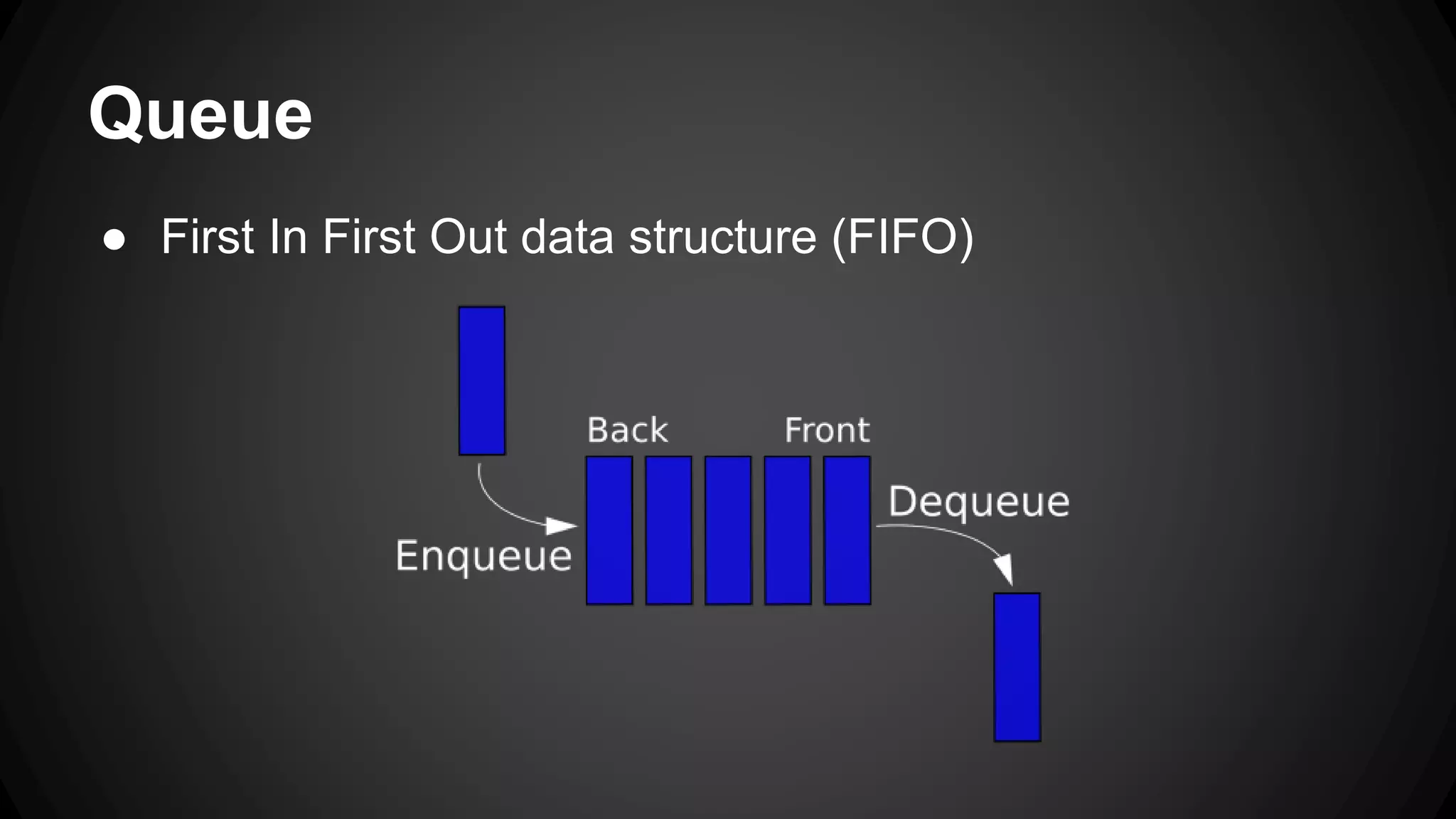
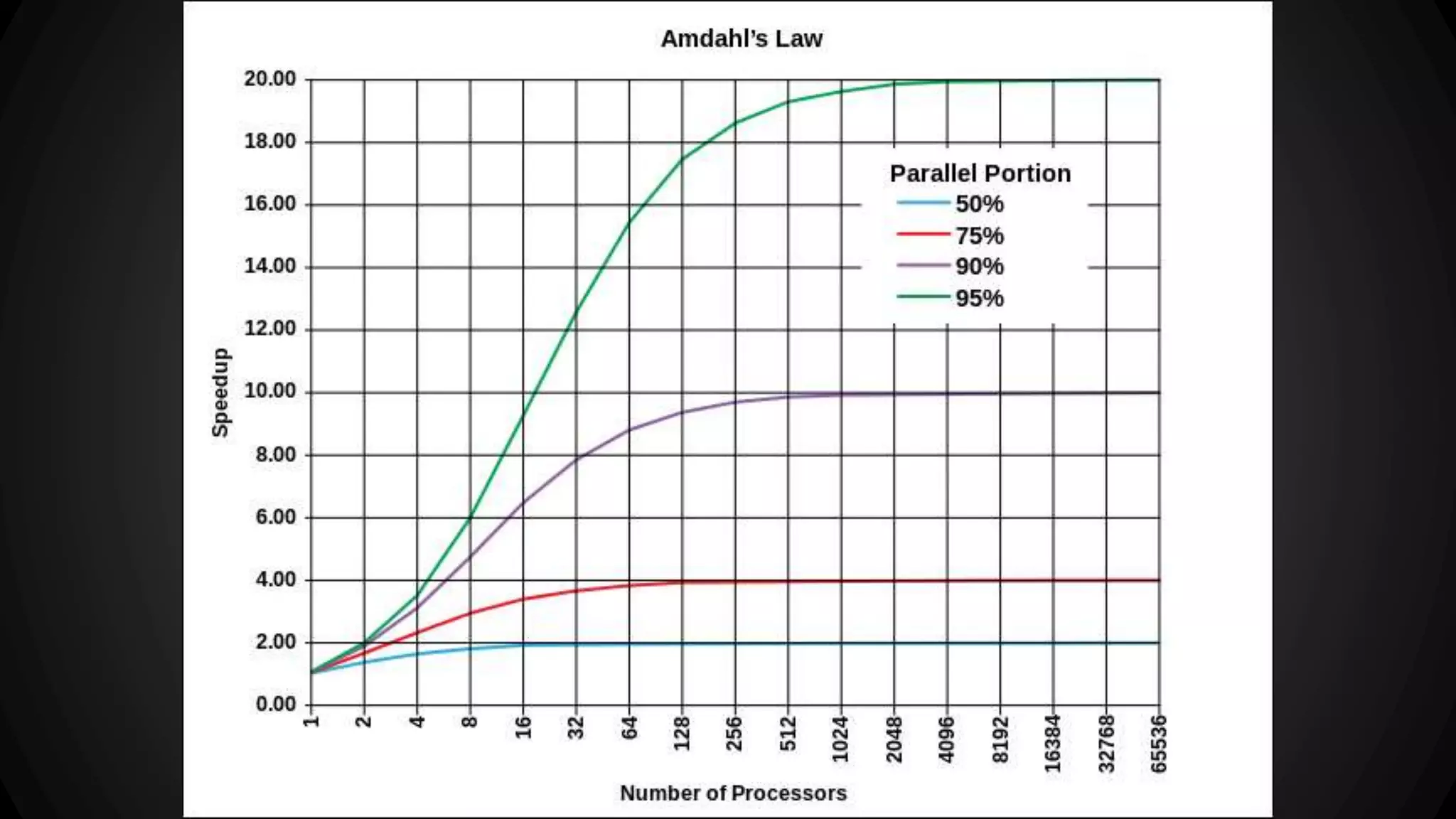
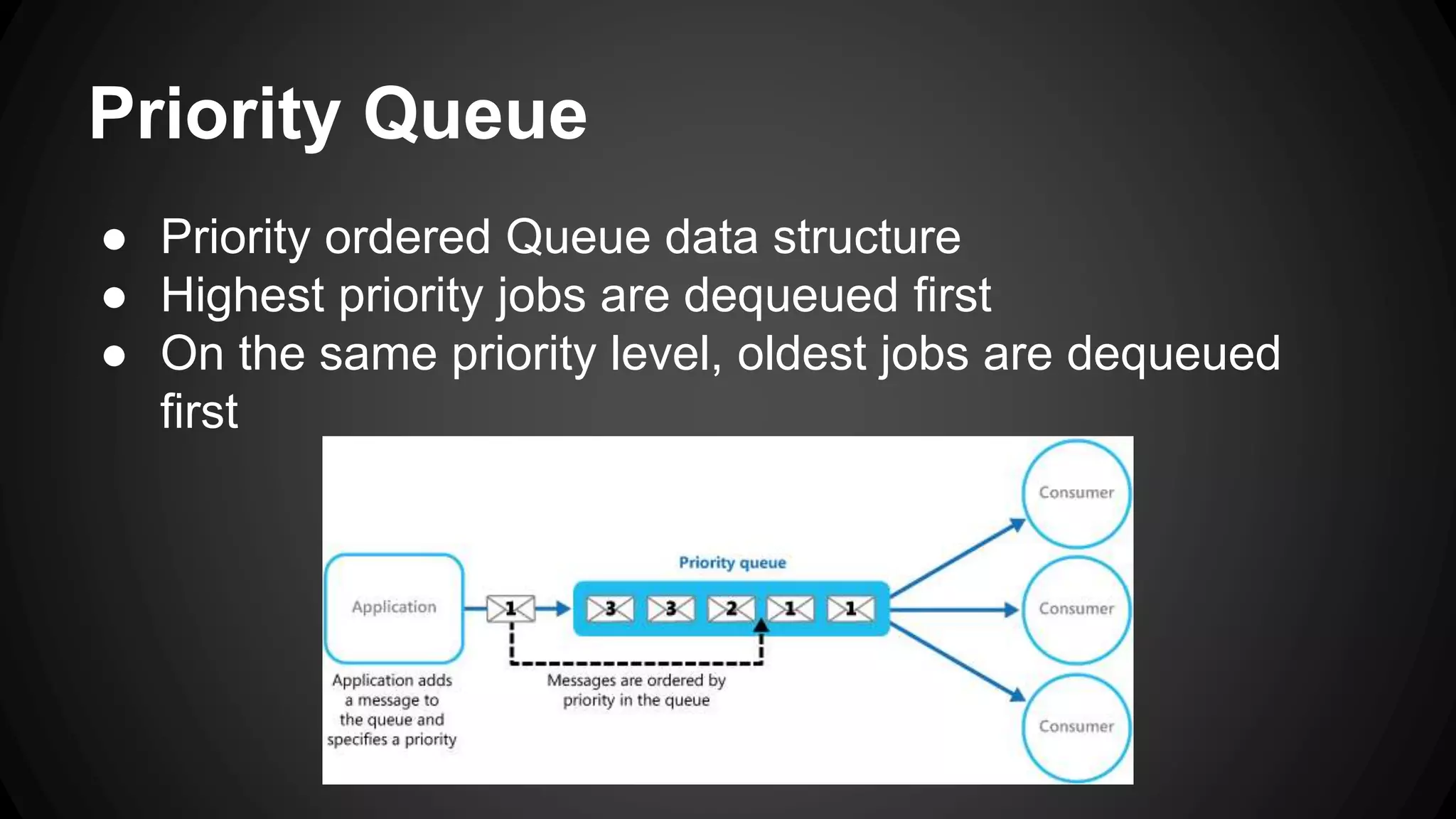
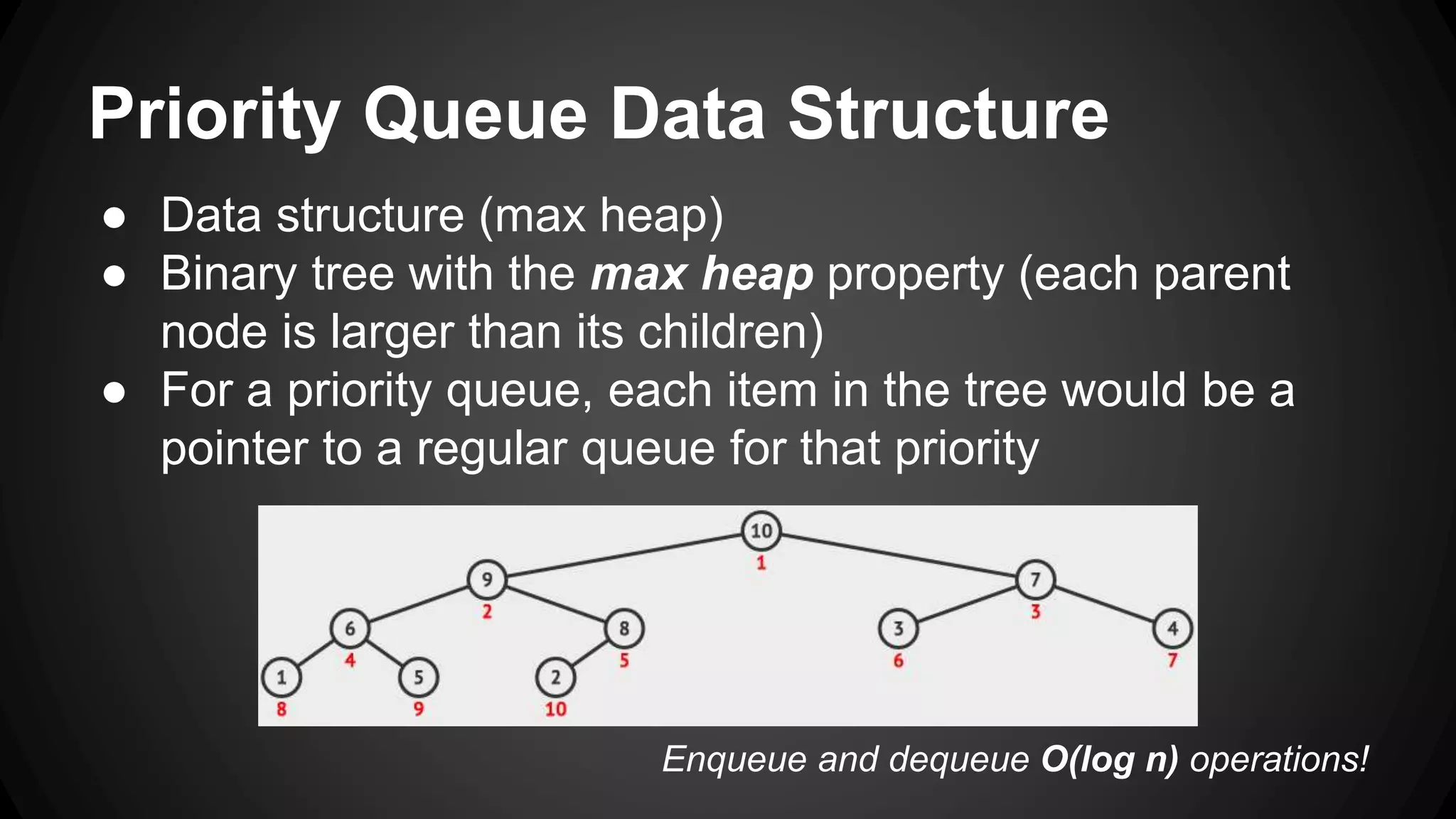
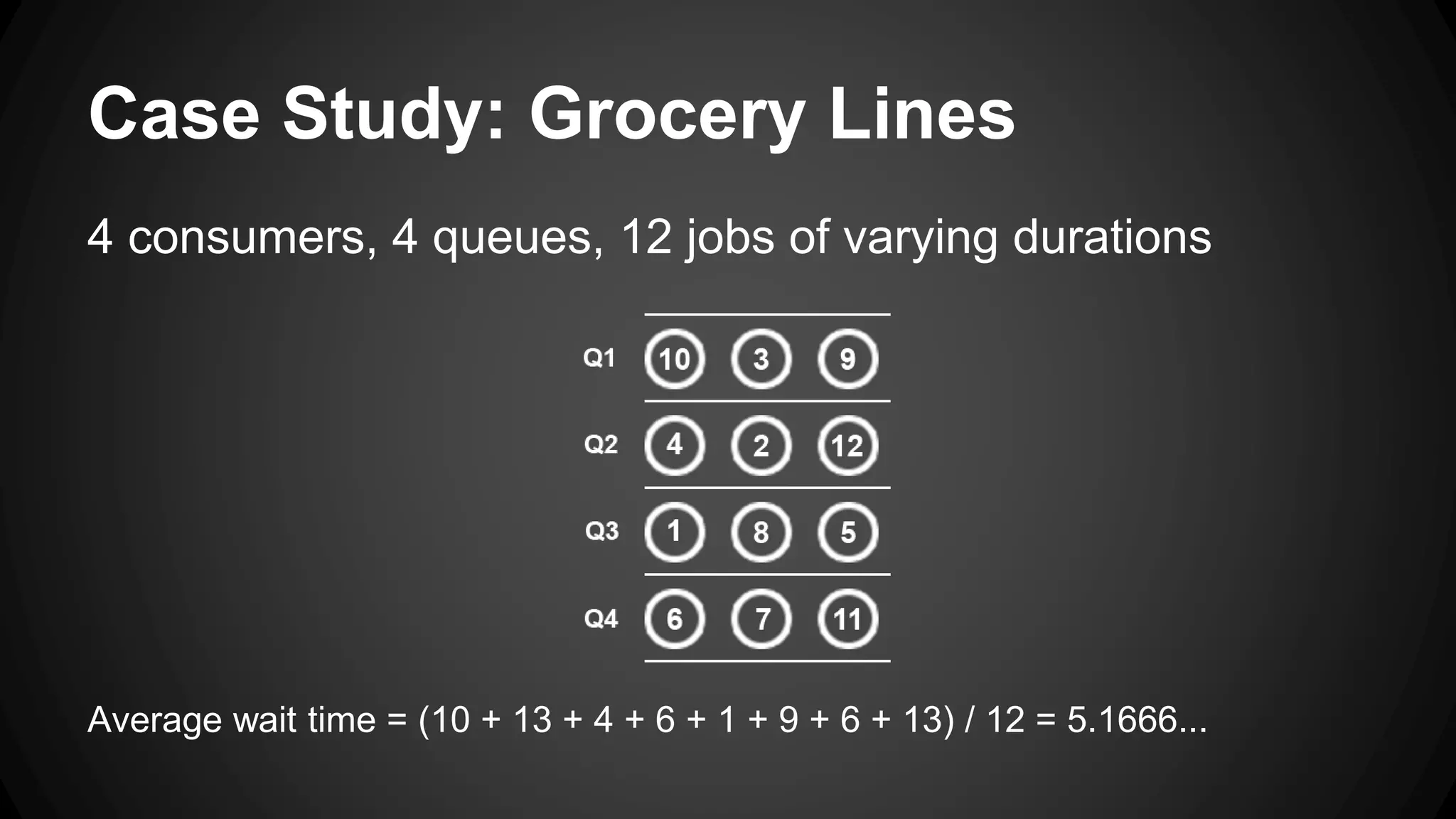
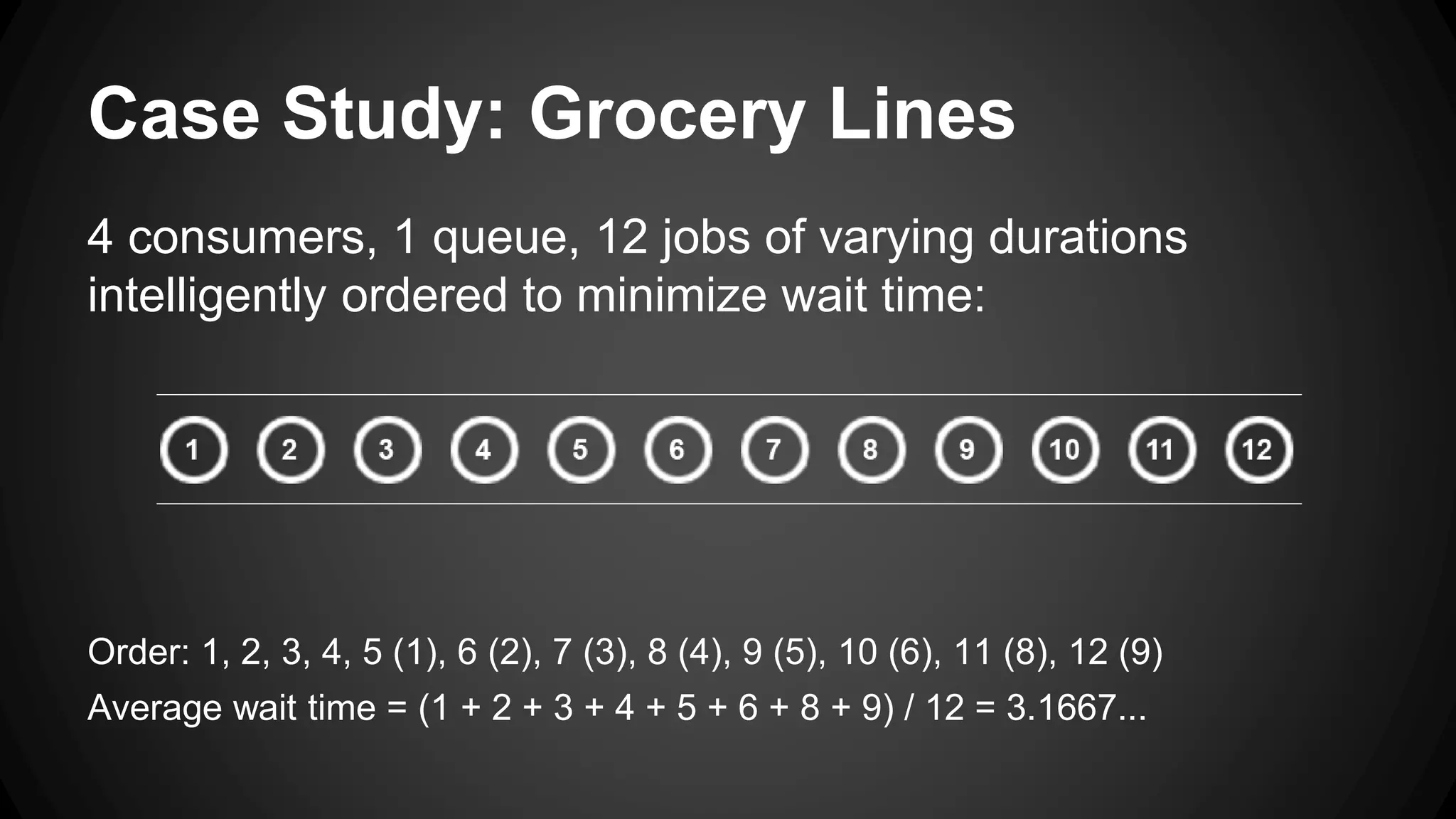
Job queues allow asynchronous processing of jobs by consumers. Producers add jobs to the queue and consumers process the jobs in the background. Common queue operations include enqueue, dequeue, and checking if the queue is empty. Queues can be implemented as linked lists for efficient insertion and removal. Priority queues add the ability to prioritize jobs so the highest priority jobs are processed first. Popular job queue software includes Beanstalkd, Celery, Resque, and Amazon SQS.