Download as PDF, PPTX
























The document discusses the implementation of high availability (HA) in PostgreSQL through the use of Pgpool-II and the improvements made over time, including the introduction of a watchdog for failure management. It emphasizes the importance of treating database servers as a herd to ensure seamless scalability and performance, while also addressing challenges such as single points of failure. Recent enhancements and features are highlighted, showcasing Pgpool-II's evolving reliability and efficiency in handling database management.
Overview of PostgreSQL High Availability (HA) with the Pgpool-II tool, emphasizing recent developments.
Introduction of Muhammad Usama, Database Architect at EnterpriseDB and Pgpool-II developer.
Discussion on treating servers as pets vs. cattle, highlighting key differences in handling failures.
Using a herd approach for database servers to achieve scalability, requiring leader election and failure management systems.
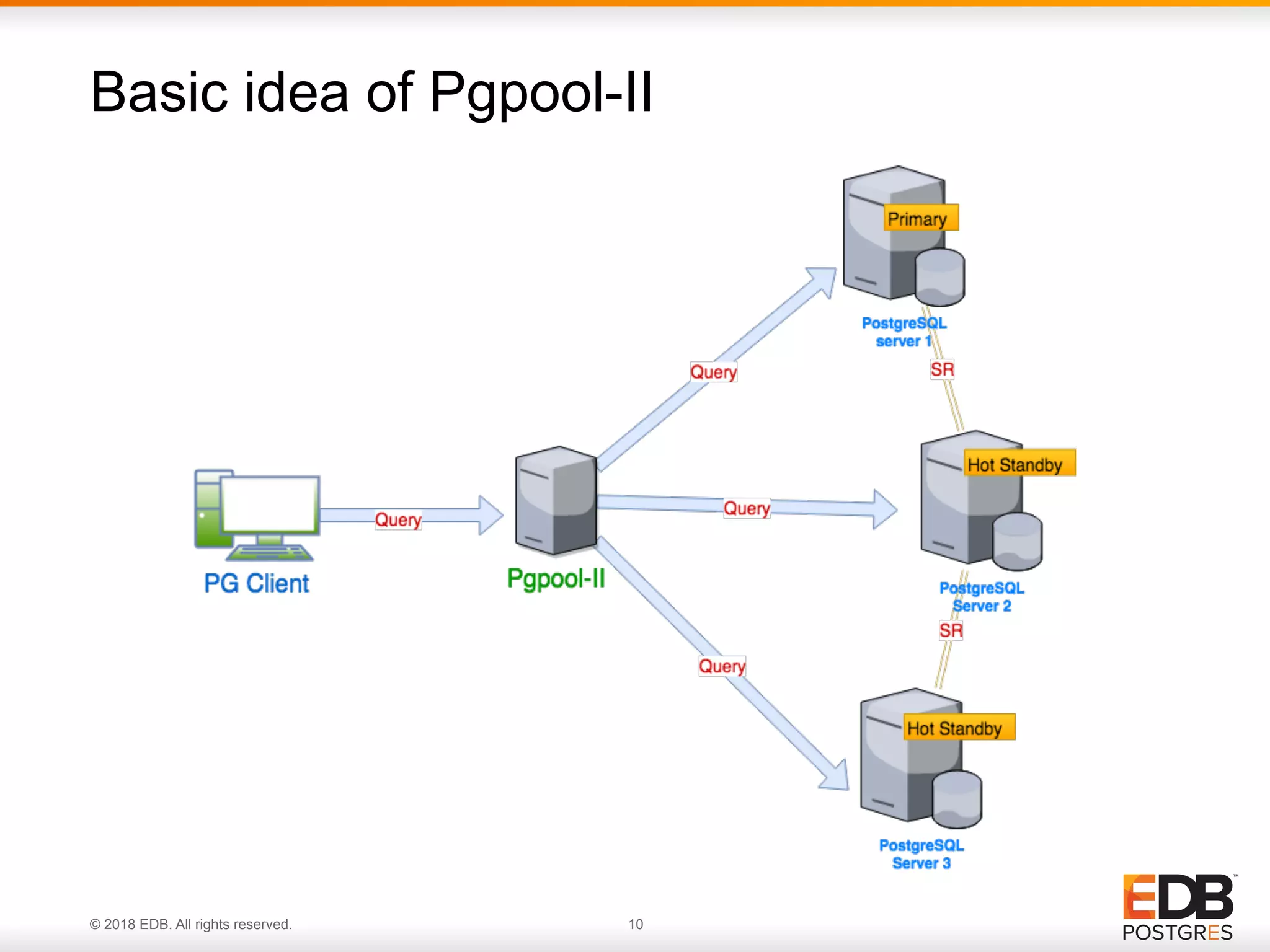
Pgpool-II is a cluster management tool for PostgreSQL, offering connection pooling, load balancing, and automated failover.
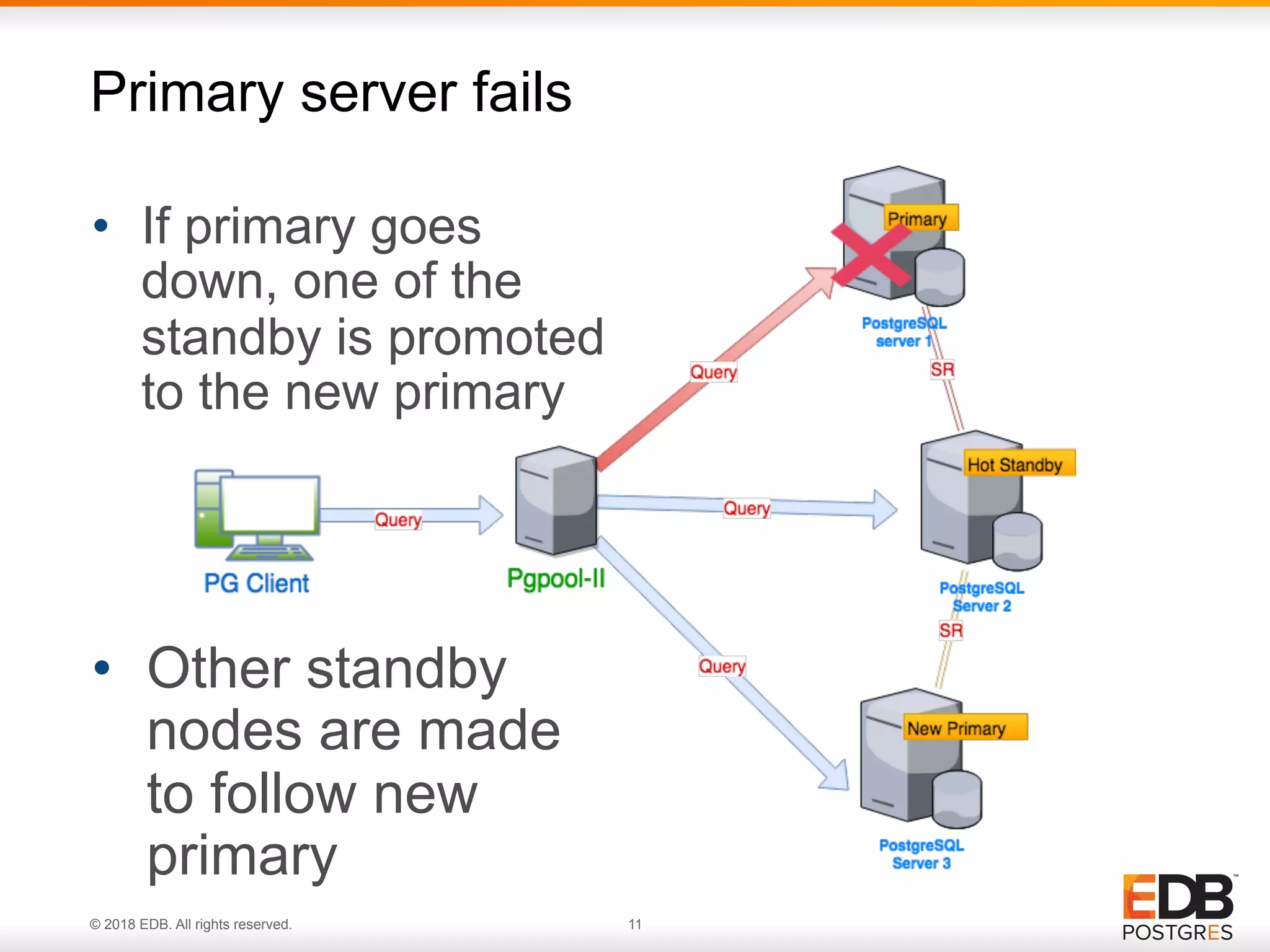
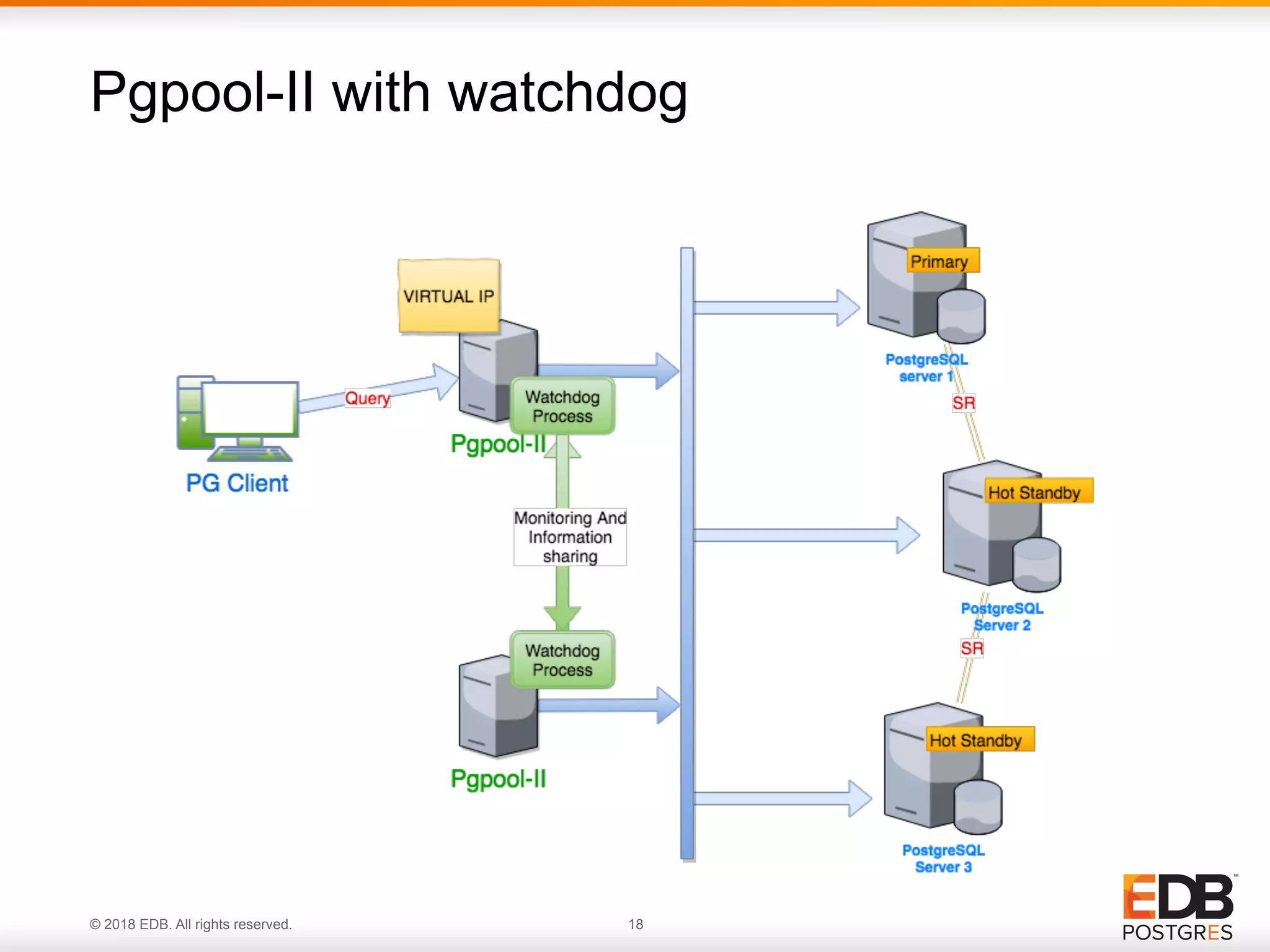
Failover procedures in Pgpool-II for primary and standby servers, ensuring service continuity during failures.
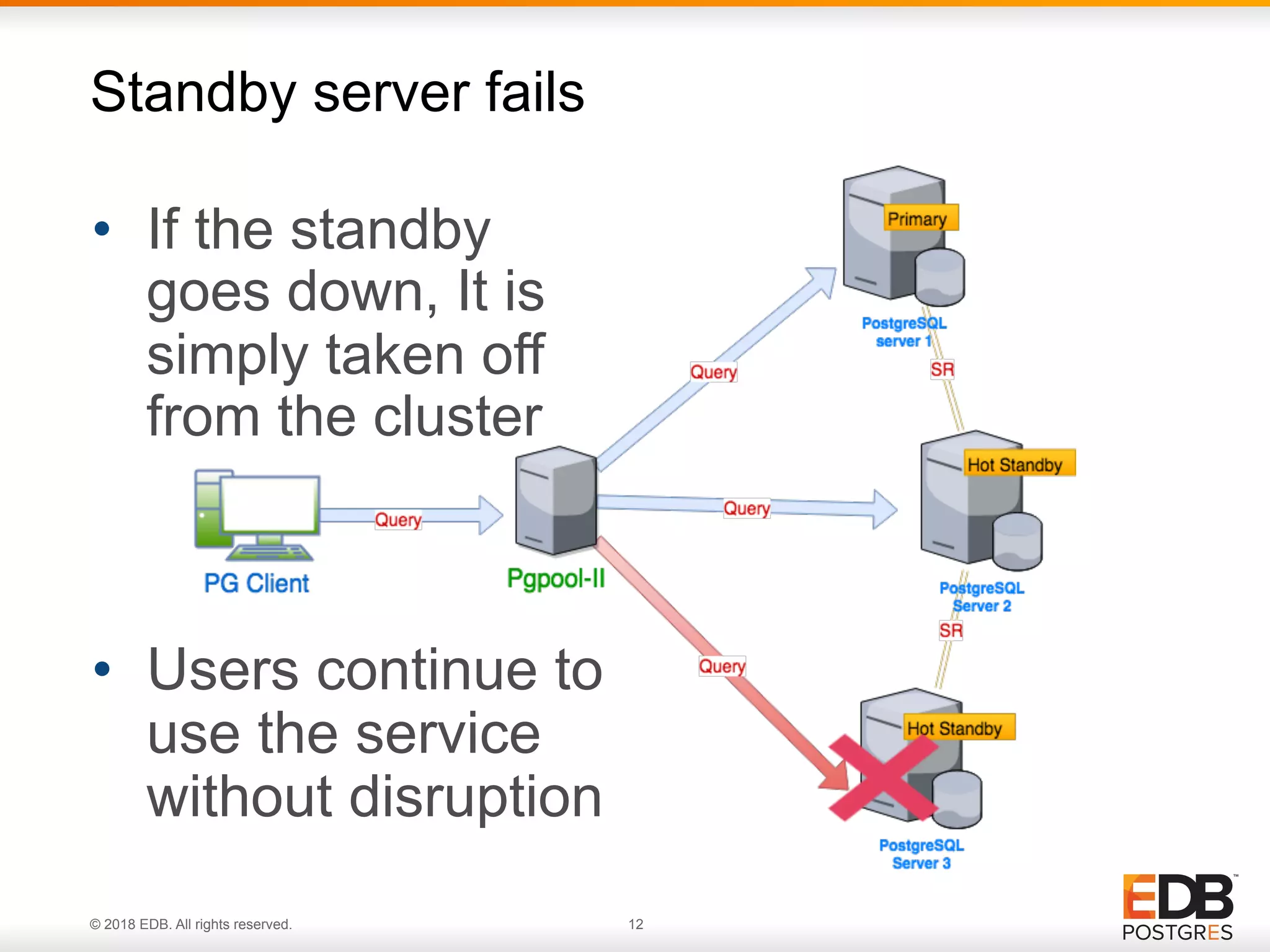
Pgpool-II's mechanism to detach nodes and ensure automatic failover, focusing on service availability during failures.
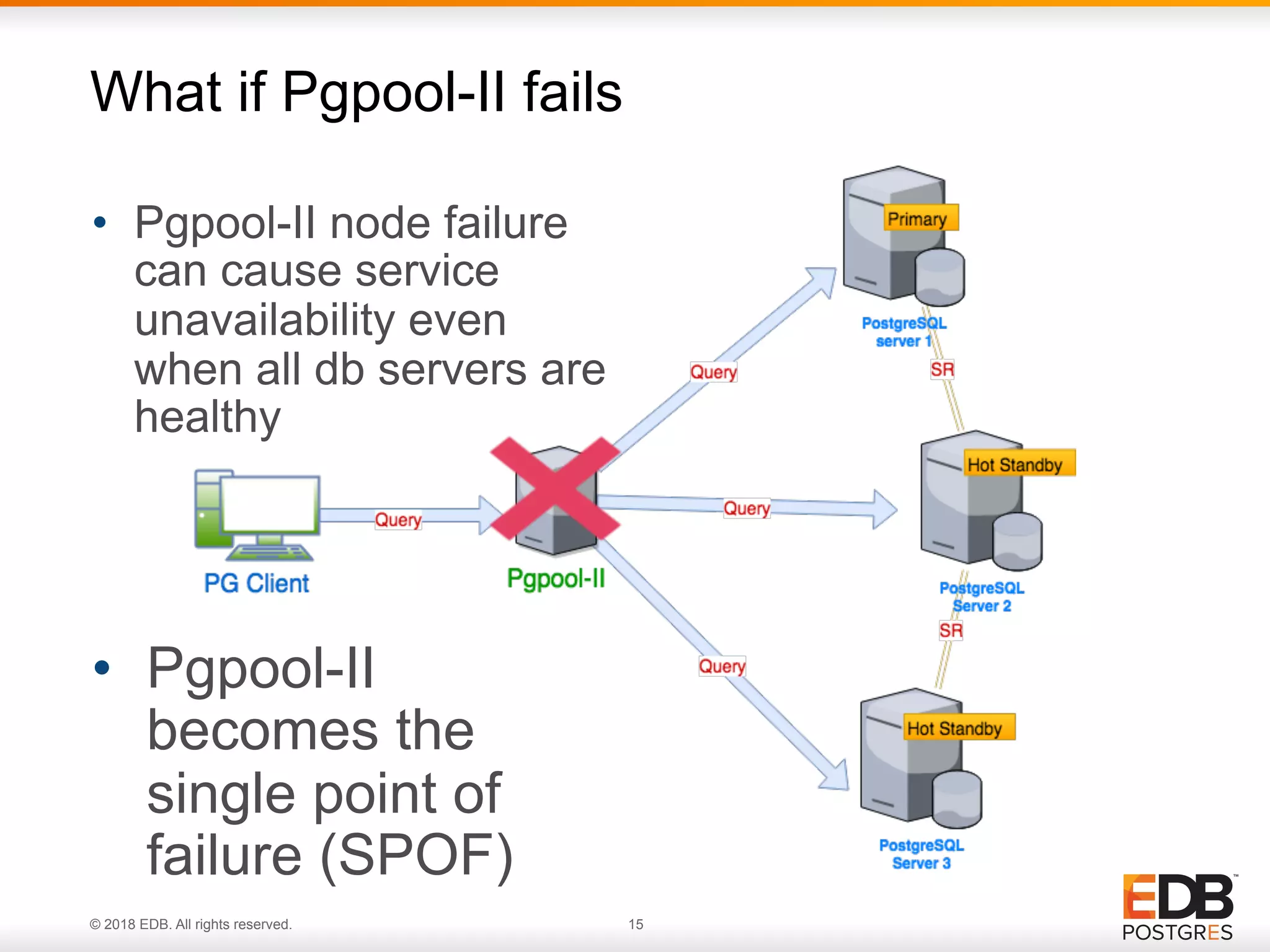
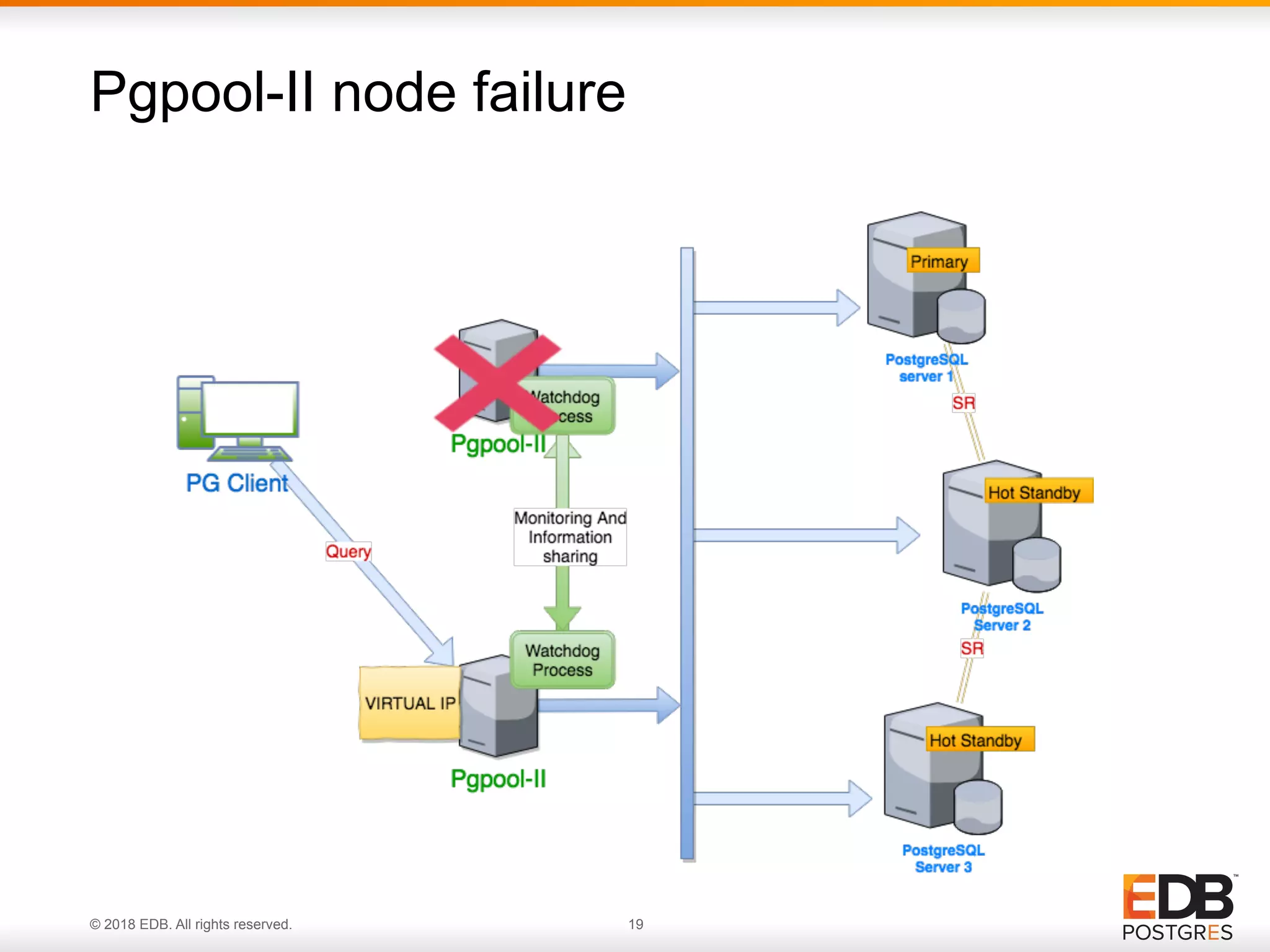
Identifying the single point of failure (SPOF) in Pgpool-II and the need for additional solutions.
Overview of Watchdog, a Pgpool-II sub-process managing failures, leader election, and ensuring consistent states across nodes.
Highlighting improvements in Pgpool-II, such as enhancements to Watchdog, failover processes, and overall performance.
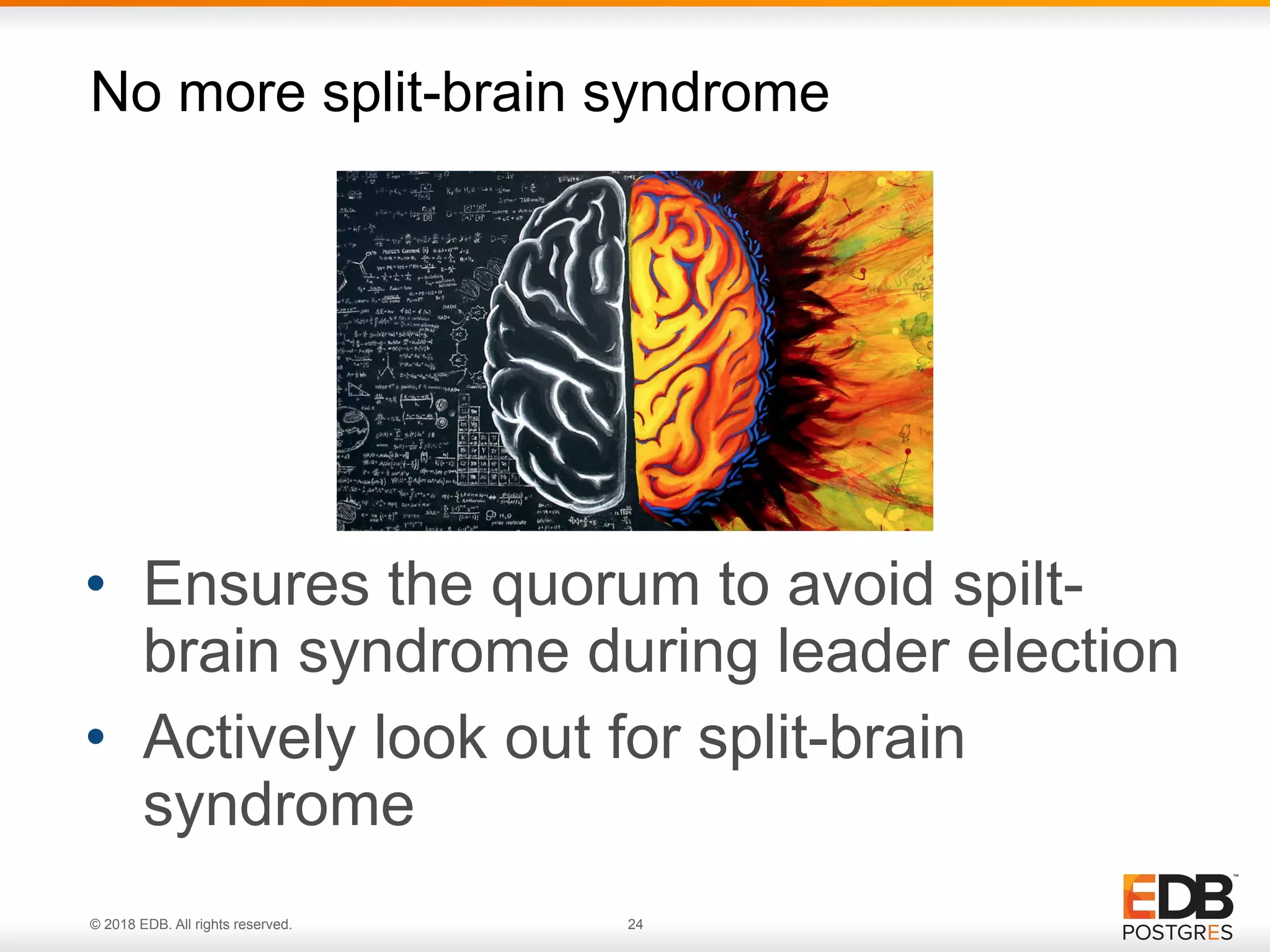
Improvements of Watchdog in Pgpool-II version 3.5, addressing split-brain syndrome and enhancing leader election.
Recent performance updates in Pgpool-II, including enhancements in query performance and backend health checks.
Mention of upcoming features like new authentication methods and links to further development information.
Closing remarks and thanks for attending the presentation.






















![4.[d2 오픈세미나]LINE Rangers 게임 클라이언트/서버 아키텍쳐](https://cdn.slidesharecdn.com/ss_thumbnails/4-140905000018-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















