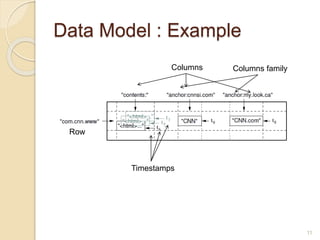
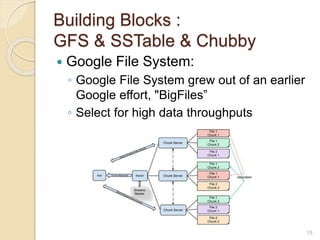
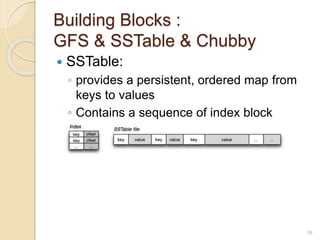
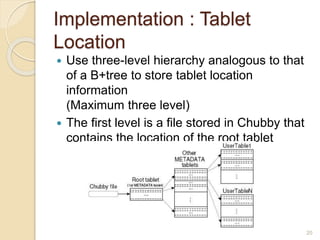
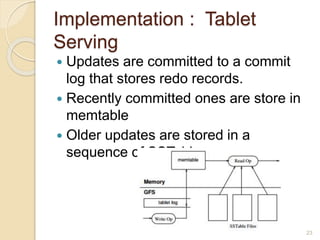
Bigtable is a distributed storage system designed to handle large amounts of structured data across thousands of commodity servers. It provides a simple "big table" abstraction with rows and columns that can be improved by adding additional columns and timestamps. Underneath, it uses Google's distributed file system GFS for storage and relies on the tablet server architecture and SSTable format to achieve high performance for millions of reads/writes per second and dynamic scaling.








































![[IBM 김상훈] 오브젝트스토리지 | 늘어만 가는 데이터 저장문제로 골 아프신가요? (자료를 다운로드하시면 고화질로 보실 수 있습니다.)](https://cdn.slidesharecdn.com/ss_thumbnails/2-181031090033-thumbnail.jpg?width=640&height=640&fit=bounds)



































































