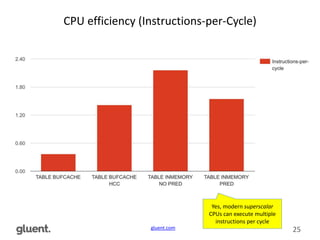
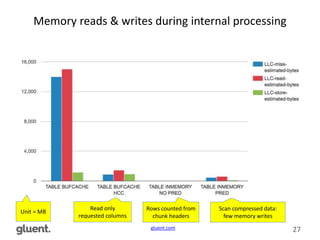
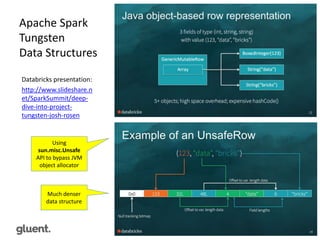
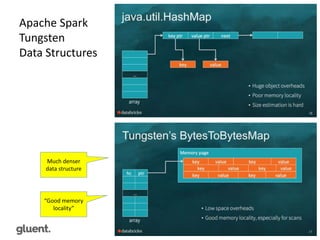
Downloaded 200 times



















![gluent.com 32
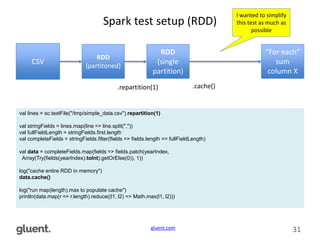
“SELECT” sum (Year) from RDD
// SUM all values of “year” column
println(data.map(d => d(yearIndex).asInstanceOf[Int]).reduce((y1, y2) => y1 + y2))
Cached RDD ~1M records, ~40 columns
1-column sum: 0.349 seconds!
17/01/19 18:43:36 INFO DAGScheduler: ResultStage 123 (reduce at demo.scala:89) finished in 0.349 s
17/01/19 18:43:36 INFO DAGScheduler: Job 61 finished: reduce at demo.scala:89, took 0.353754 s](https://image.slidesharecdn.com/lowlevelcpuperformanceprofiling-170120050719/85/Low-Level-CPU-Performance-Profiling-Examples-32-320.jpg)
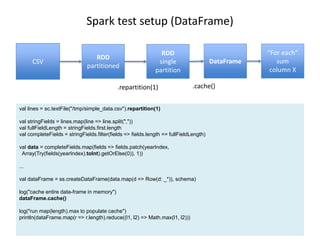
![gluent.com 34
“SELECT” sum (Year) from DataFrame (silly example!)
// SUM all values of “year” column
println(dataFrame.map(r => r(yearIndex).asInstanceOf[Int]).reduce((y1, y2) => y1 + y2))
17/01/19 19:39:25 INFO DAGScheduler: ResultStage 29 (reduce at demo.scala:71) finished in 4.664 s
17/01/19 19:39:25 INFO DAGScheduler: Job 14 finished: reduce at demo.scala:71, took 4.673204 s
Cached DataFrame: ~1M records, ~40 columns
1-column SUM: 4.67 seconds! (13x more than RDD?)
This does not
make sense!](https://image.slidesharecdn.com/lowlevelcpuperformanceprofiling-170120050719/85/Low-Level-CPU-Performance-Profiling-Examples-34-320.jpg)








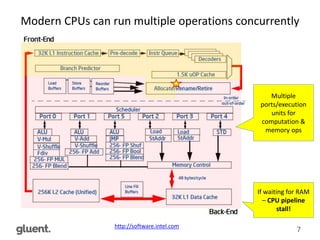
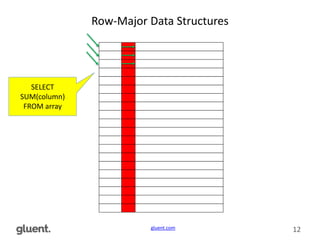
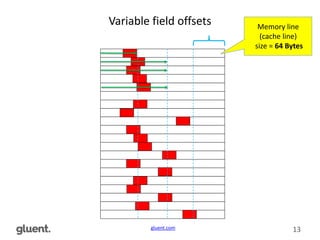
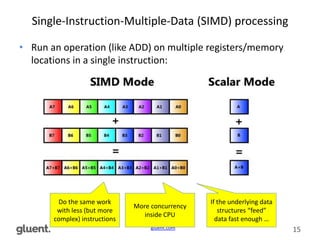
The document discusses low-level CPU performance profiling and modern CPU efficiency, emphasizing the importance of optimized data structures for improved performance. It covers various techniques and examples, including profiling methodologies for Oracle and Apache Spark environments, highlighting different data access paths and their effects on CPU usage. The content concludes by advocating for future-proof open data formats, such as Apache Parquet and Arrow, to enhance data processing efficiency.





































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)







