Downloaded 11 times





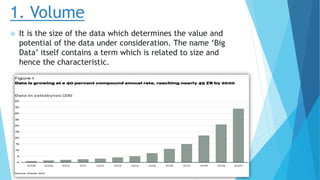











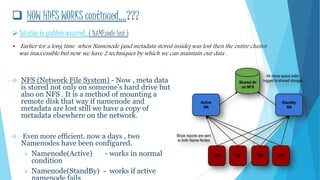

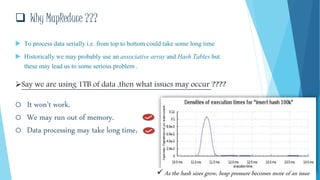

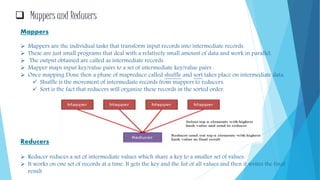
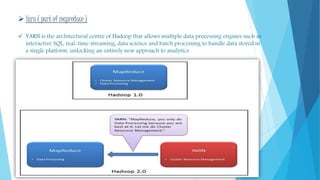
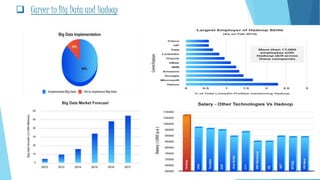


This document provides an overview of big data and Hadoop. It defines big data using the 3Vs - volume, variety, and velocity. It describes Hadoop as an open-source software framework for distributed storage and processing of large datasets. The key components of Hadoop are HDFS for storage and MapReduce for processing. HDFS stores data across clusters of commodity hardware and provides redundancy. MapReduce allows parallel processing of large datasets. Careers in big data involve working with Hadoop and related technologies to extract insights from large and diverse datasets.


















































































