Download as PDF, PPTX















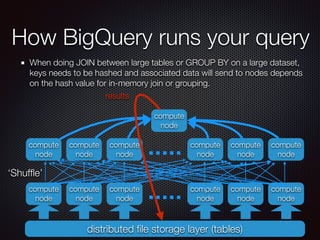




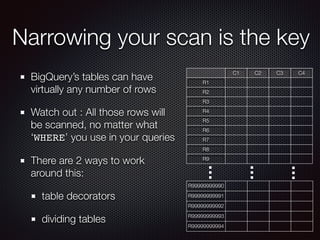


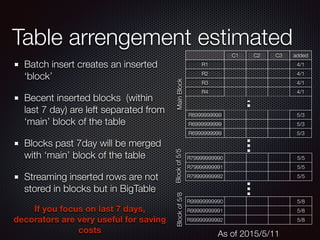


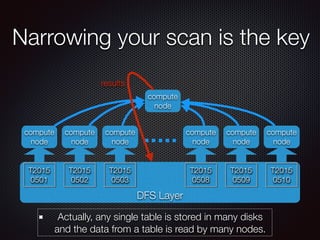






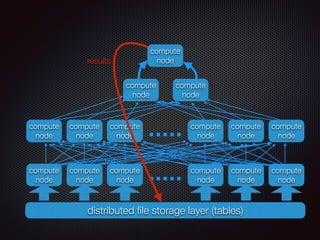
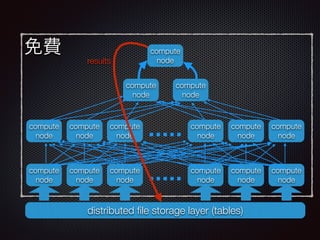
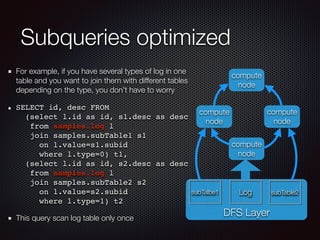



The document discusses the costs and functionalities associated with Google BigQuery, highlighting its features as a fully-managed data analytics service. It emphasizes the importance of optimizing queries to reduce costs, particularly by narrowing scans and utilizing techniques like table decorators and query caching. The document also outlines various operational aspects, such as data storage, query execution, and advanced tips for efficient usage of BigQuery.























































































