Download as PDF, PPTX





![© 2ndQuadrant 2016
Syntax
SELECT select_expression
FROM table_name
TABLESAMPLE sampling_method ( argument [, ...] )
[ REPEATABLE ( seed ) ]
...](https://image.slidesharecdn.com/pgday-asia-2016-big-data-and-postgresql-160326111616/85/Big-Data-and-PostgreSQL-6-320.jpg)


![© 2ndQuadrant 2016
REPEATABLE results
● (Reminder: [ REPEATABLE ( seed ) ])
● Optional argument
● Used if random, yet repeatable results are
required
● seed and argument need to be the same to
produce repeatable results
● Any changes made to the table will result in a
different data set](https://image.slidesharecdn.com/pgday-asia-2016-big-data-and-postgresql-160326111616/85/Big-Data-and-PostgreSQL-10-320.jpg)





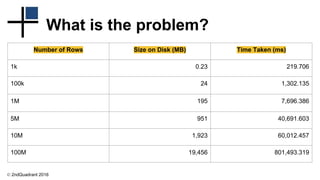
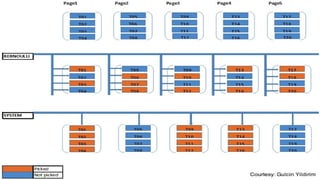
The document discusses the challenges of analyzing large datasets in PostgreSQL, highlighting the significance of efficient data sampling. It introduces the 'tablesample' feature, which allows for quick sampling of data using various methods to reduce query times significantly. Additionally, it mentions related projects and features that enhance PostgreSQL's capabilities for big data applications.








![[EPPG] Oracle to PostgreSQL, Challenges to Opportunity](https://cdn.slidesharecdn.com/ss_thumbnails/eppg-oracletopostgresqlchallengestoopportunity-190409033058-thumbnail.jpg?width=640&height=640&fit=bounds)





























































































