Downloaded 85 times







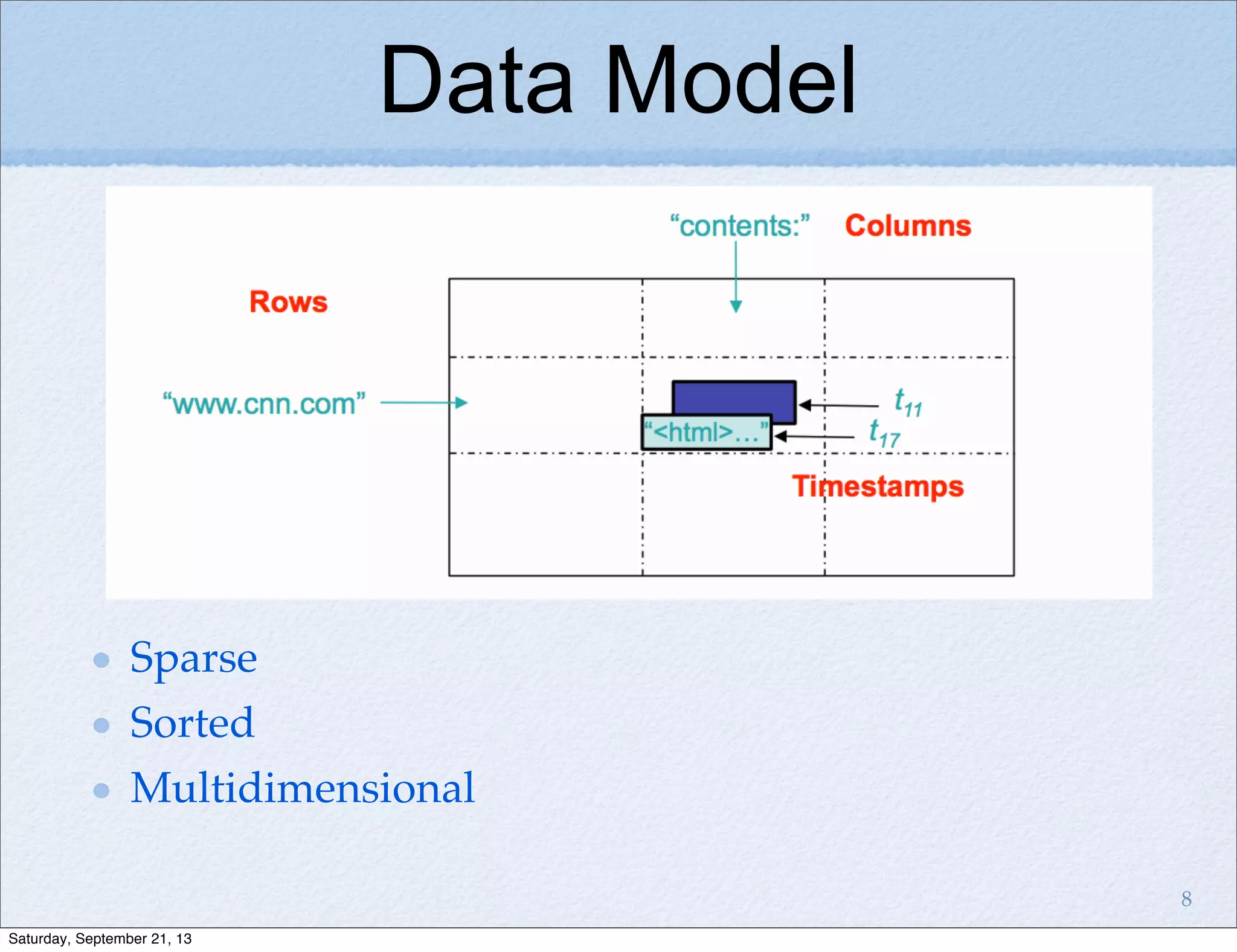



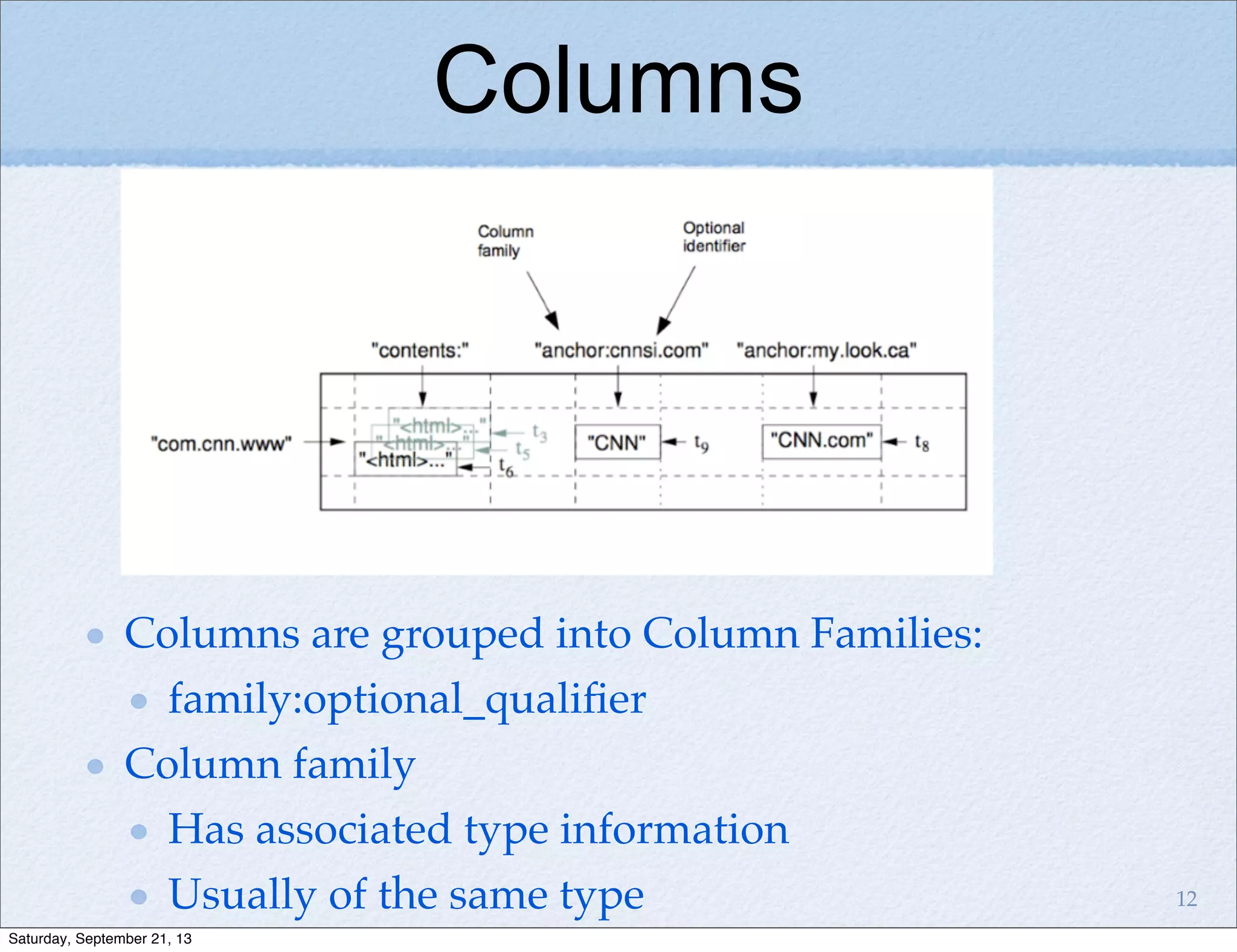




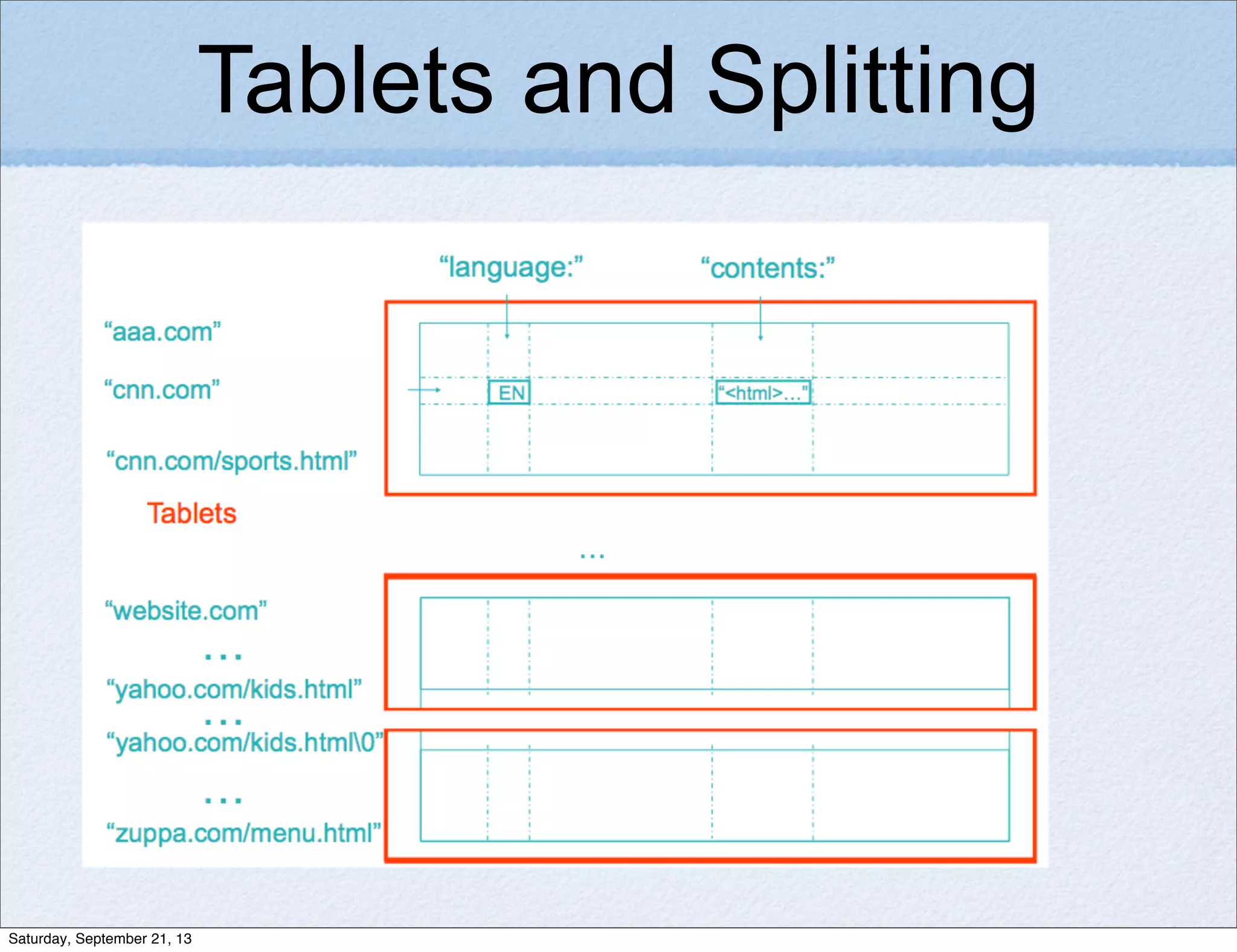

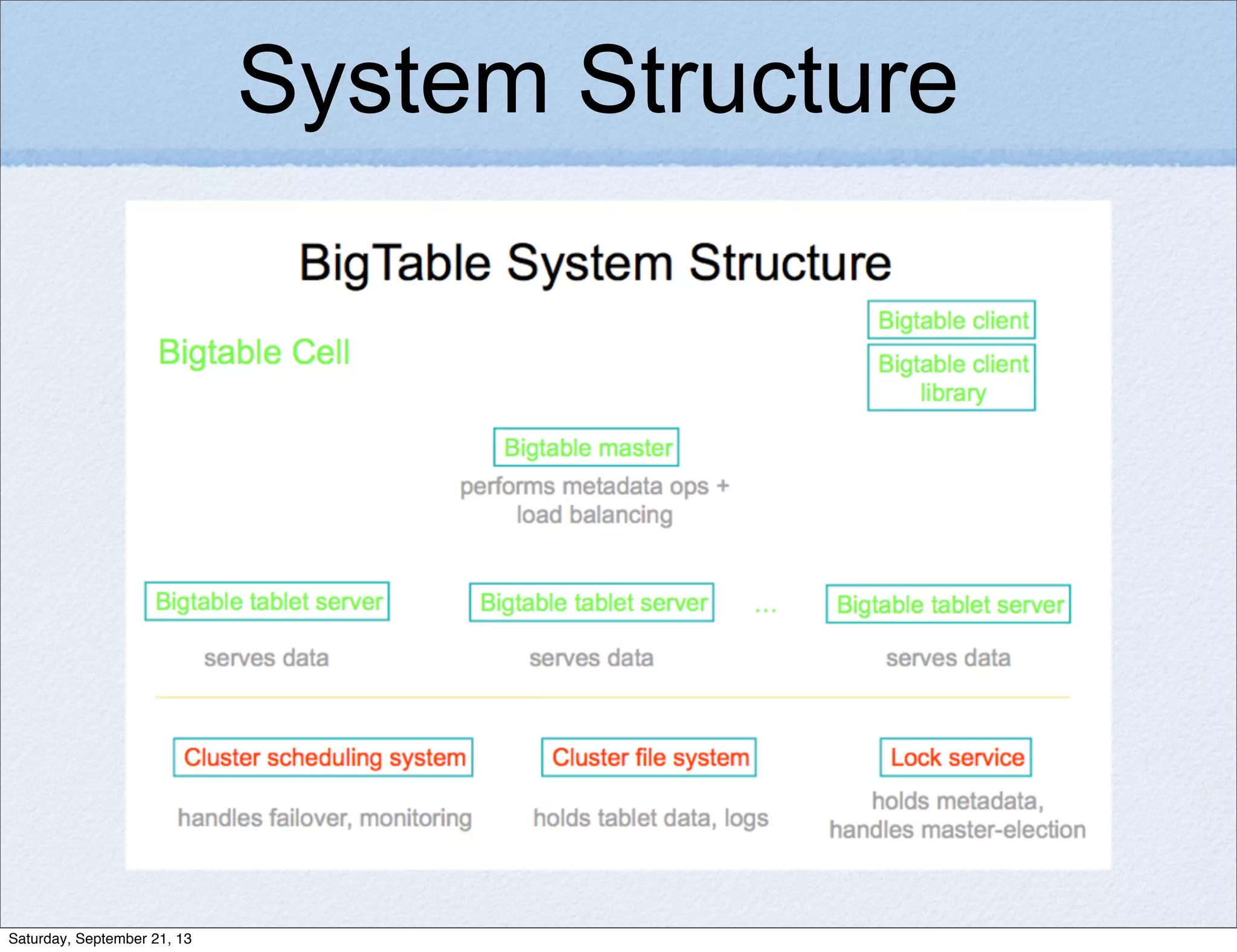
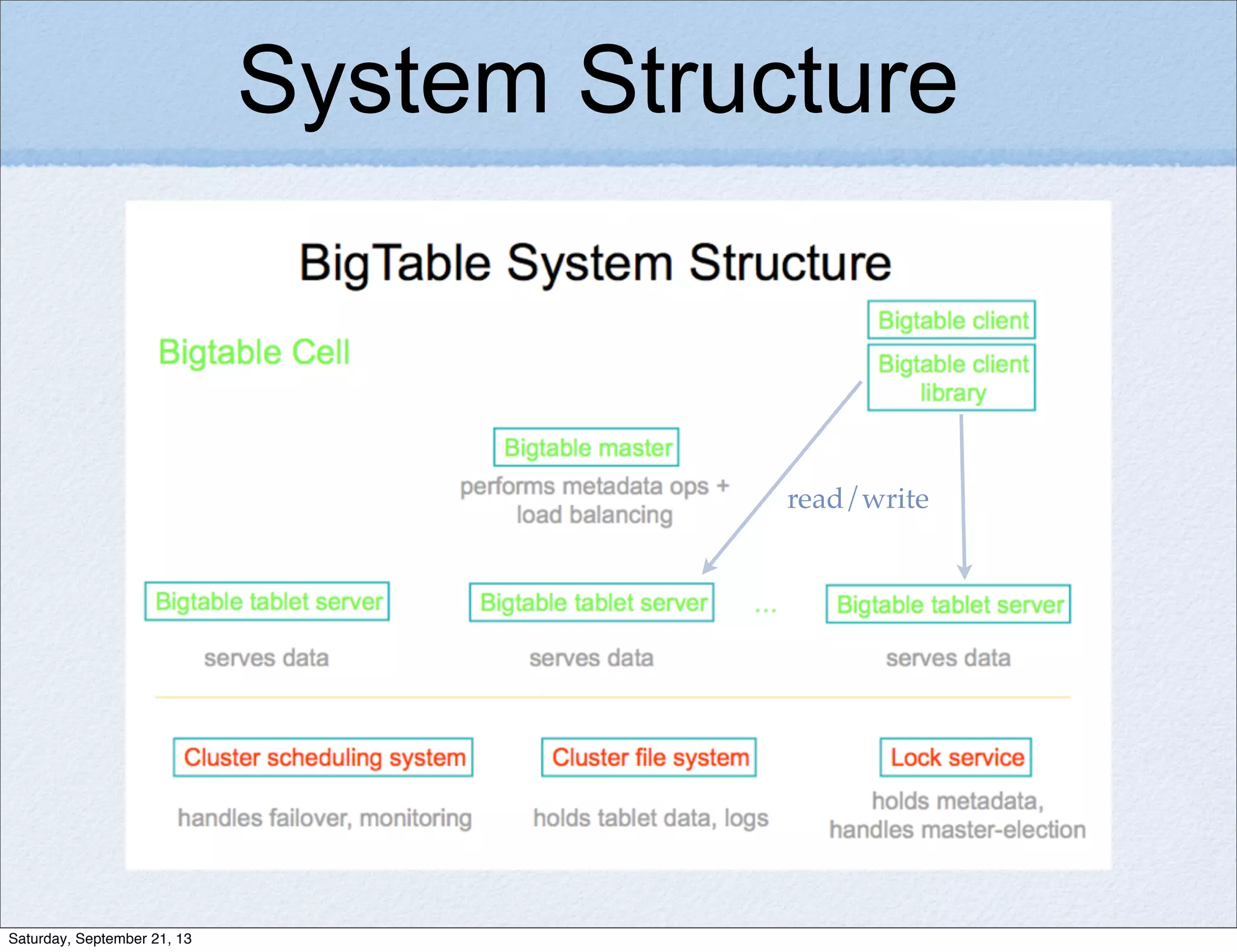
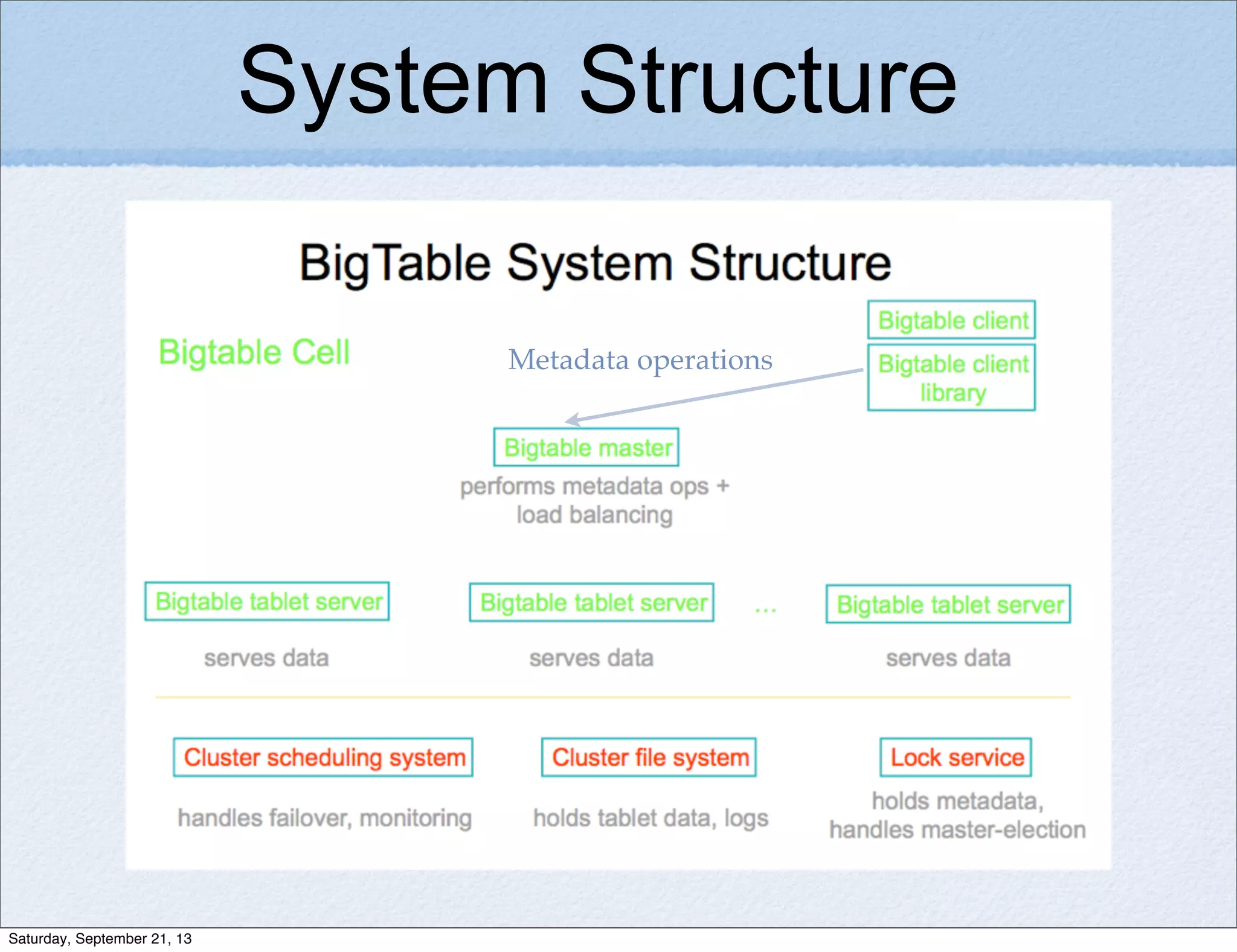
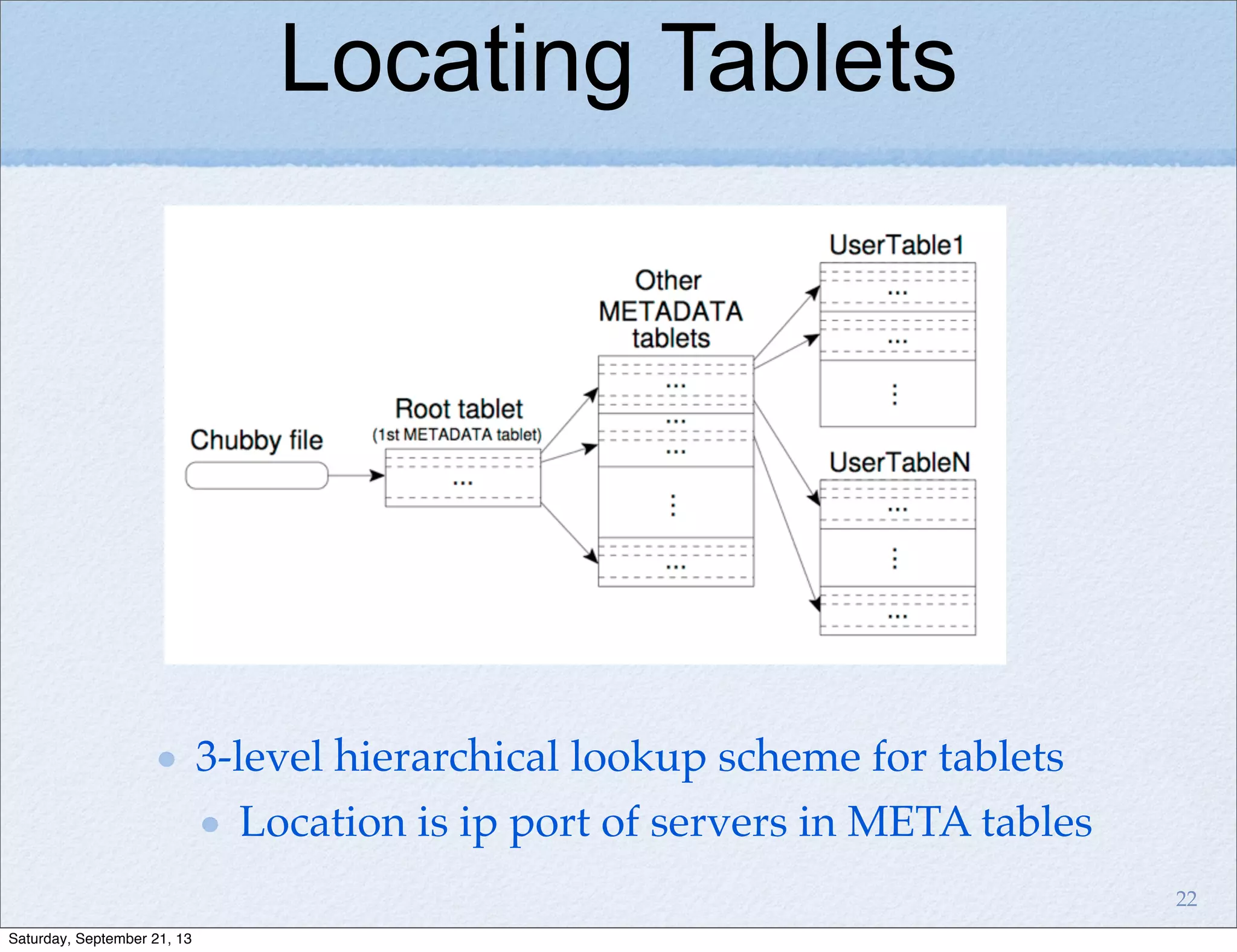

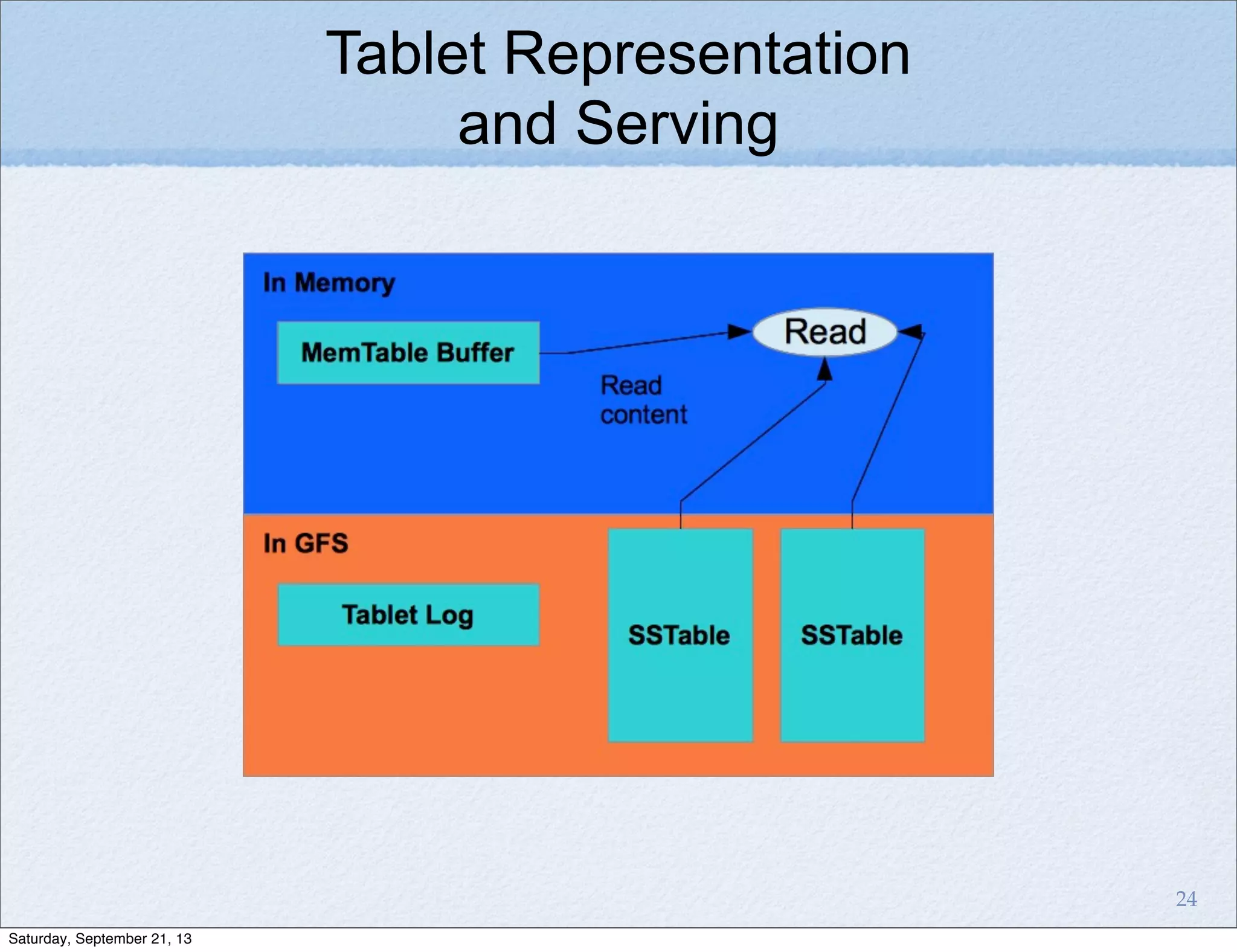
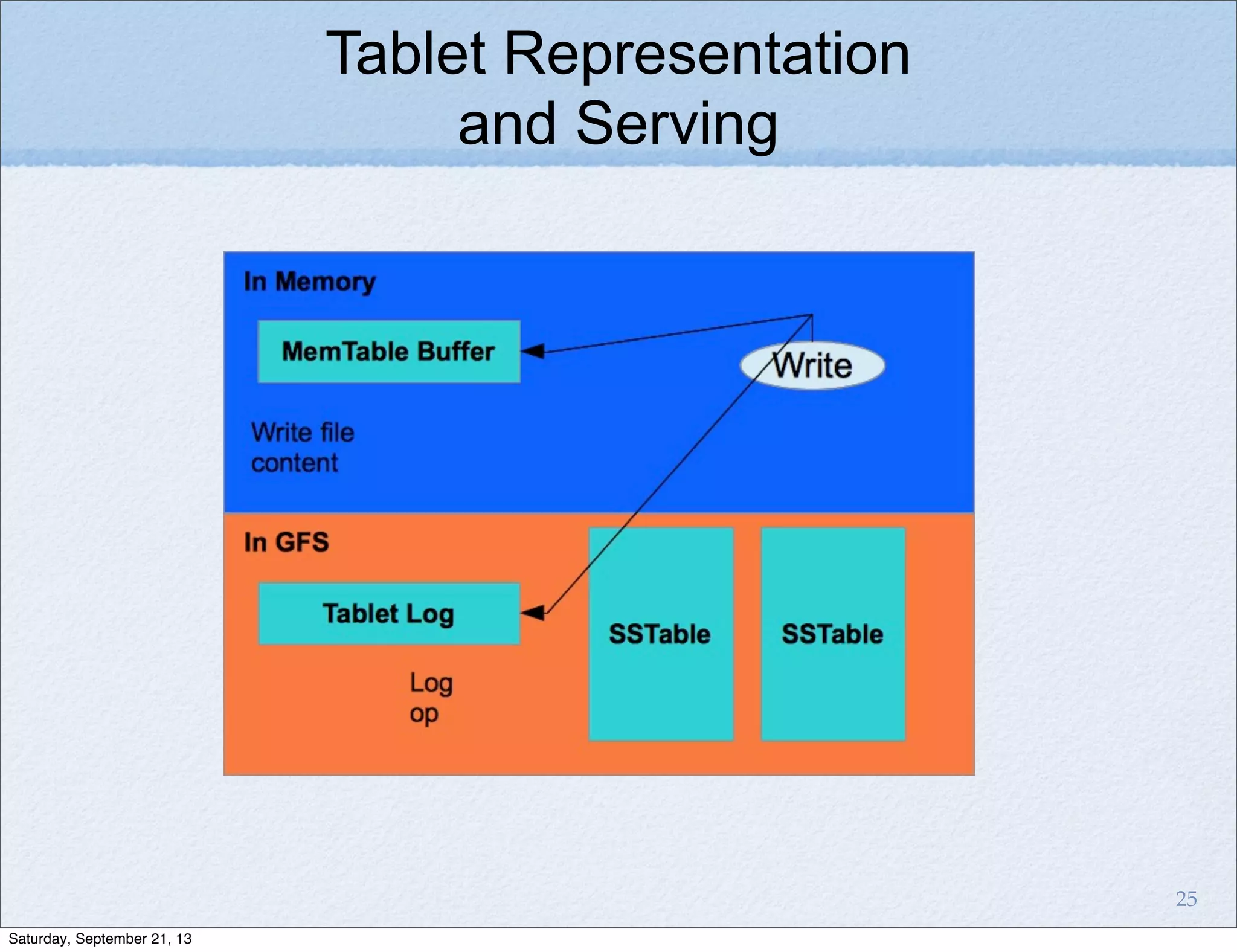









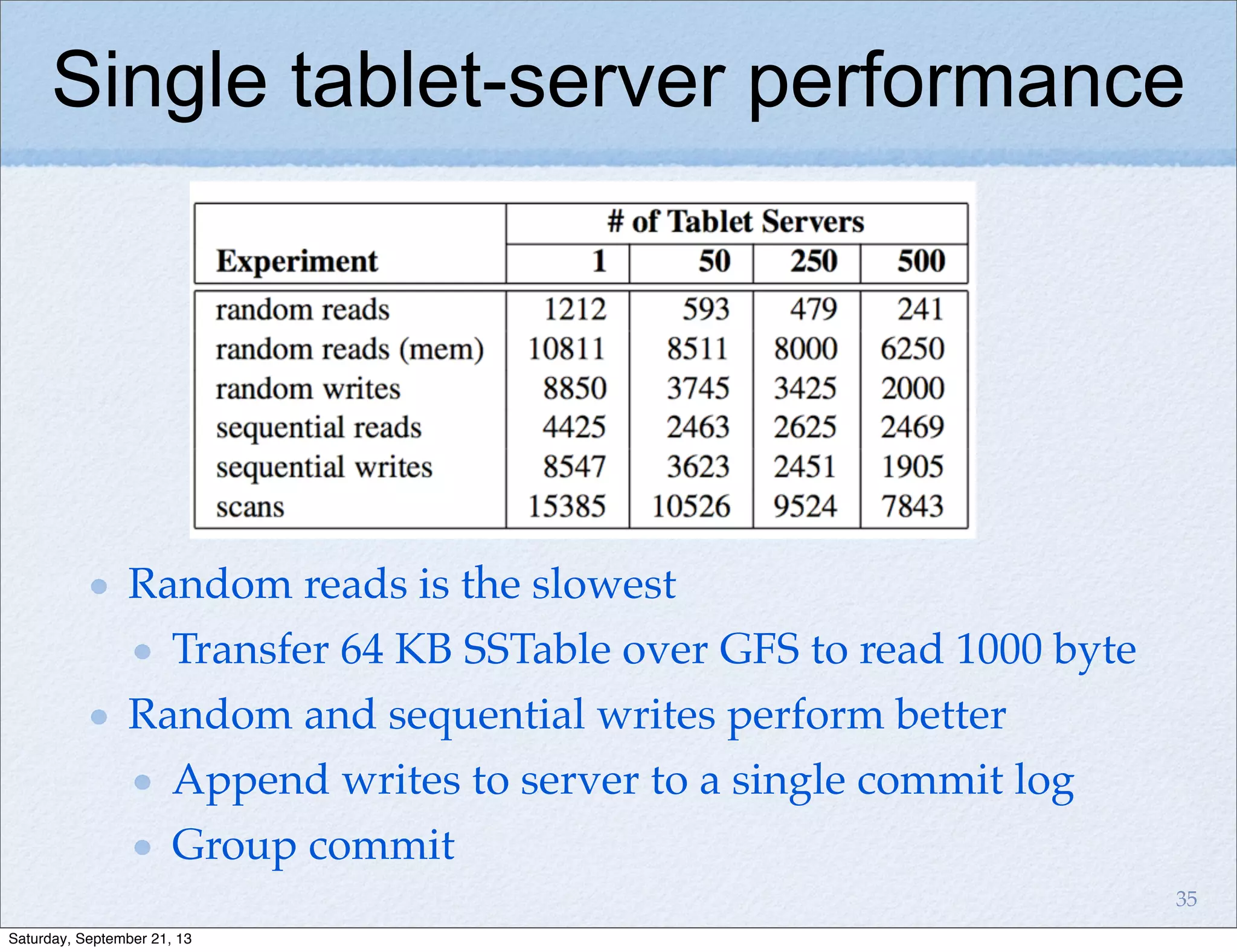
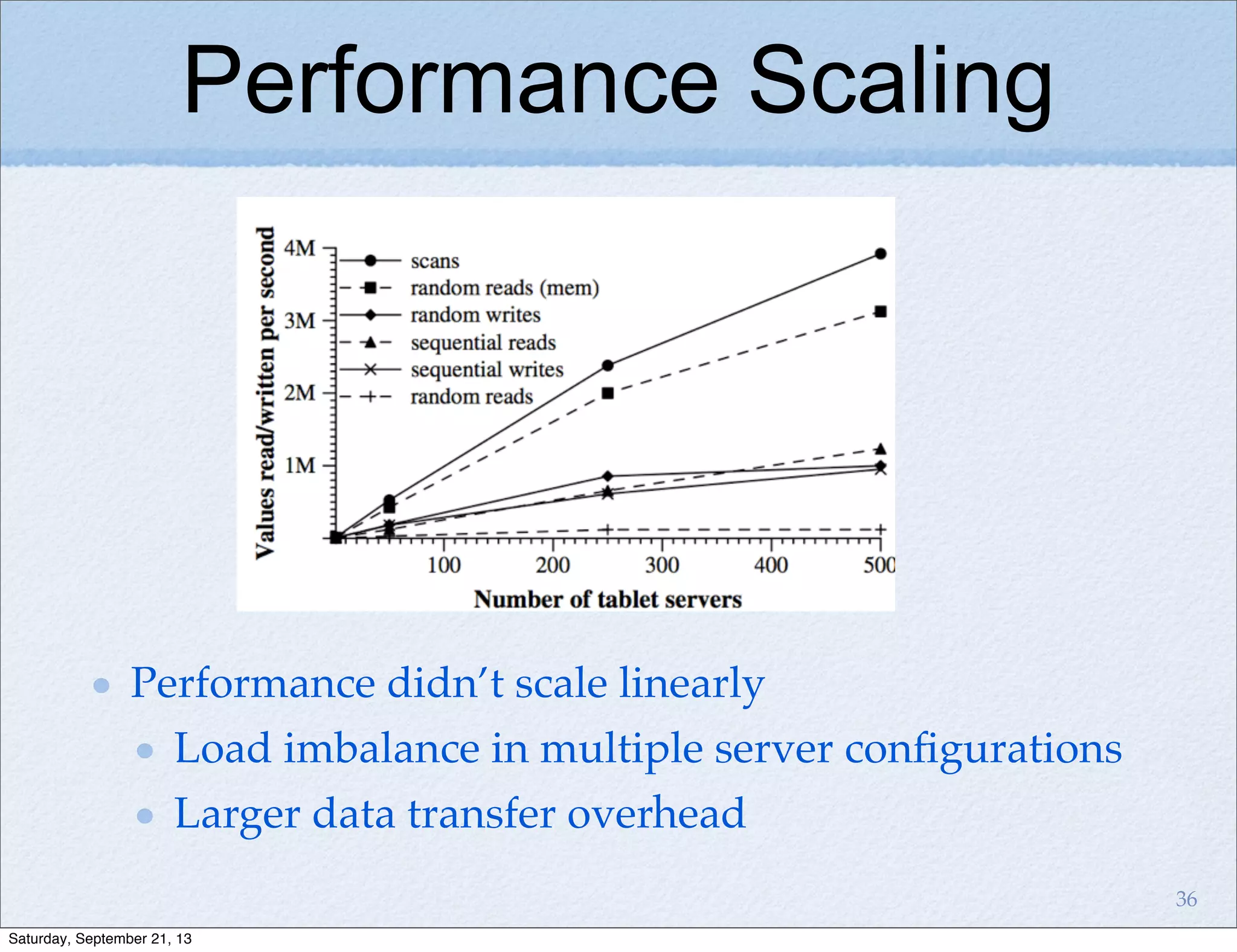






Bigtable is a distributed storage system for structured data designed to be scalable, high performance, and highly available. It uses a sparse, multidimensional sorted map to store data across many servers. Bigtable allows for asynchronous updates to different pieces of data at very high read and write rates and efficient scans across large datasets. It has been applied to applications like analytics, Earth imagery, and personalized search at Google.


























































![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)





![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)






