Downloaded 48 times




















BigTable is a distributed storage system developed by Google for managing structured data at a massive scale. It uses a sparse, distributed, and persistent multidimensional sorted map to store data across thousands of commodity servers. BigTable's data model organizes information into rows, column families, columns, and versions, providing flexibility and high performance for applications like web indexing and analytics.
Presented by Manuel Correa, the agenda includes discussing RDBMS issues, NoSQL, BigTable features, and applications.
RDBMS struggles with large datasets and lacks horizontal scaling. Intro to NoSQL databases as distributed storage alternatives.
BigTable is a distributed storage system designed by Google to manage structured data, scalable up to petabytes.
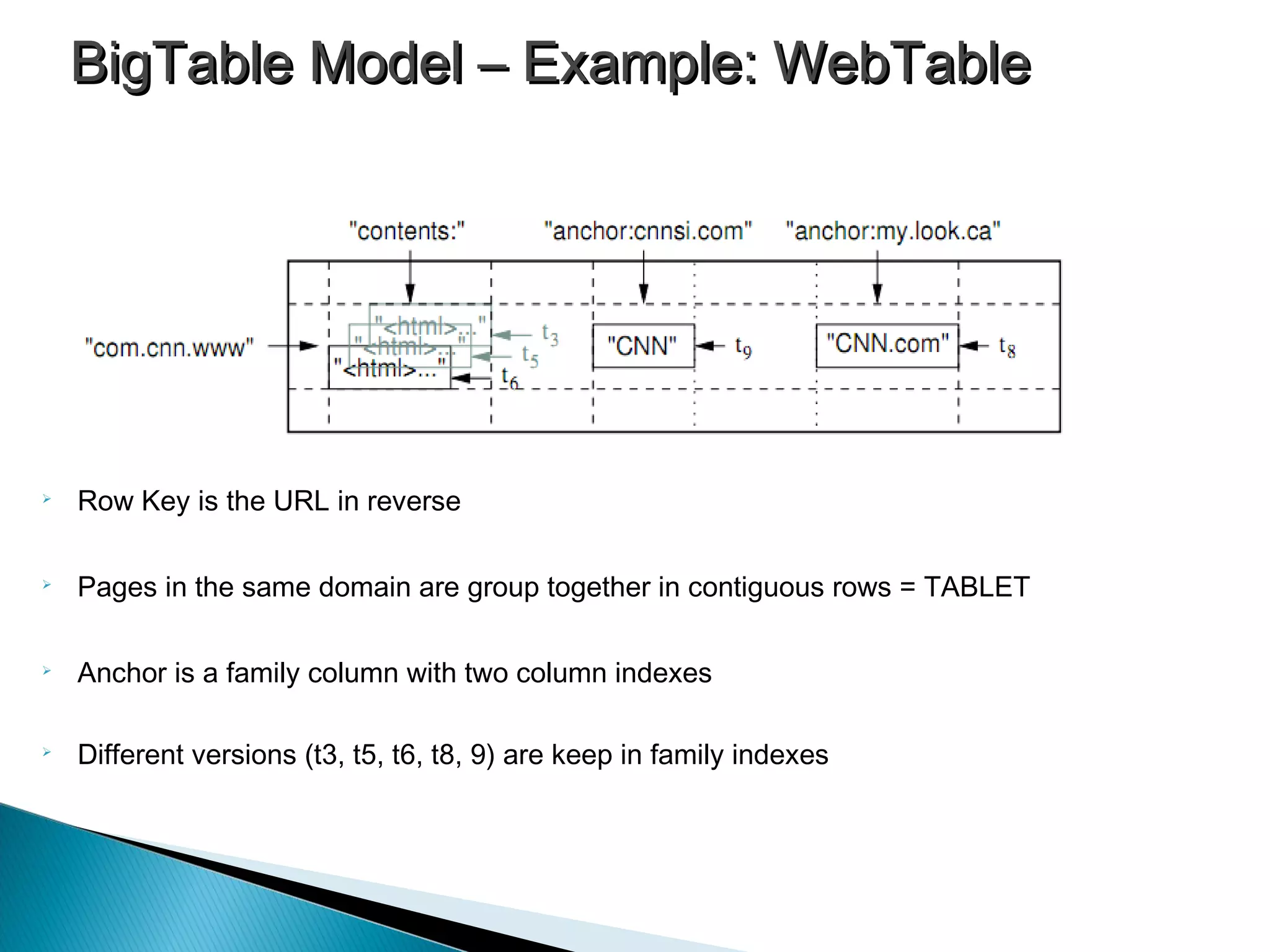
BigTable structure uses a multidimensional map indexed by keys, timestamps, with atomic operations and versioning.
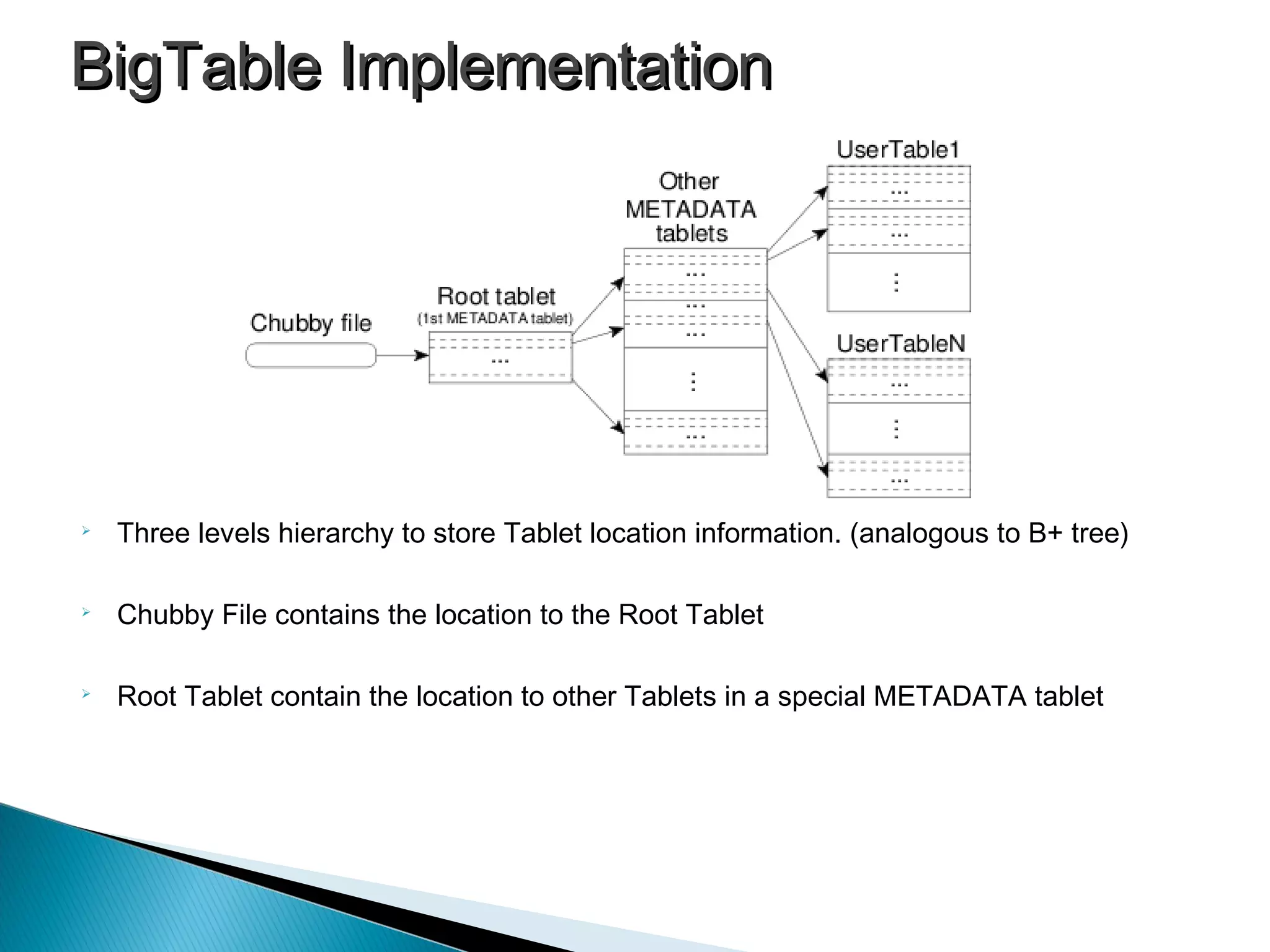
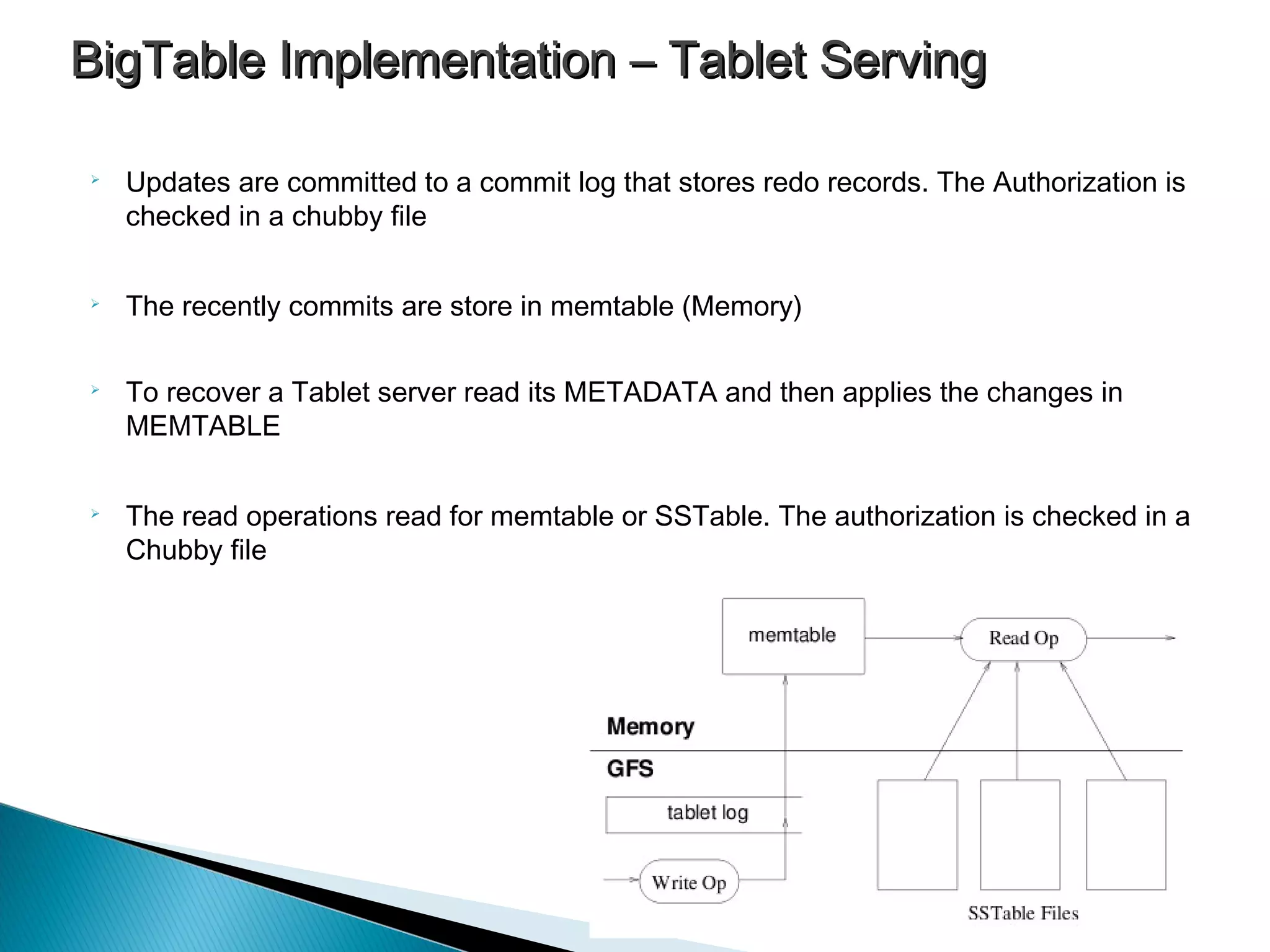
BigTable uses Google File System and SSTable for data storage, and implements a reliable locking service called Chubby.
HBase, an open-source model of BigTable, supports large datasets in Hadoop and presents optimizations for queries.
Evaluation of BigTable's performance and examples of real-world applications.
Open floor for questions about BigTable, its implementations, and functionalities.






























































