Downloaded 127 times



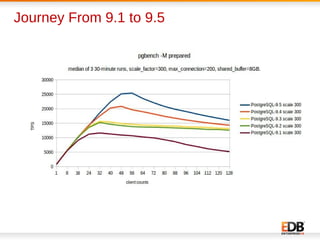

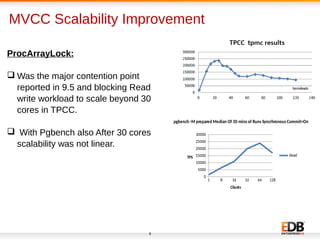
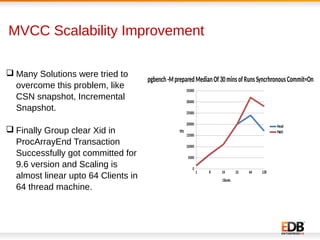

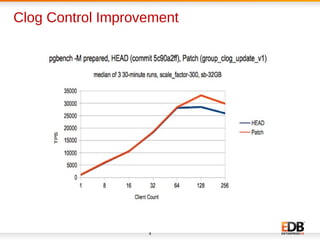

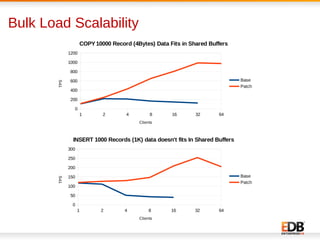

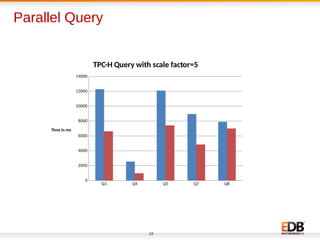

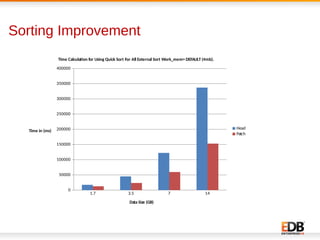

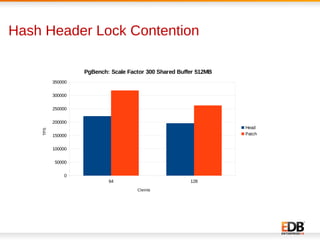


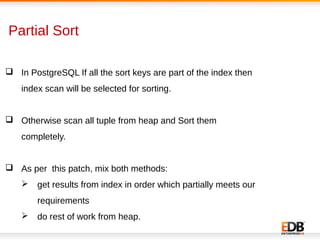

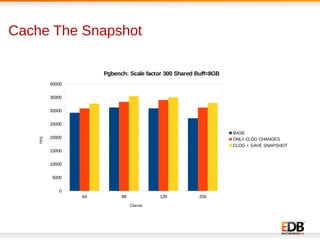

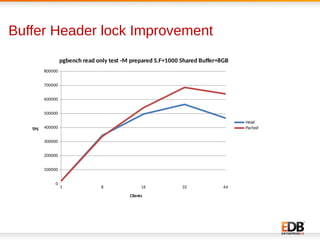

The document discusses scalability and performance improvements introduced in PostgreSQL 9.6, highlighting several key enhancements such as MVCC scalability, clog control, bulk load scalability, and improved parallel query processing. It details specific solutions implemented to address issues with lock contention and performance bottlenecks, alongside statistical testing results demonstrating the improvements. The author, Dilip Kumar, emphasizes the significant advancements achieved in this version compared to previous ones, tying it to his expertise and contributions in the field.





































![Slow things down to make them go faster [FOSDEM 2022]](https://cdn.slidesharecdn.com/ss_thumbnails/slowthingsdownfosdem-220206162647-thumbnail.jpg?width=640&height=640&fit=bounds)