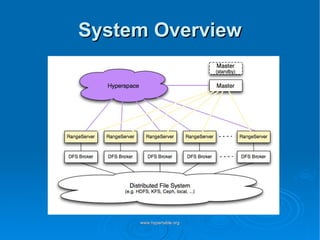
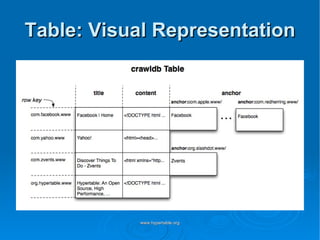
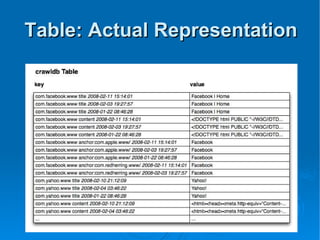
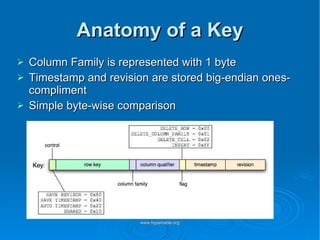
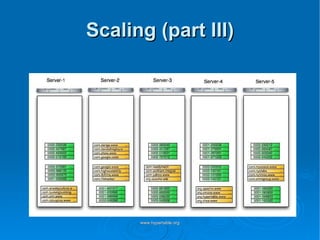
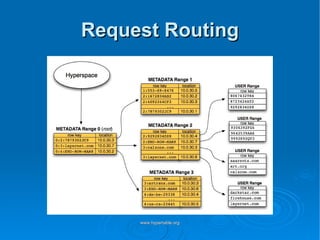
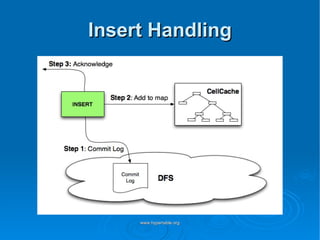
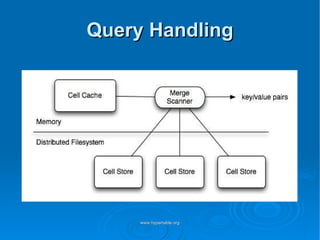
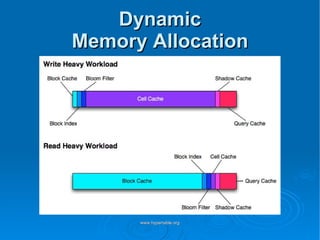
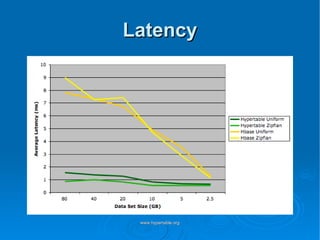
Doug Judd presents on Hypertable, an open source database modeled after Google's Bigtable that is massively scalable. Hypertable provides a sparse, multidimensional data model and scales horizontally across commodity hardware. Performance tests show Hypertable has latencies under 1 second and throughputs of hundreds of queries per second. Case studies include its use at Zvents for analytics and Rediffmail for spam classification of millions of requests daily.



































![[Pgday.Seoul 2018] PostgreSQL 성능을 위해 개발된 라이브러리 OS 소개 apposha](https://cdn.slidesharecdn.com/ss_thumbnails/06-pgdayseoul2018sangwook-181112042505-thumbnail.jpg?width=640&height=640&fit=bounds)



































