Downloaded 374 times









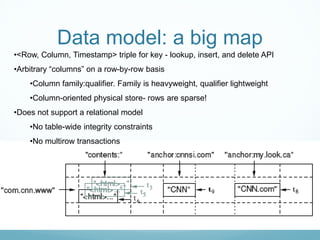

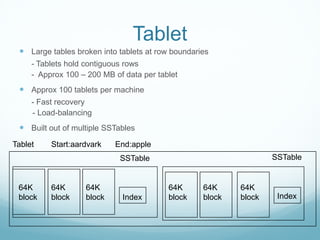
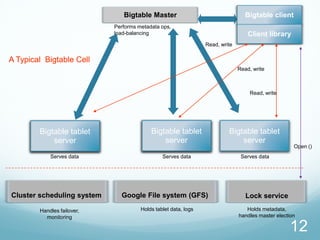
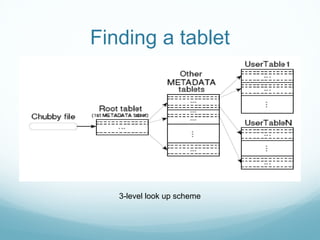


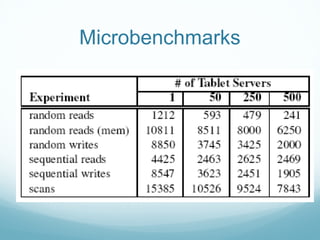
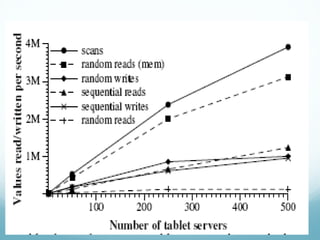
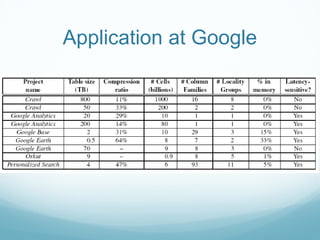



Google developed Bigtable to address the challenges of Google's massive scale of data storage and analysis needs. Bigtable is a distributed storage system that provides a flexible data model and can scale to petabytes of data across thousands of commodity servers. It uses a column-oriented data structure that allows for efficient storage of sparse datasets and flexible querying. Bigtable also provides features like replication, load balancing, and data compression to ensure high performance, fault tolerance, and manageability as data volumes continue growing rapidly over time.























































































