Download as PDF, PPTX






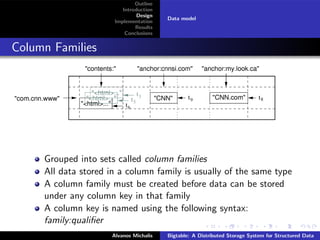











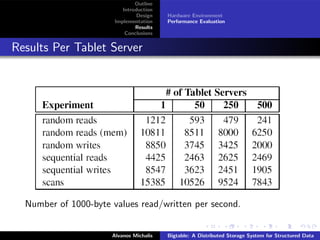



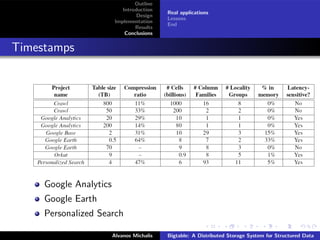



This document summarizes a research paper on Bigtable, a distributed storage system from Google. Bigtable stores data in sparse, distributed, and persistent multidimensional sorted maps, indexed by row key, column key, and timestamp. It is designed to be scalable, fault-tolerant and handle massive amounts of data across thousands of commodity servers. Bigtable breaks data into tablets that are assigned to tablet servers, and uses mechanisms like compaction and caching to improve performance and manage storage. The system has proven capable of high throughput at Google, handling petabytes of data.











































































































