Downloaded 28 times

















![In our example
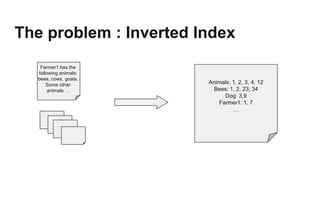
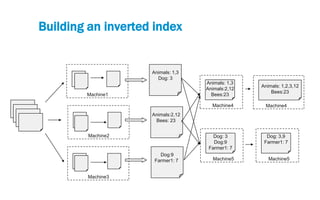
‣ Map: (doc-num, text) ➝ [(word, doc-num)]
‣ Reduce: (word, [doc1, doc3, ...]) ➝ [(word, “doc1, doc3, …”)]
General form:
‣ Two functions: Map and Reduce
‣ Operate on key and value pairs
‣ Map: (K1, V1) ➝ list(K2, V2)
‣ Reduce: (K2, list(V2)) ➝ (K3, V3)
‣ Primitives present in Lisp and other functional languages
Same principle extended to distributed computing
‣ Map and Reduce tasks run on distributed sets of machines
This is Map-Reduce](https://image.slidesharecdn.com/hadoop-fundamentals-140321091100-phpapp01/85/Hadoop-Fundamentals-21-320.jpg)

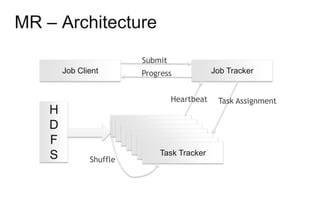

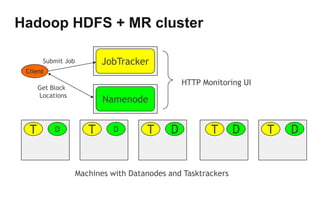

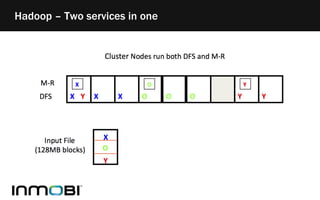




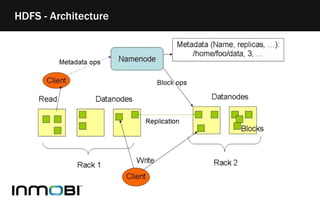
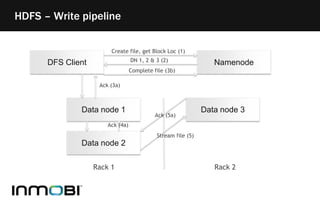
The document discusses Hadoop as a distributed data storage and processing infrastructure, capable of handling large-scale data from a variety of sources. It explains the Hadoop Distributed File System (HDFS) architecture, its fault tolerance, and how data is managed with blocks across multiple nodes. Additionally, it covers the MapReduce programming model that allows for efficient data processing across a cluster of machines.













































































