Download to read offline




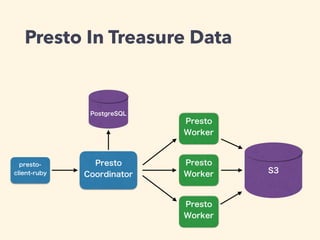
















Presto was updated from version 0.152 to 0.178. New features in the update include lambda expressions, filtered aggregation, a VALIDATE mode for EXPLAIN, compressed exchange, and complex grouping operations. The update also added new functions and deprecated some legacy features with warnings. Future work on Presto includes disk spill optimization and a cost-based optimizer.











































































































