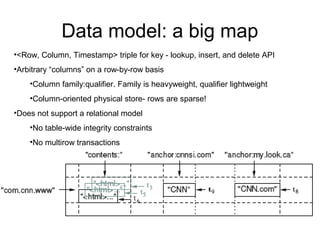
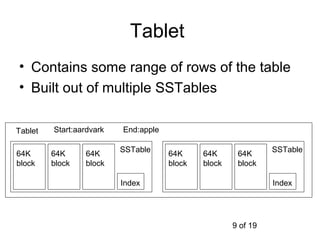
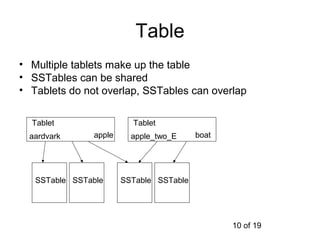
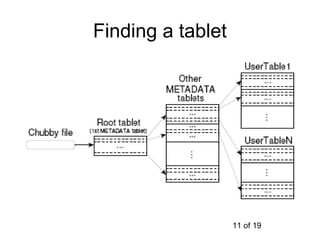
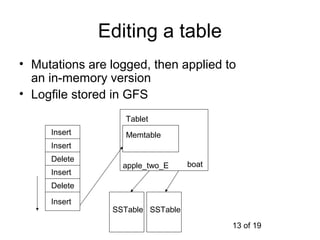
This document summarizes Google's Bigtable storage system. Bigtable stores data as a sparse, distributed, persistent multidimensional sorted map. It is built using the Google File System for storage, Chubby for locking, and a tablet structure with tablets split across multiple servers. Bigtable provides a simple data model and interfaces for clients to perform read and write operations on large datasets.















































![[Roblek] Distributed computing in practice](https://cdn.slidesharecdn.com/ss_thumbnails/e-pride-popravljen-roblek-distributed-computing-in-practice-1223970296700043-9-thumbnail.jpg?width=640&height=640&fit=bounds)










