Download as PDF, PPTX







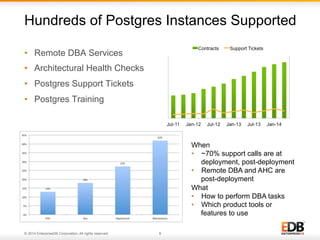
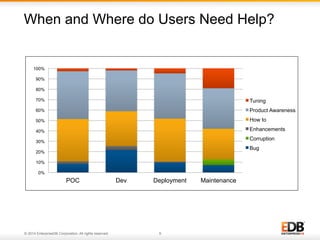
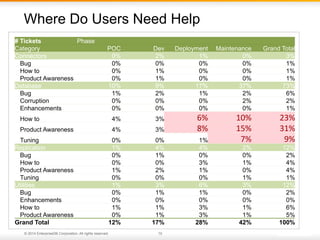

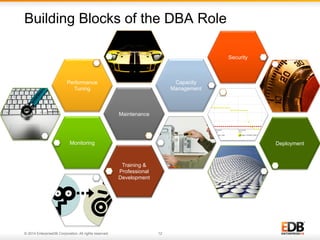



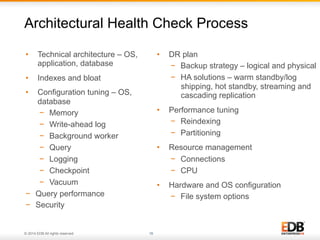

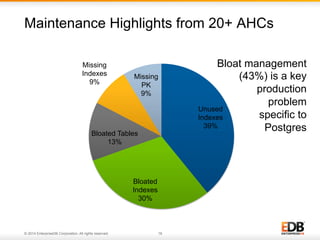
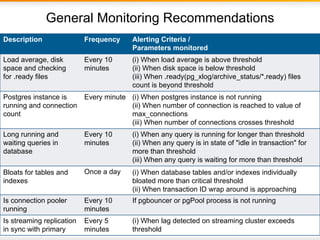

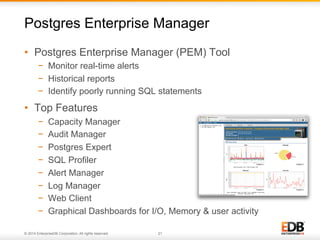



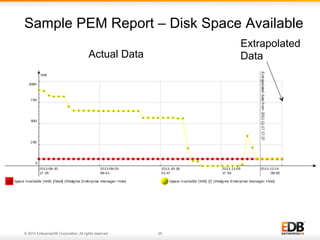







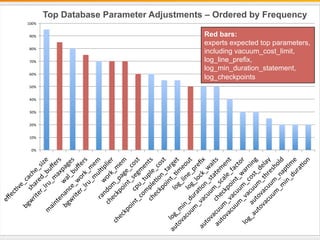
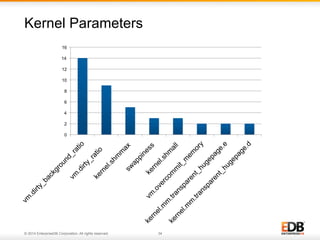
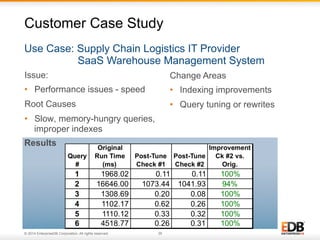
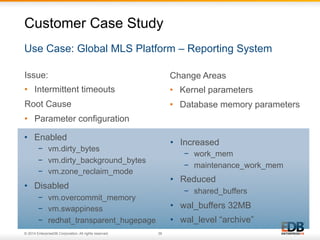


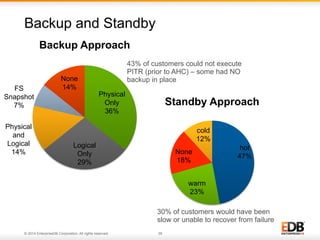







The document outlines best practices for PostgreSQL Database Administrators (DBAs), focusing on monitoring, maintenance, capacity planning, and configuration tuning. It emphasizes the importance of architectural health checks, performance tuning, and effective backup strategies to ensure database reliability and efficiency. Additionally, it shares insights from customer case studies and offers recommendations for addressing common issues such as performance problems and replication failures.





























































































