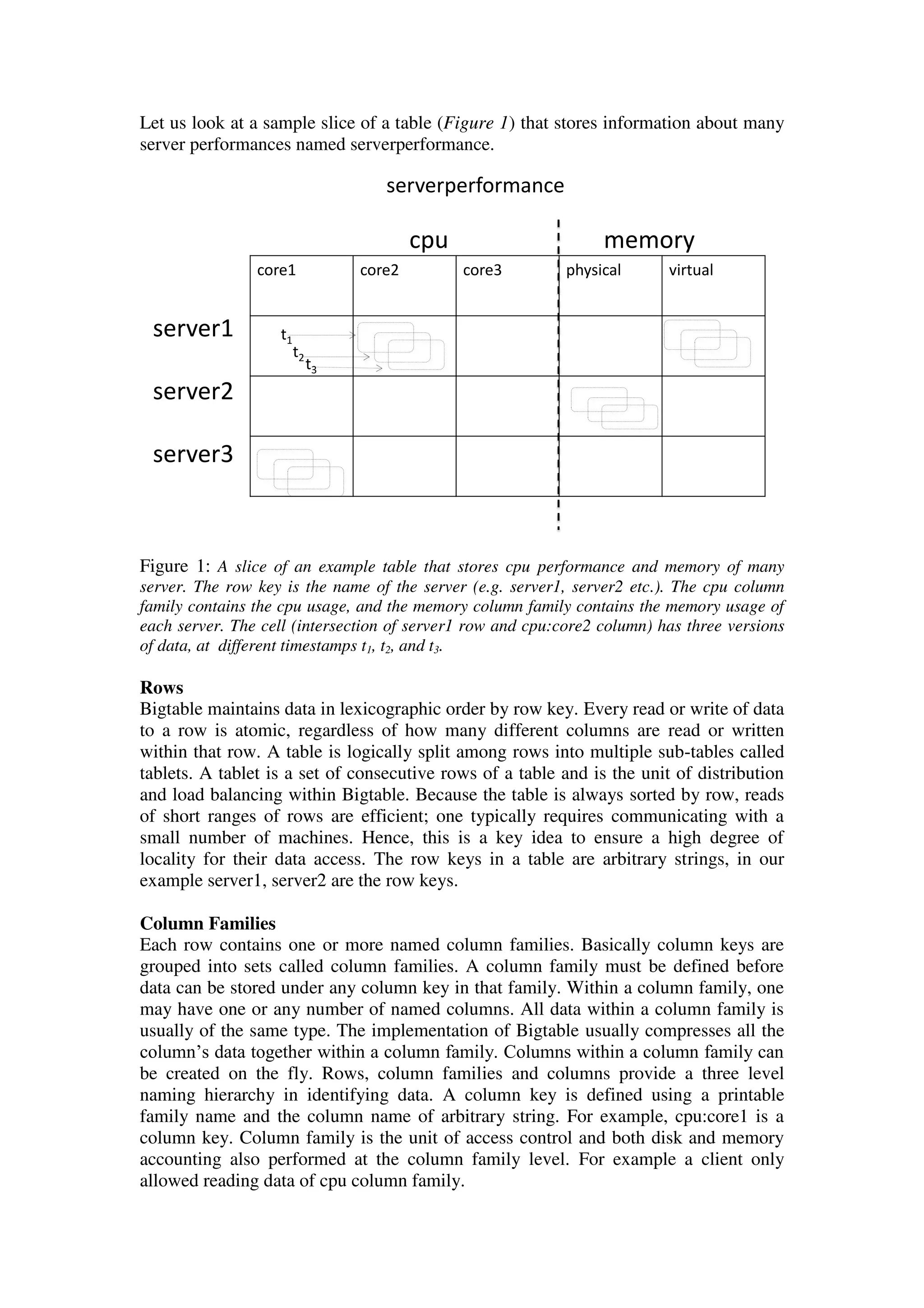
This document provides an overview of Bigtable, Google's distributed storage system. Bigtable is designed to manage large amounts of structured data across thousands of machines. It provides a simple data model with dynamic control over data layout and high scalability. Bigtable stores data as a sparse, multi-dimensional sorted map and uses row keys, column families and timestamps to index data. It was developed to meet the varied demands of Google's applications for data size, latency and flexibility in data management across a distributed environment.






![usage reports from energy meters and home appliances) and Time-series data (such as
CPU and memory usage over time for multiple servers).
Bigtable is not a relational database, it does not support SQL queries or joins, nor
does it support multi-row transactions. It is not a good solution for small amounts of
data.
What is Next?
Research is going on for supporting some additional Bigtable features, such as
support for secondary indices and infrastructure for building cross-data-center
replicated Bigtables with multiple master replicas.
3. Conclusions
I have described the characteristics of Bigtable, Data Model, the Architecture and its
implementation and who need it. It is important to realize that data comes in many
shapes and sizes. It also has many different uses; real-time fraud detection, web
display advertising and competitive analysis, social media and sentiment analysis,
intelligent traffic management and smart power grids, are few example. All of these
analytical solutions involve significant volumes of both semi-structured and
structured data. Many of these analytical solutions were not possible previously
because they were too costly to implement using standard relational database system.
Bigtable in combination with these new and evolving analytical processing
technologies can bring significant benefits to the business. Initially Google developed
this distributed system for storing structured data for its internal use. Bigtable clusters
have been in production use since April 2005. Currently Bigtable used in more than
hundreds of Goggle product and Google has many customers outside. Bigtable users
like the performance and high availability provided by the Bigtable implementation,
and that they can scale the capacity of their clusters by simply adding more machines
to the system as their resource demands change over time.
4. References
[1] Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A.
Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E. Gruber:
Bigtable: A Distributed Storage System for Structured Data. OSDI'06: Seventh
Symposium on Operating System Design and Implementation,
Seattle, WA, November 2006.
[2] https://cloud.google.com/bigtable/
[3] https://en.wikipedia.org/wiki/BigTable
[4] https://en.wikipedia.org/wiki/Big_data
[5] https://en.wikipedia.org/wiki/Relational_database_management_system](https://image.slidesharecdn.com/c986ba46-53b8-4a8d-8abf-ec49f98a9a2e-151029134805-lva1-app6892/75/Bigtable_Paper-8-2048.jpg)

























































