Download to read offline











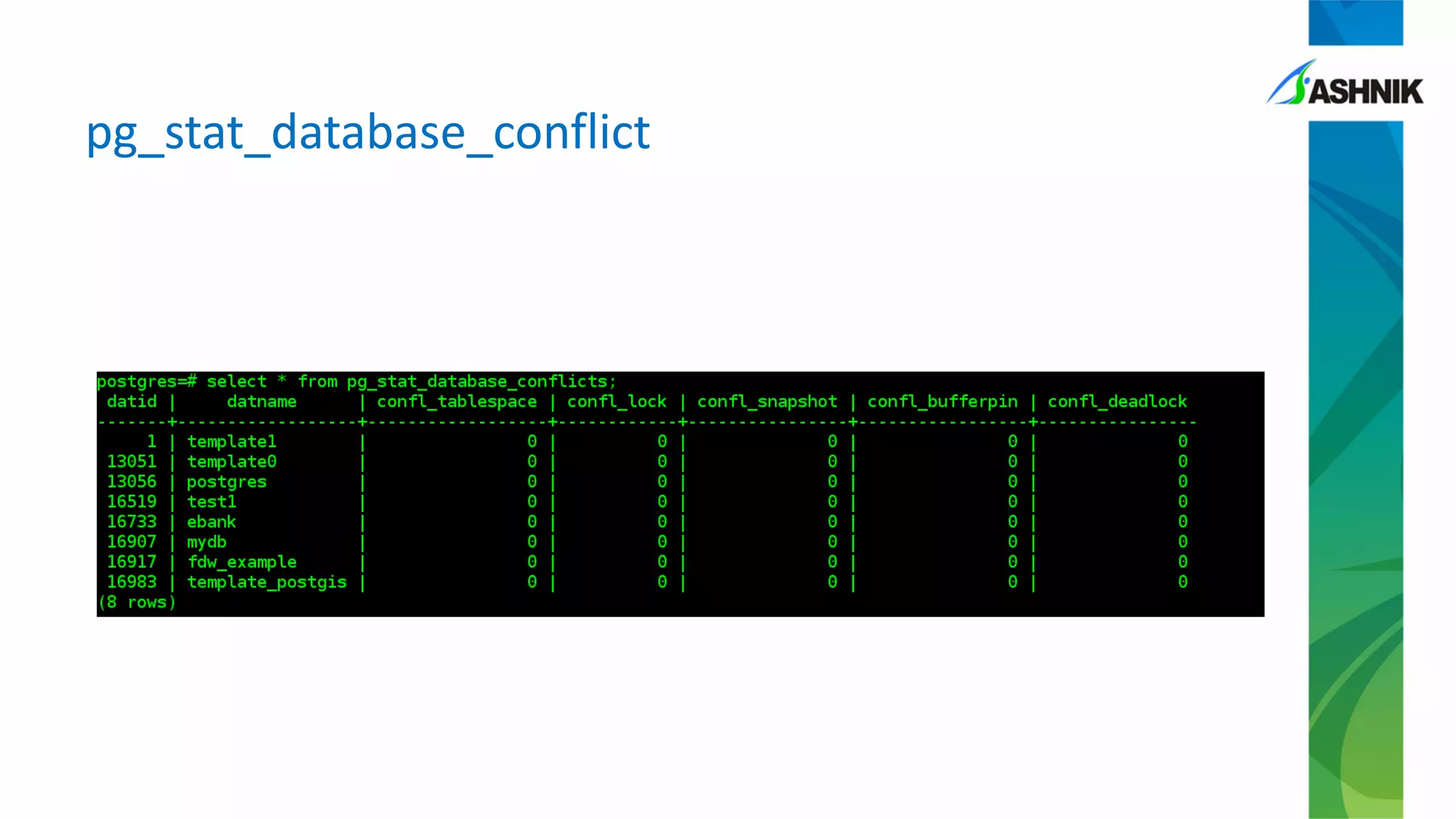







![Issue re-creation – no conflicts
postgres=# select * from
pg_stat_database_conflicts
where datname='training_db';
-[ RECORD 1 ]-----+------------
datid | 16400
datname | training_db
confl_tablespace | 0
confl_lock | 0
confl_snapshot | 0
confl_bufferpin | 0
confl_deadlock | 0](https://image.slidesharecdn.com/sameerkumar-talefromtrenches-180324170509/75/PGConf-APAC-2018-Tale-from-Trenches-22-2048.jpg)

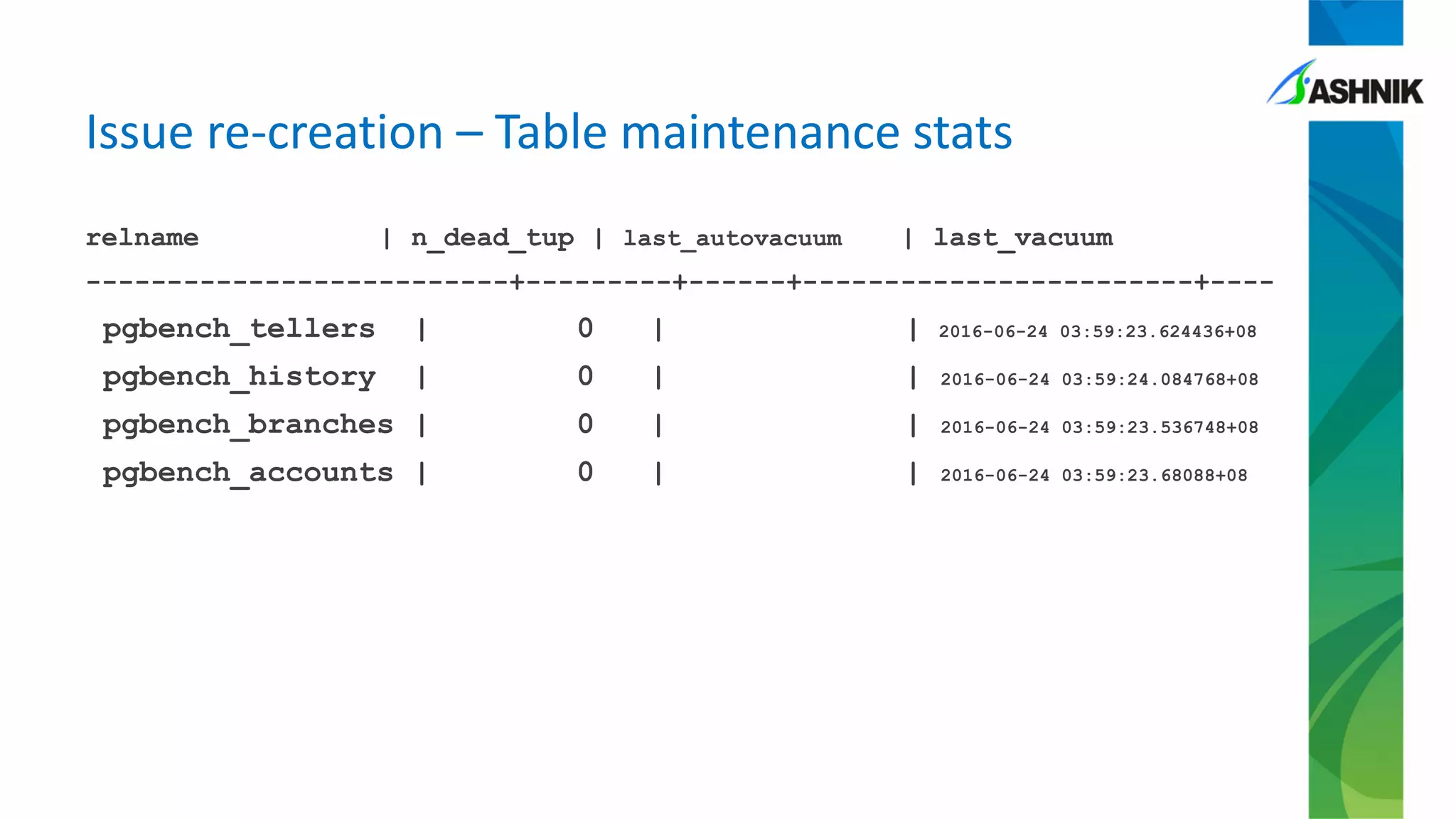















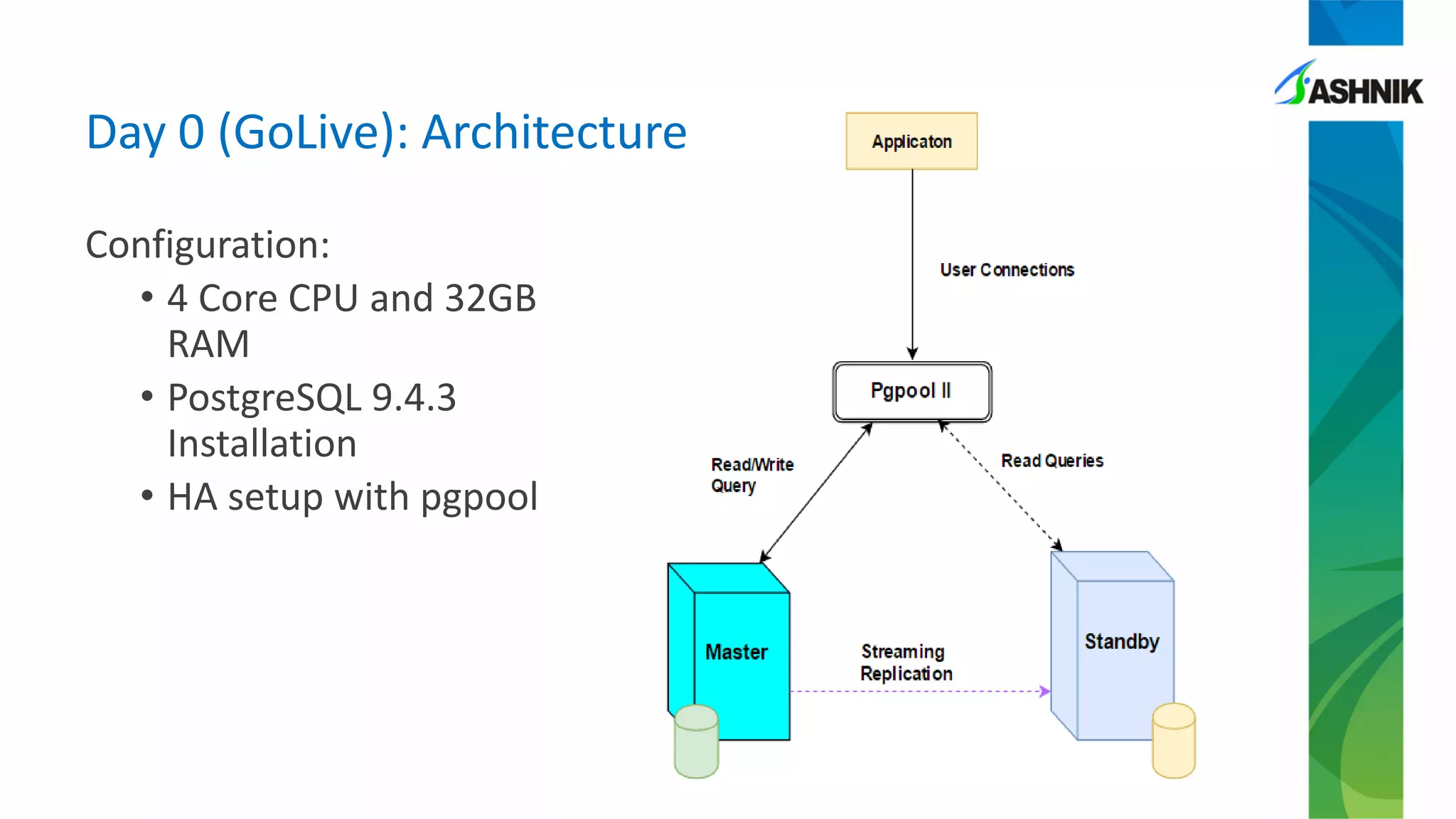
The document details a case study of a large BFSI company encountering performance issues after migrating to PostgreSQL, such as high CPU usage and slow response times. Key problems included conflicts due to long-held locks during batch processes, necessitating interventions like query tuning and adjustments to autovacuum settings. The resolution involved a combination of temporary measures, such as turning off autovacuum on specific tables, and long-term fixes focusing on batch process logic and proper configuration settings.








































![Slow things down to make them go faster [FOSDEM 2022]](https://cdn.slidesharecdn.com/ss_thumbnails/slowthingsdownfosdem-220206162647-thumbnail.jpg?width=640&height=640&fit=bounds)













































