Download as PDF, PPTX









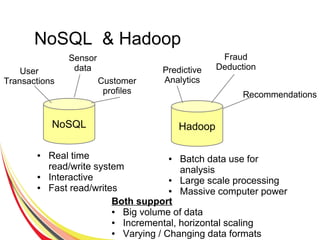













![Document Database Stores
{
FirstName: "Bart",
LastName: "Loews",
Children: [ {
FirstName:"Tadd",
Age: 4},
{
FirstName:"Todd",
Age:4}
],
Age: 35,
Address:{
number:1234,
street: "Fake road",
City: "Fake City",
state: "VA",
Country: "USA"
}
}](https://image.slidesharecdn.com/nosqlbigdataandpostgresql-160719061136/85/No-sql-bigdata-and-postgresql-27-320.jpg)
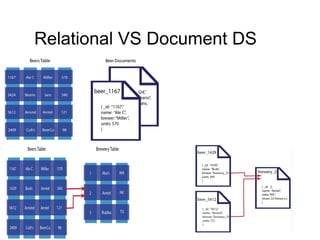
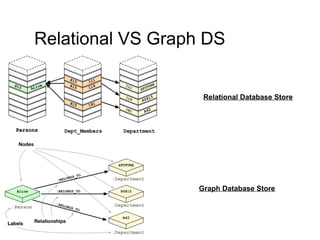
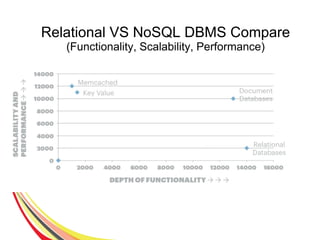
















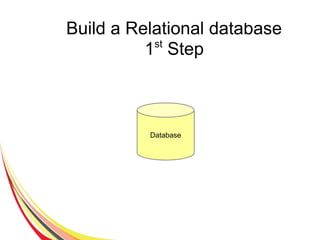
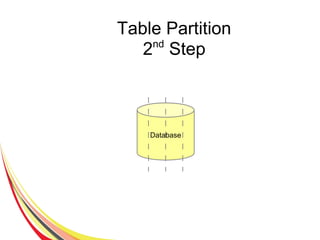
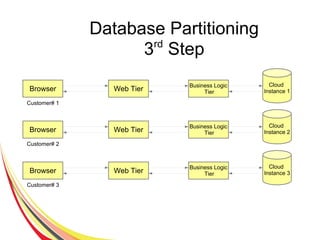
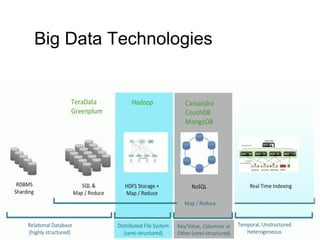
The document discusses the characteristics and benefits of NoSQL databases in the context of big data, contrasting it with traditional RDBMS. It highlights various NoSQL database types, such as key-value stores and document databases, along with their applications and challenges. Additionally, it describes how PostgreSQL integrates NoSQL features like JSON and hstore to provide flexibility and scalability while maintaining ACID compliance.












































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)














![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)