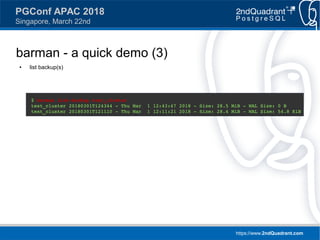
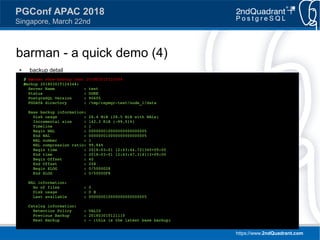
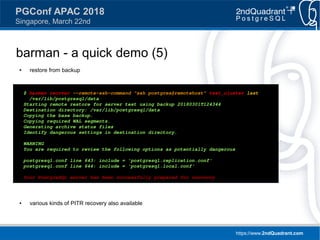
Downloaded 52 times














![https://www.2ndQuadrant.com
PGConf APAC 2018
Singapore, March 22nd
barman - a quick demo (1)
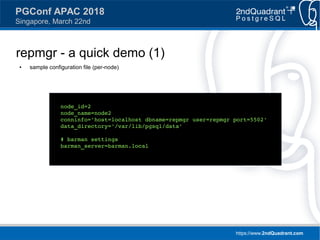
● sample configuration file (Barman server only)
[barman]
barman_home = /home/barman
barman_user = barman
log_file = /var/log/barman/barman.log
compression = gzip
reuse_backup = link
minimum_redundancy = 2
retention_policy = RECOVERY WINDOW OF 4 WEEKS
streaming_archiver = on
[test_cluster]
description = "Repmgr Test Cluster"
ssh_command = ssh -q localhost
conninfo = host=127.0.0.1 user=postgres port=5501](https://image.slidesharecdn.com/ianbarwick-managingreplicationclustersrepmgrbarmanpgbouncer-180324171404/85/PGConf-APAC-2018-Managing-replication-clusters-with-repmgr-Barman-and-PgBouncer-16-320.jpg)
![https://www.2ndQuadrant.com
PGConf APAC 2018
Singapore, March 22nd
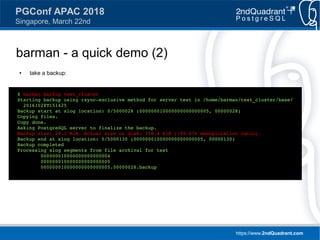
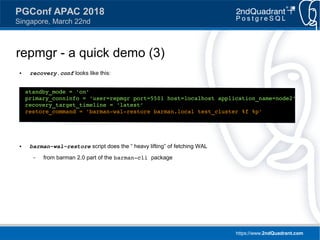
repmgr - a quick demo (2)
● clone a standby... from the Barman backup!
● recovery.conf looks like this:
$ repmgr -D /tmp/repmgr-test/node_2/data
-f /tmp/repmgr-test/node_2/repmgr.conf
-h localhost -p 5501 -d repmgr -U repmgr --verbose -LINFO
standby clone
[2016-11-01 12:12:25] [NOTICE] using configuration file "/tmp/repmgr-test/node_2/repmgr.conf"
[2016-11-01 12:12:25] [NOTICE] destination directory '/tmp/repmgr-test/node_2/data' provided
[2016-11-01 12:12:25] [INFO] Connecting to Barman server to verify backup for test_cluster
Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
[2016-11-01 12:12:25] [INFO] creating directory "/tmp/repmgr-test/node_2/data/repmgr"...
[2016-11-01 12:12:25] [INFO] Connecting to Barman server to fetch server parameters
Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
[2016-11-01 12:12:26] [INFO] connecting to upstream node
[2016-11-01 12:12:26] [INFO] connected to upstream node, checking its state
[2016-11-01 12:12:26] [INFO] Successfully connected to upstream node. Current installation size is 28 MB
[2016-11-01 12:12:26] [NOTICE] getting backup from Barman...
Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
[2016-11-01 12:12:28] [NOTICE] standby clone (from Barman) complete
[2016-11-01 12:12:28] [NOTICE] you can now start your PostgreSQL server
[2016-11-01 12:12:28] [HINT] for example : pg_ctl -D /tmp/repmgr-test/node_2/data start
[2016-11-01 12:12:28] [HINT] After starting the server, you need to register this standby with
"repmgr standby register"](https://image.slidesharecdn.com/ianbarwick-managingreplicationclustersrepmgrbarmanpgbouncer-180324171404/85/PGConf-APAC-2018-Managing-replication-clusters-with-repmgr-Barman-and-PgBouncer-22-320.jpg)

![https://www.2ndQuadrant.com
PGConf APAC 2018
Singapore, March 22nd
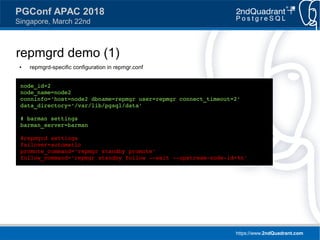
repmgrd demo (2)
● Time to say goodbye to the primary...
● Standby promotes itself
pg_ctl -D /var/lib/pgsql/data/ -m immediate stop
[2018-03-20 13:54:02] [INFO] node "node2" (node ID: 2) monitoring upstream node "node1" (node ID: 1) in normal
state
[2018-03-20 13:54:14] [WARNING] unable to connect to upstream node "node1" (node ID: 1)
[2018-03-20 13:54:14] [INFO] checking state of node 1, 1 of 5 attempts
[2018-03-20 13:54:14] [INFO] sleeping 1 seconds until next reconnection attempt
[2018-03-20 13:54:15] [INFO] checking state of node 1, 2 of 5 attempts
[2018-03-20 13:54:15] [INFO] sleeping 1 seconds until next reconnection attempt
[2018-03-20 13:54:16] [INFO] checking state of node 1, 3 of 5 attempts
[2018-03-20 13:54:16] [INFO] sleeping 1 seconds until next reconnection attempt
[2018-03-20 13:54:17] [INFO] checking state of node 1, 4 of 5 attempts
[2018-03-20 13:54:17] [INFO] sleeping 1 seconds until next reconnection attempt
[2018-03-20 13:54:18] [INFO] checking state of node 1, 5 of 5 attempts
[2018-03-20 13:54:18] [WARNING] unable to reconnect to node 1 after 5 attempts
[2018-03-20 13:54:18] [NOTICE] this node is the only available candidate and will now promote itself
NOTICE: promoting standby to primary
DETAIL: promoting server "node2" (ID: 2) using "/home/ibarwick/devel/builds/94/bin/pg_ctl -l
/tmp/postgres.5502.log -m fast -w -D '/space/sda1/ibarwick/repmgr-test/node_2/data' promote"
NOTICE: STANDBY PROMOTE successful
DETAIL: server "node2" (ID: 2) was successfully promoted to primary
[2018-03-20 13:54:19] [NOTICE] 0 followers to notify
[2018-03-20 13:54:19] [INFO] switching to primary monitoring mode](https://image.slidesharecdn.com/ianbarwick-managingreplicationclustersrepmgrbarmanpgbouncer-180324171404/85/PGConf-APAC-2018-Managing-replication-clusters-with-repmgr-Barman-and-PgBouncer-26-320.jpg)



![https://www.2ndQuadrant.com
PGConf APAC 2018
Singapore, March 22nd
PgBouncer - configuration
● simple example
[pgbouncer]
listen_addr = *
listen_port = 6432
[databases]
appdb-rw= host=node1 dbname=repmgr
appdb-ro= host=node2 dbname=repmgr](https://image.slidesharecdn.com/ianbarwick-managingreplicationclustersrepmgrbarmanpgbouncer-180324171404/85/PGConf-APAC-2018-Managing-replication-clusters-with-repmgr-Barman-and-PgBouncer-31-320.jpg)
![https://www.2ndQuadrant.com
PGConf APAC 2018
Singapore, March 22nd
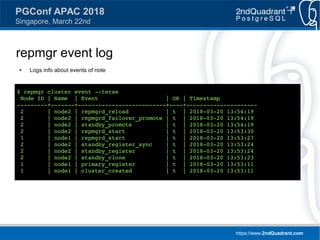
pgbouncer console
$ psql 'host=localhost user=postgres port=6501 dbname=pgbouncer'
psql (9.6.0, server 1.7.2/bouncer)
Type "help" for help.
pgbouncer=# show help;
NOTICE: Console usage
DETAIL:
SHOW HELP|CONFIG|DATABASES|POOLS|CLIENTS|SERVERS|VERSION
SHOW STATS|FDS|SOCKETS|ACTIVE_SOCKETS|LISTS|MEM
SHOW DNS_HOSTS|DNS_ZONES
SET key = arg
RELOAD
PAUSE [<db>]
RESUME [<db>]
DISABLE <db>
ENABLE <db>
KILL <db>
SUSPEND
SHUTDOWN
SHOW
Time: 0.140 ms](https://image.slidesharecdn.com/ianbarwick-managingreplicationclustersrepmgrbarmanpgbouncer-180324171404/85/PGConf-APAC-2018-Managing-replication-clusters-with-repmgr-Barman-and-PgBouncer-32-320.jpg)

![https://www.2ndQuadrant.com
PGConf APAC 2018
Singapore, March 22nd
PgBouncer – use include file
● [database] section as include file:
Note: %include directive available from PgBouncer 1.6
[pgbouncer]
listen_addr = *
listen_port = 6432
%include /etc/pgbouncer.database.ini](https://image.slidesharecdn.com/ianbarwick-managingreplicationclustersrepmgrbarmanpgbouncer-180324171404/85/PGConf-APAC-2018-Managing-replication-clusters-with-repmgr-Barman-and-PgBouncer-35-320.jpg)
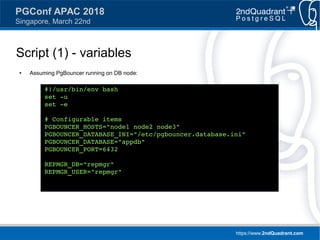

![https://www.2ndQuadrant.com
PGConf APAC 2018
Singapore, March 22nd
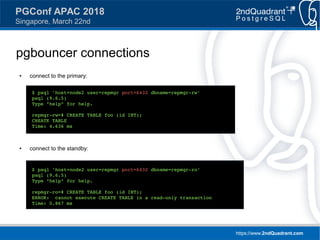
Script (3) – reconfigure
● Rewrite [databases] section
# 3. Reconfigure pgbouncer instances
PGBOUNCER_DATABASE_INI_NEW="/tmp/pgbouncer.database.ini"
for HOST in $PGBOUNCER_HOSTS
do
# Recreate the pgbouncer config file
echo -e "[databases]n" > $PGBOUNCER_DATABASE_INI_NEW
psql -d $REPMGR_DB -U $REPMGR_USER -t -A
-c "SELECT '${PGBOUNCER_DATABASE}-rw= ' || conninfo || '
application_name=pgbouncer_${HOST}'
FROM repmgr.nodes
WHERE active = TRUE AND type='primary'"
>> $PGBOUNCER_DATABASE_INI_NEW
psql -d $REPMGR_DB -U $REPMGR_USER -t -A
-c "SELECT '${PGBOUNCER_DATABASE}-ro= ' || conninfo ||
' application_name=pgbouncer_${HOST}'
FROM repmgr.nodes
WHERE node_name='${HOST}'"
>> $PGBOUNCER_DATABASE_INI_NEW
rsync $PGBOUNCER_DATABASE_INI_NEW $HOST:$PGBOUNCER_DATABASE_INI](https://image.slidesharecdn.com/ianbarwick-managingreplicationclustersrepmgrbarmanpgbouncer-180324171404/85/PGConf-APAC-2018-Managing-replication-clusters-with-repmgr-Barman-and-PgBouncer-38-320.jpg)





The document discusses managing PostgreSQL replication and high availability using tools like repmgr, Barman, and PgBouncer during the PgConf APAC 2018. Key concepts include the importance of high availability planning, various types of replication, and the roles played by each tool, such as automatic failover with repmgr and backup handling with Barman. It also provides examples of command usages and configurations for setups and operations of these tools.










![[오픈소스컨설팅]Day #1 MySQL 엔진소개, 튜닝, 백업 및 복구, 업그레이드방법](https://cdn.slidesharecdn.com/ss_thumbnails/day1mysqlintroduction-141212003401-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[pgday.Seoul 2022] PostgreSQL구조 - 윤성재](https://cdn.slidesharecdn.com/ss_thumbnails/pgday2022-postgresql-20221112-221114014106-bbfb1955-thumbnail.jpg?width=640&height=640&fit=bounds)