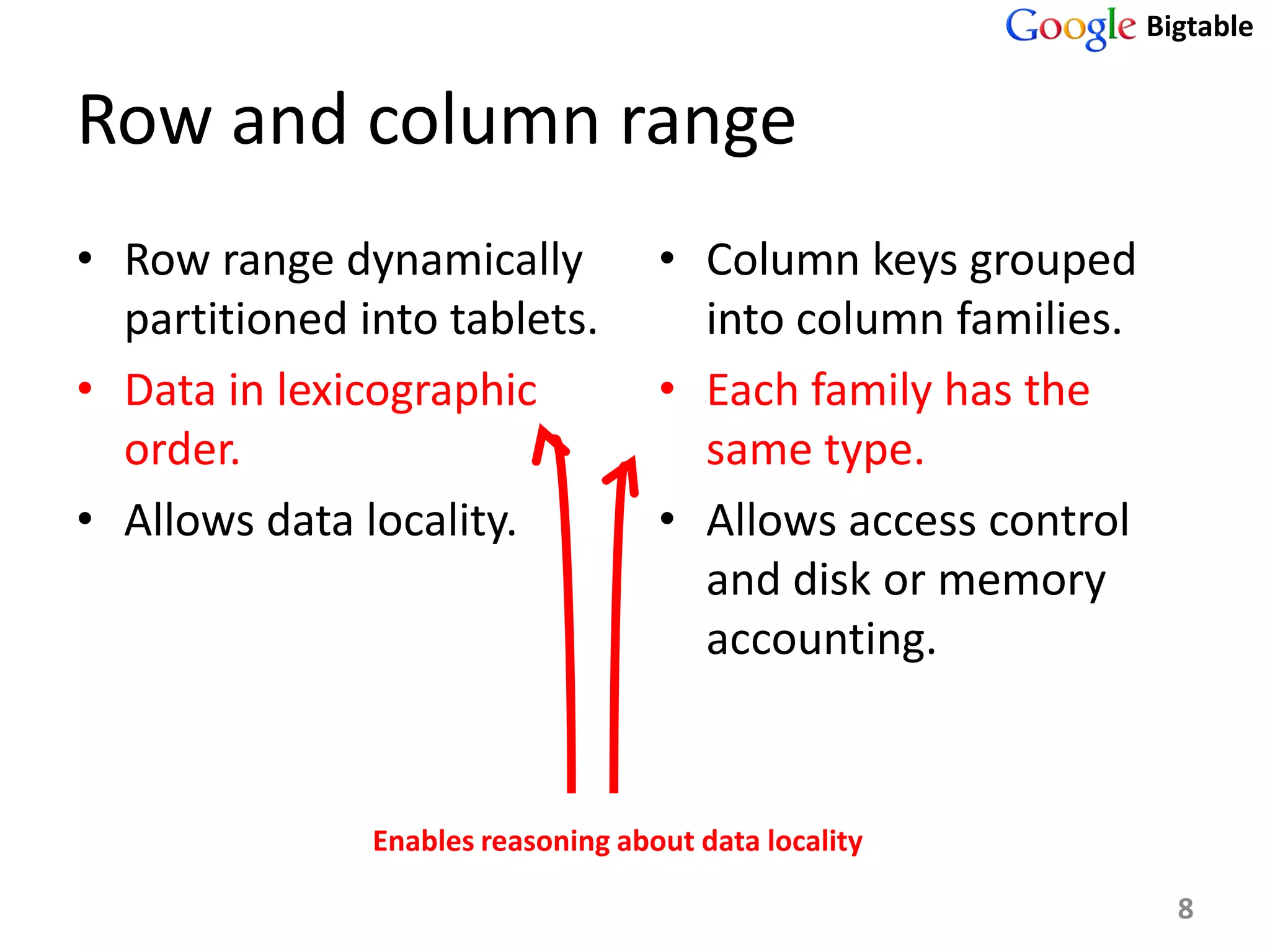
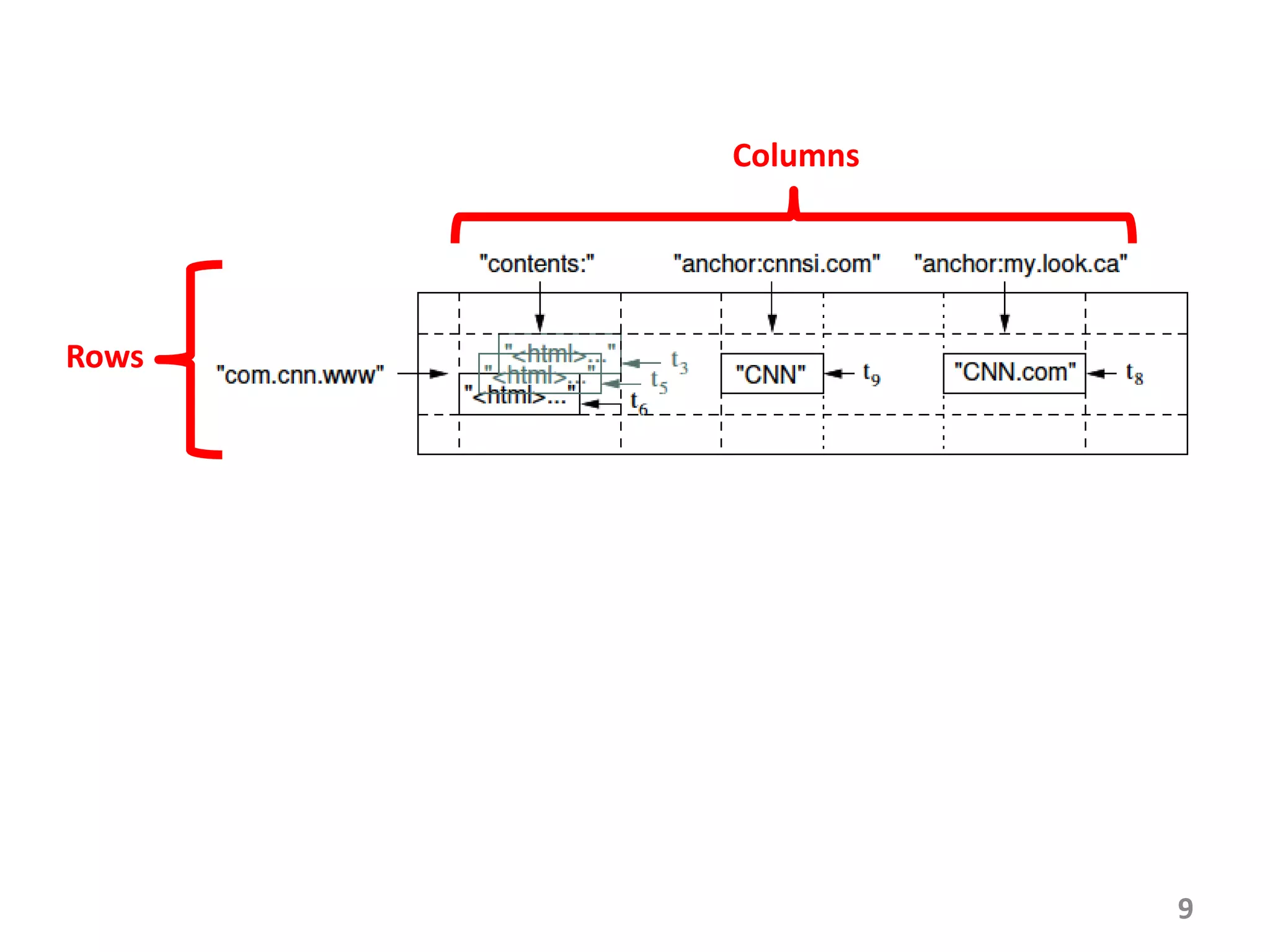
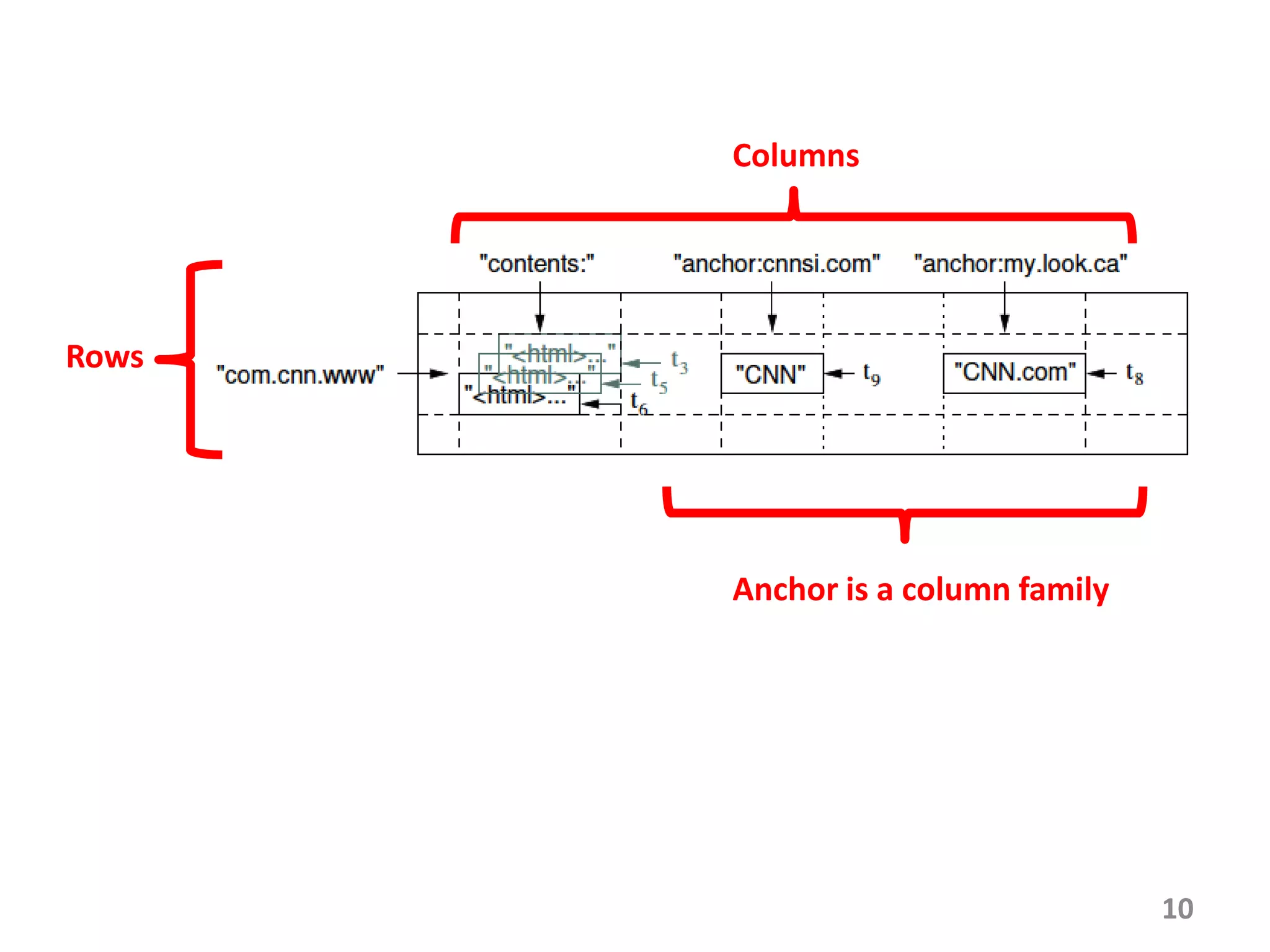
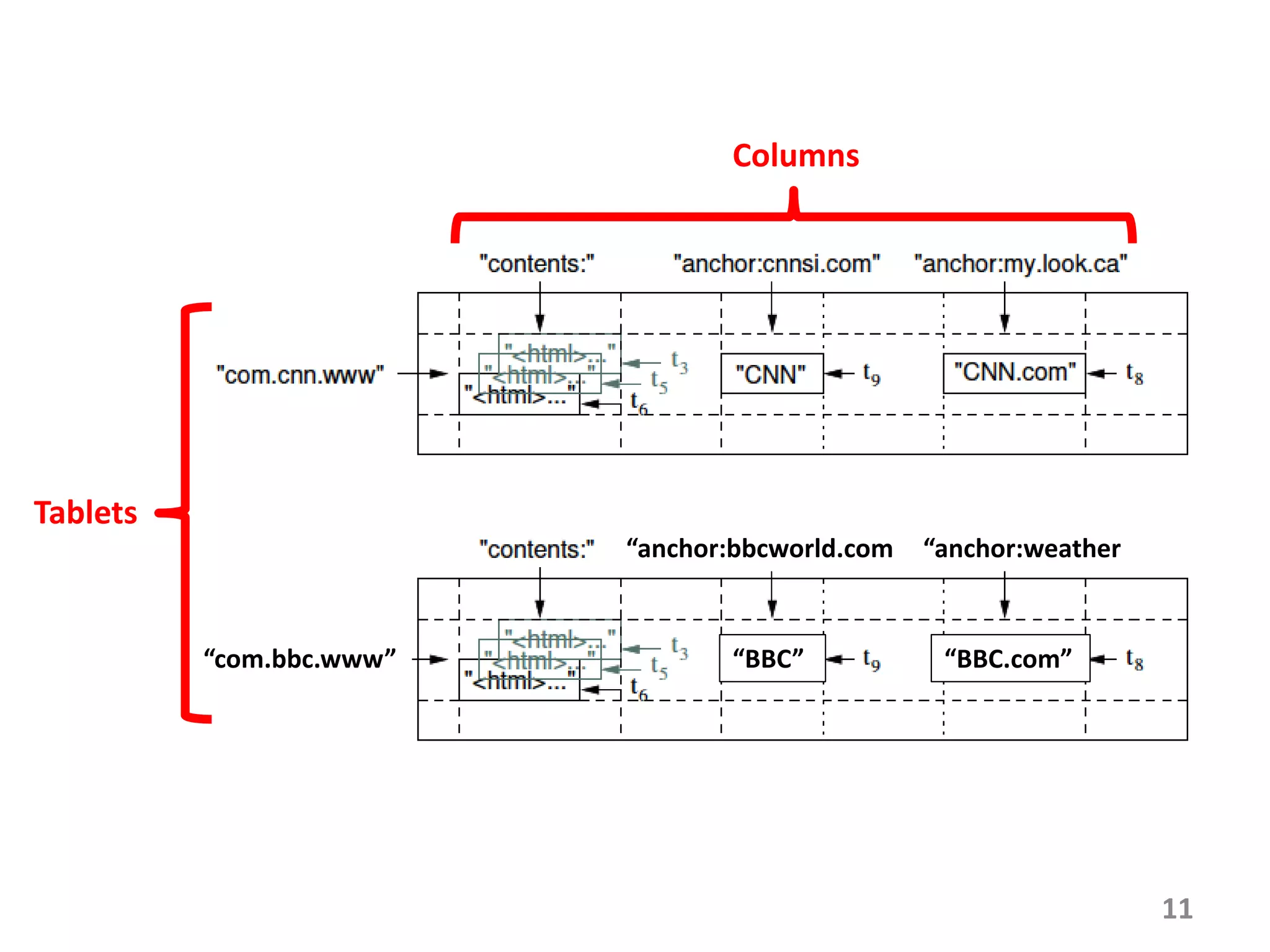
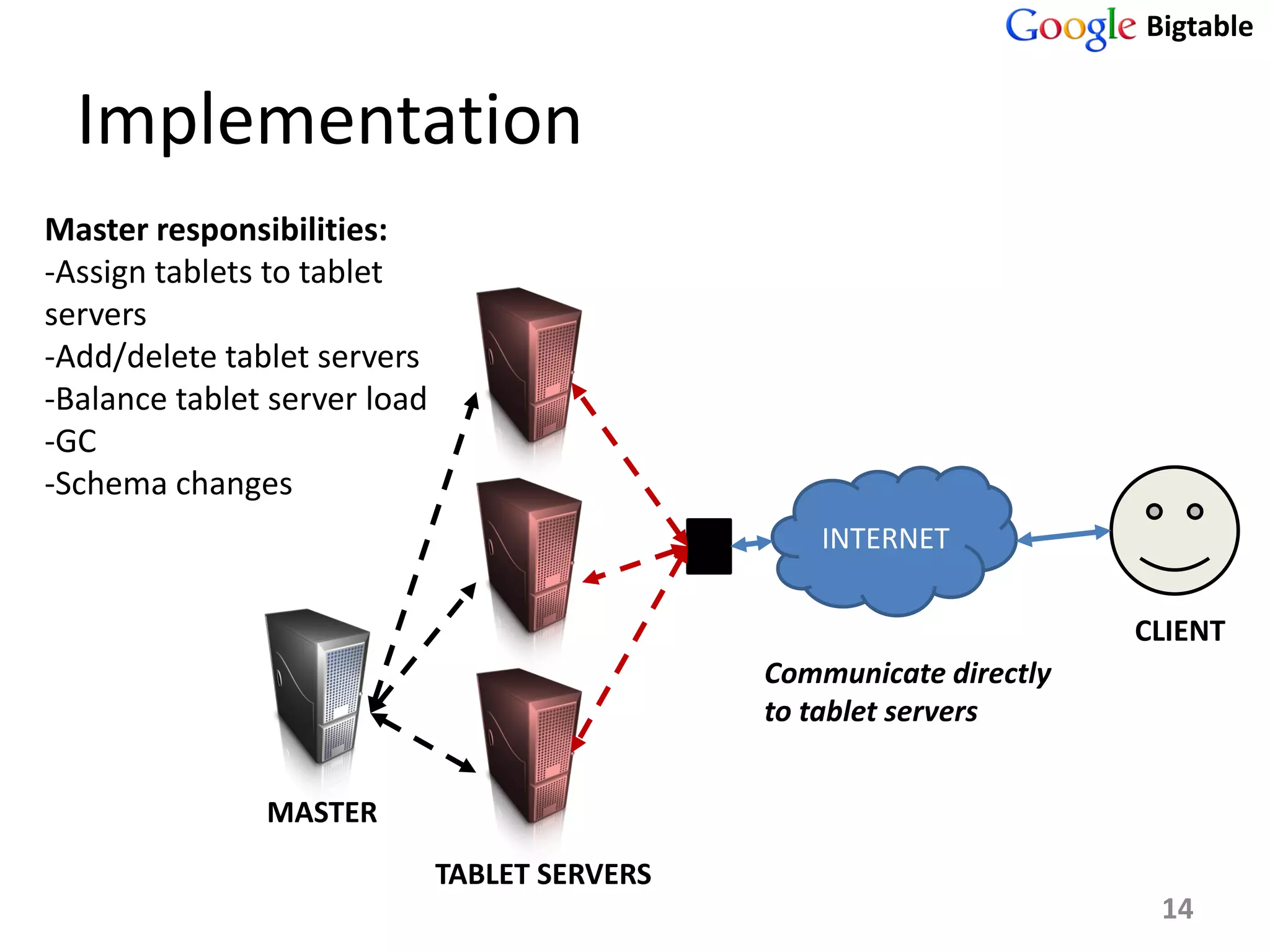
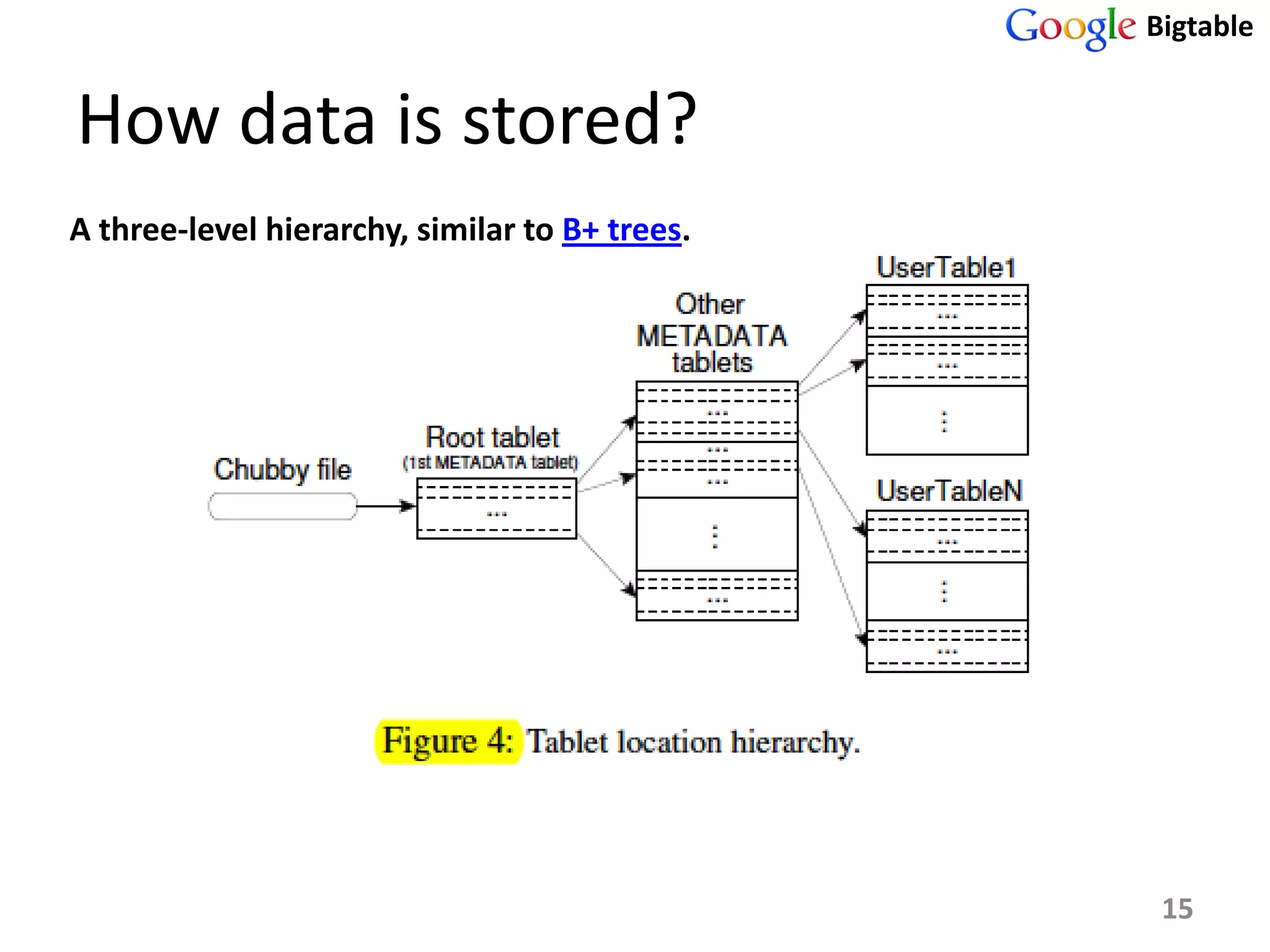
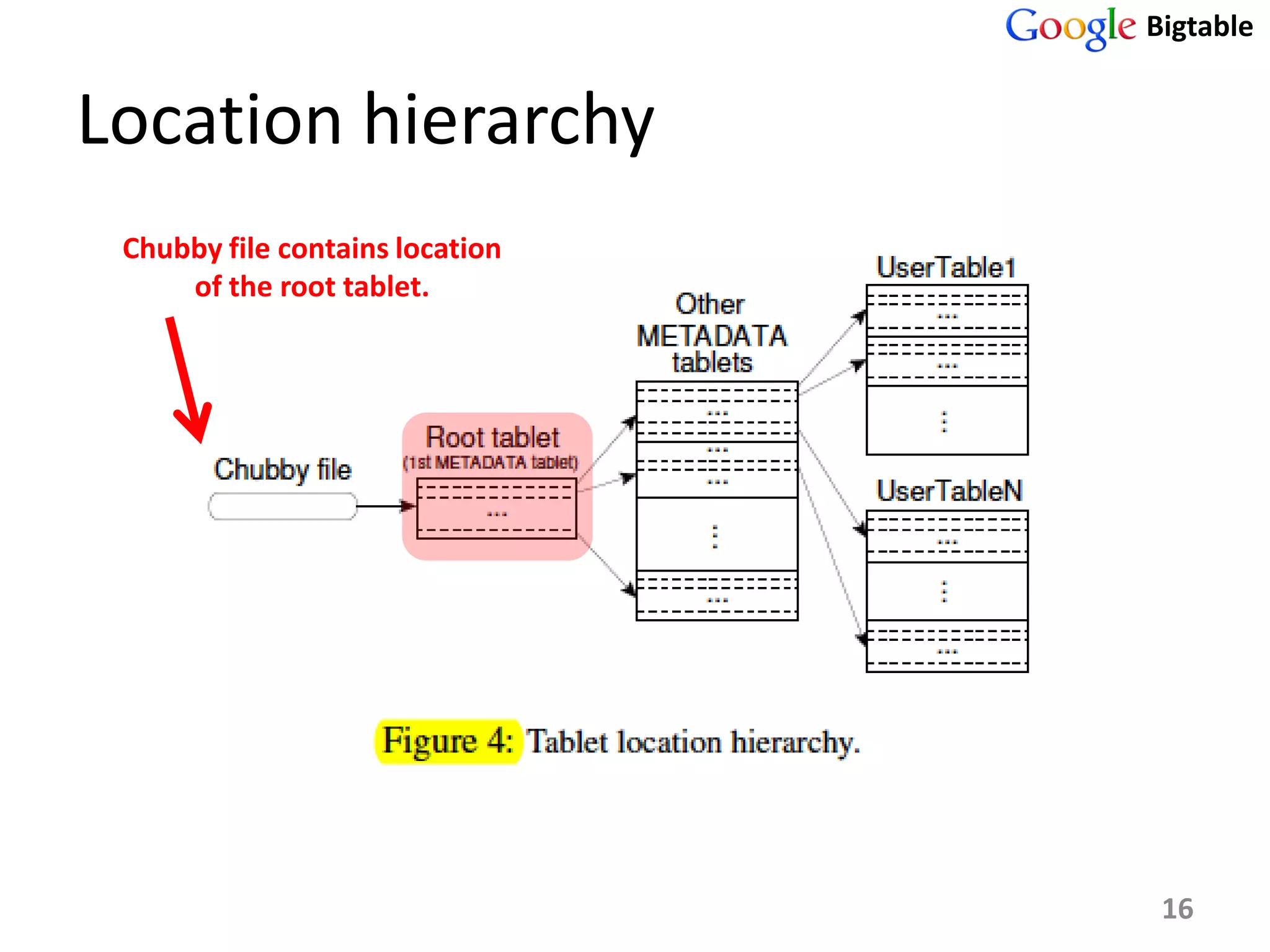
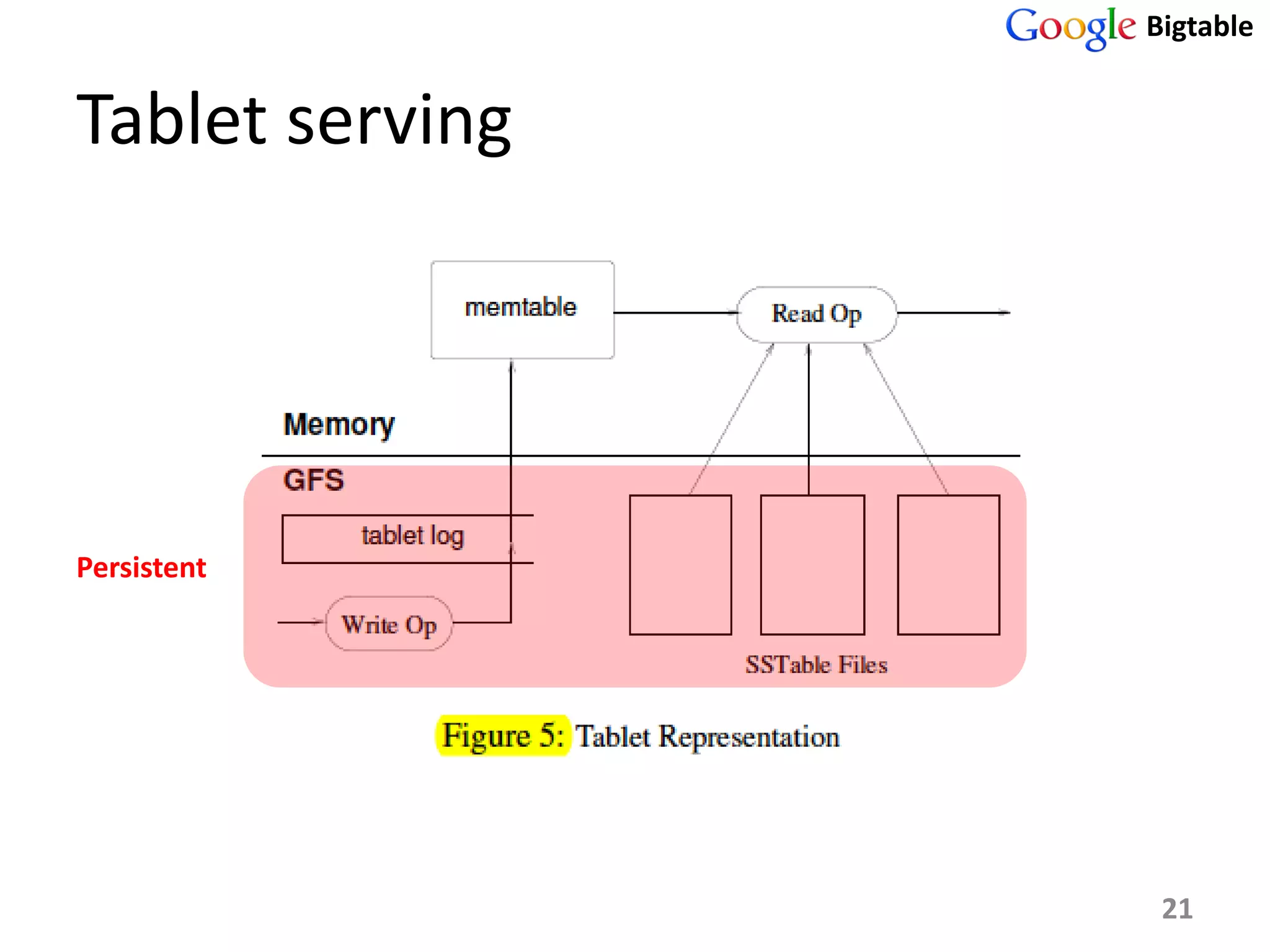
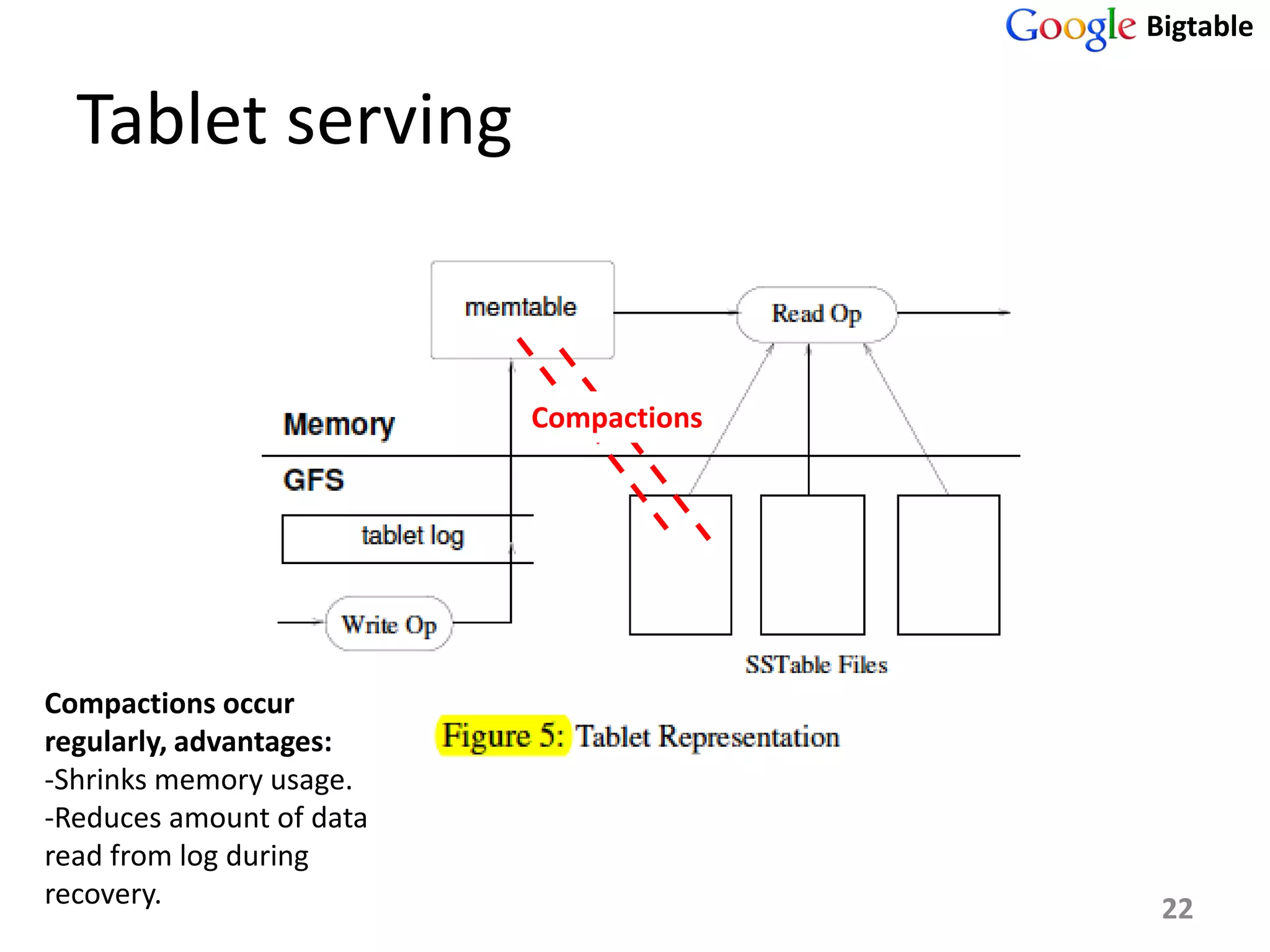
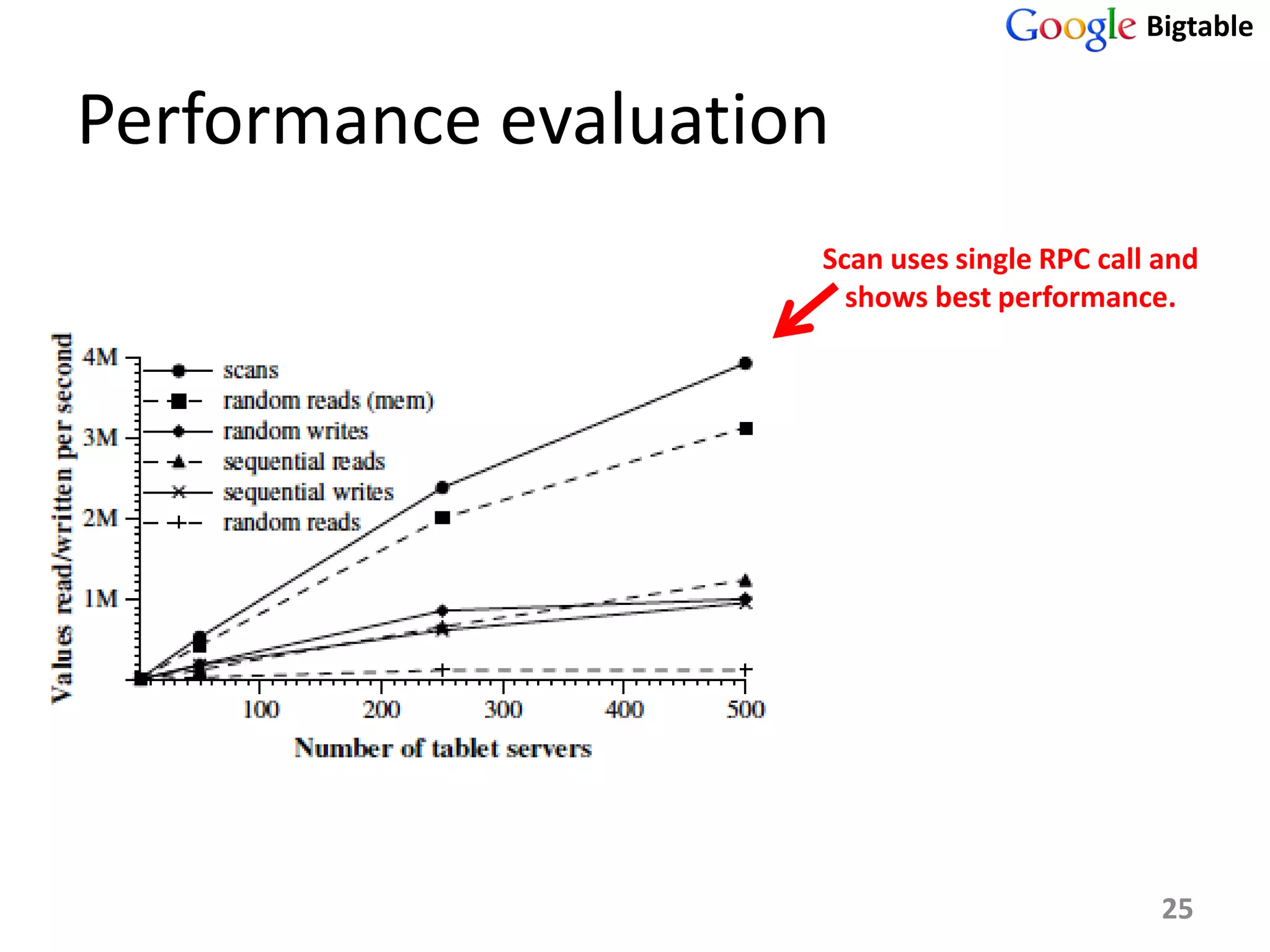
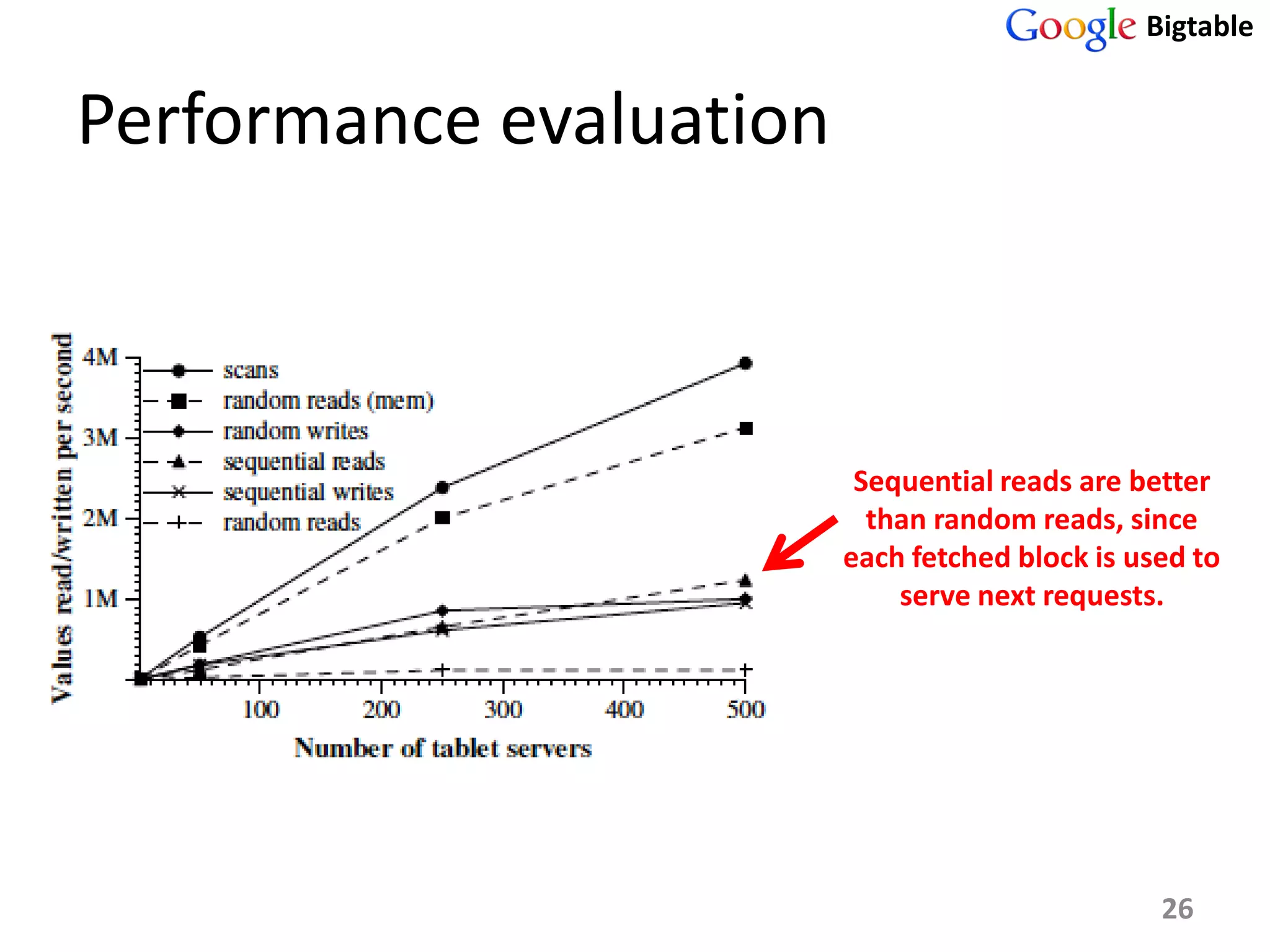
Bigtable is a distributed storage system for managing large structured datasets. It uses a sparse distributed multidimensional sorted map as its data model. Bigtable has been widely adopted by Google for applications requiring scalability, high performance, and high availability, serving over 60 Google products. It utilizes various technologies like the Google File System for storage and Chubby for coordination.

























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















