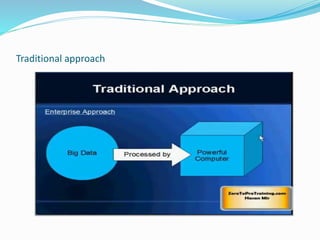
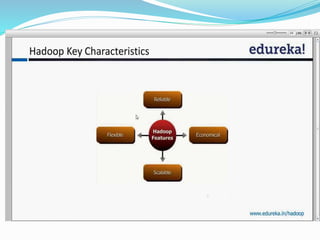
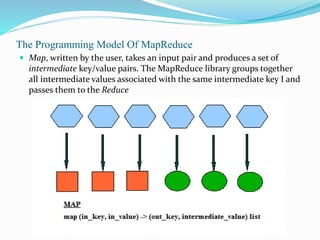
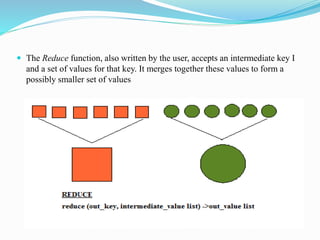
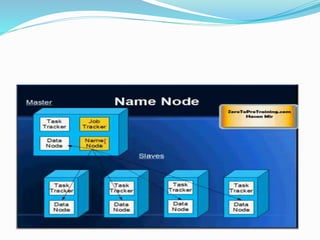
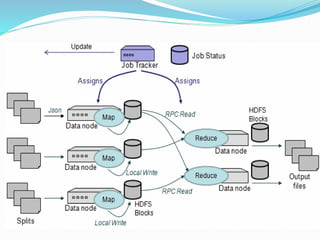
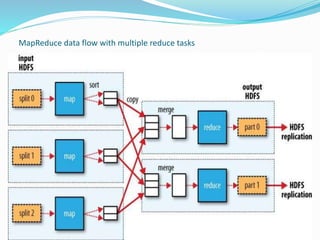
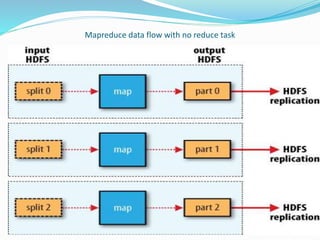
This document provides an overview of Hadoop and how it addresses the challenges of big data. It discusses how Hadoop uses a distributed file system (HDFS) and MapReduce programming model to allow processing of large datasets across clusters of computers. Key aspects summarized include how HDFS works using namenodes and datanodes, how MapReduce leverages mappers and reducers to parallelize processing, and how Hadoop provides fault tolerance.