Downloaded 103 times



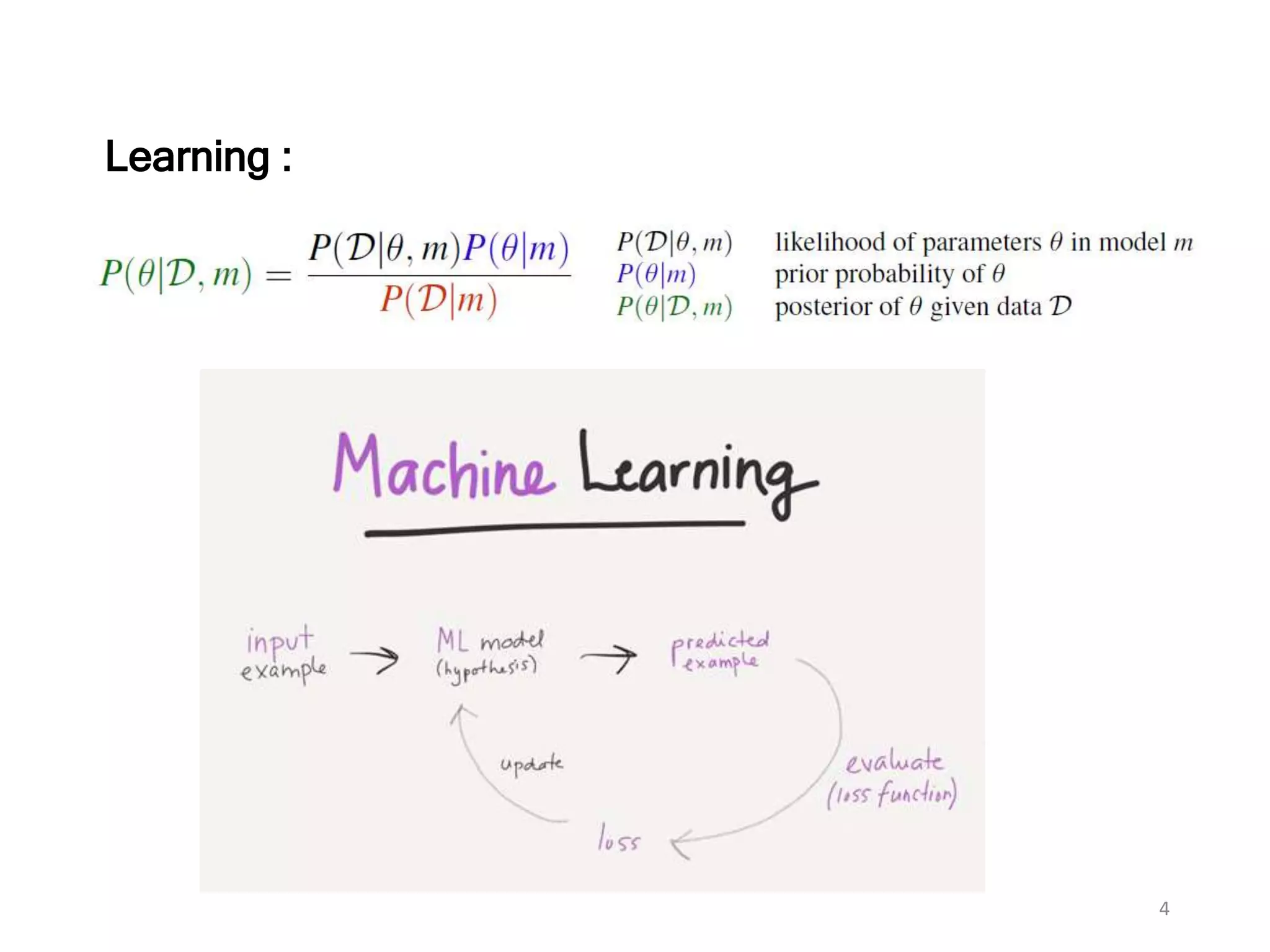
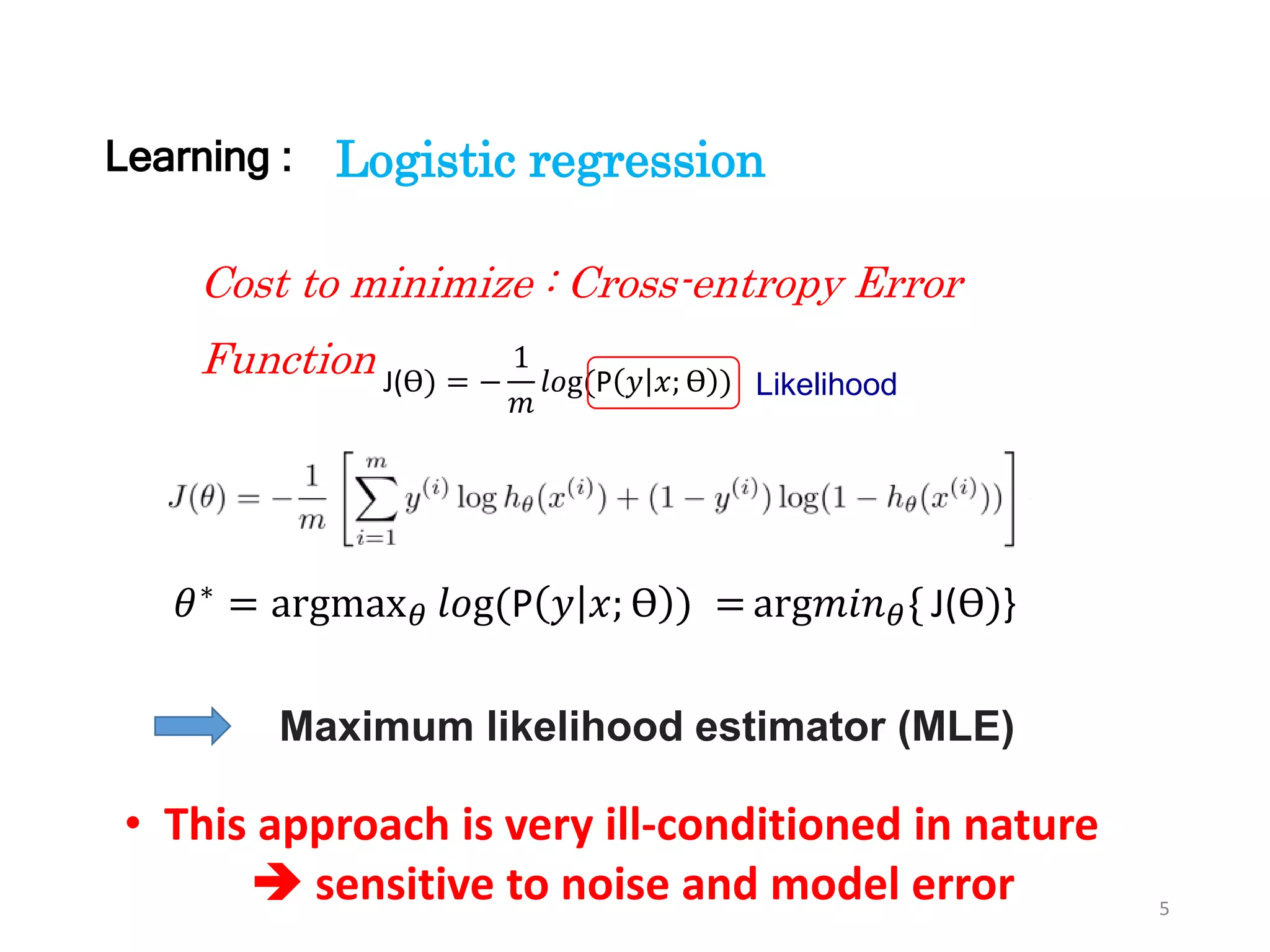














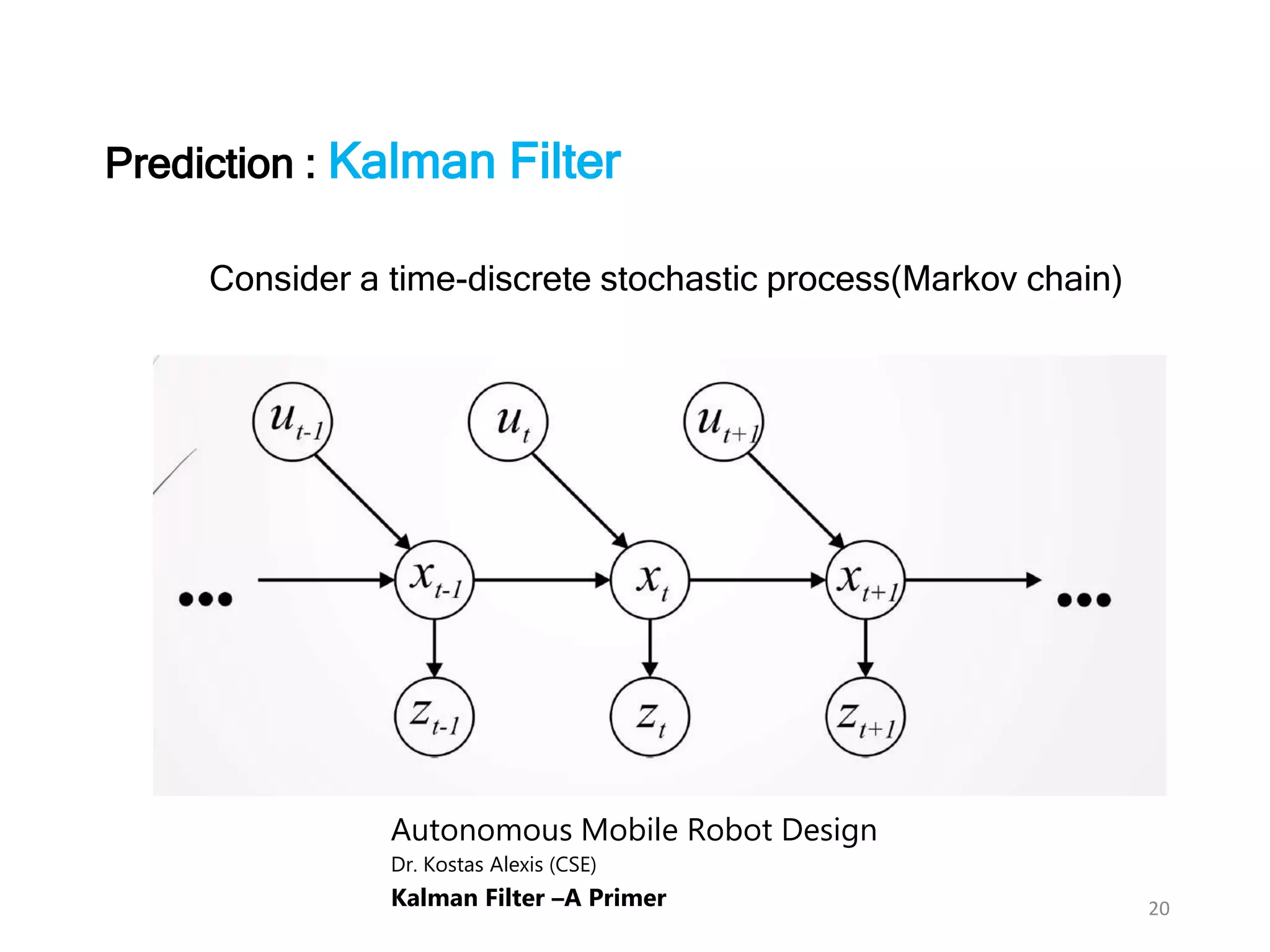



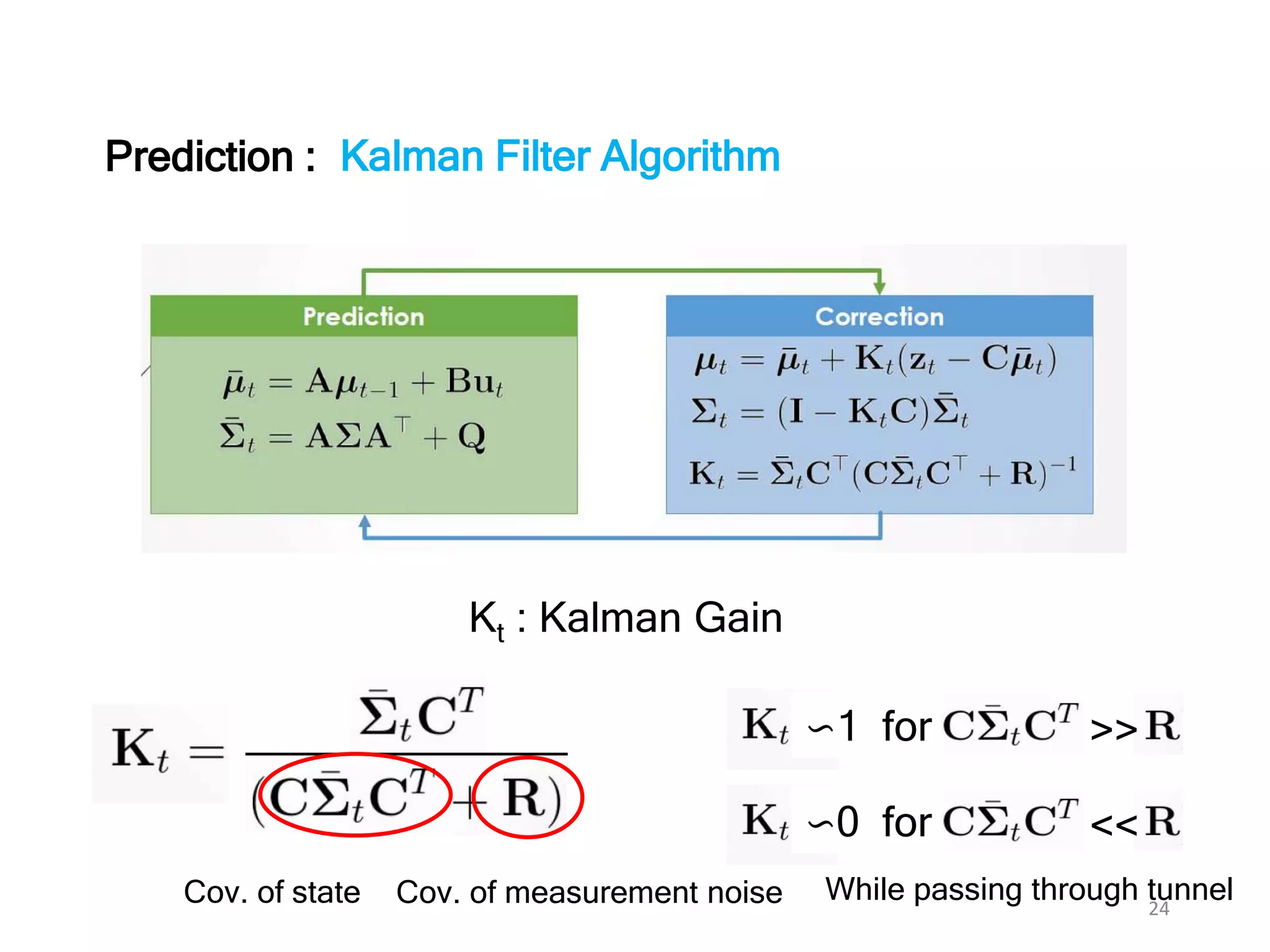
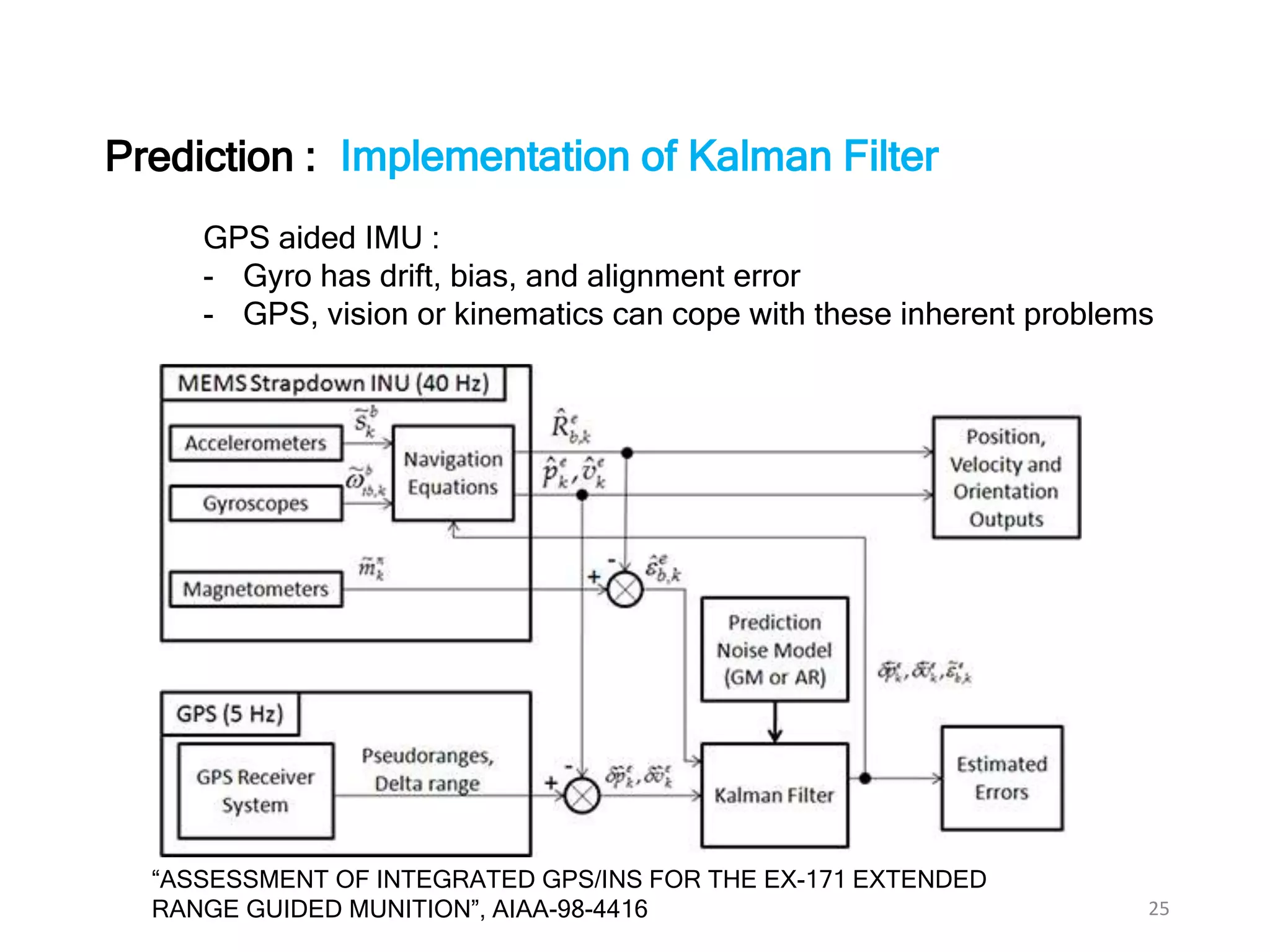
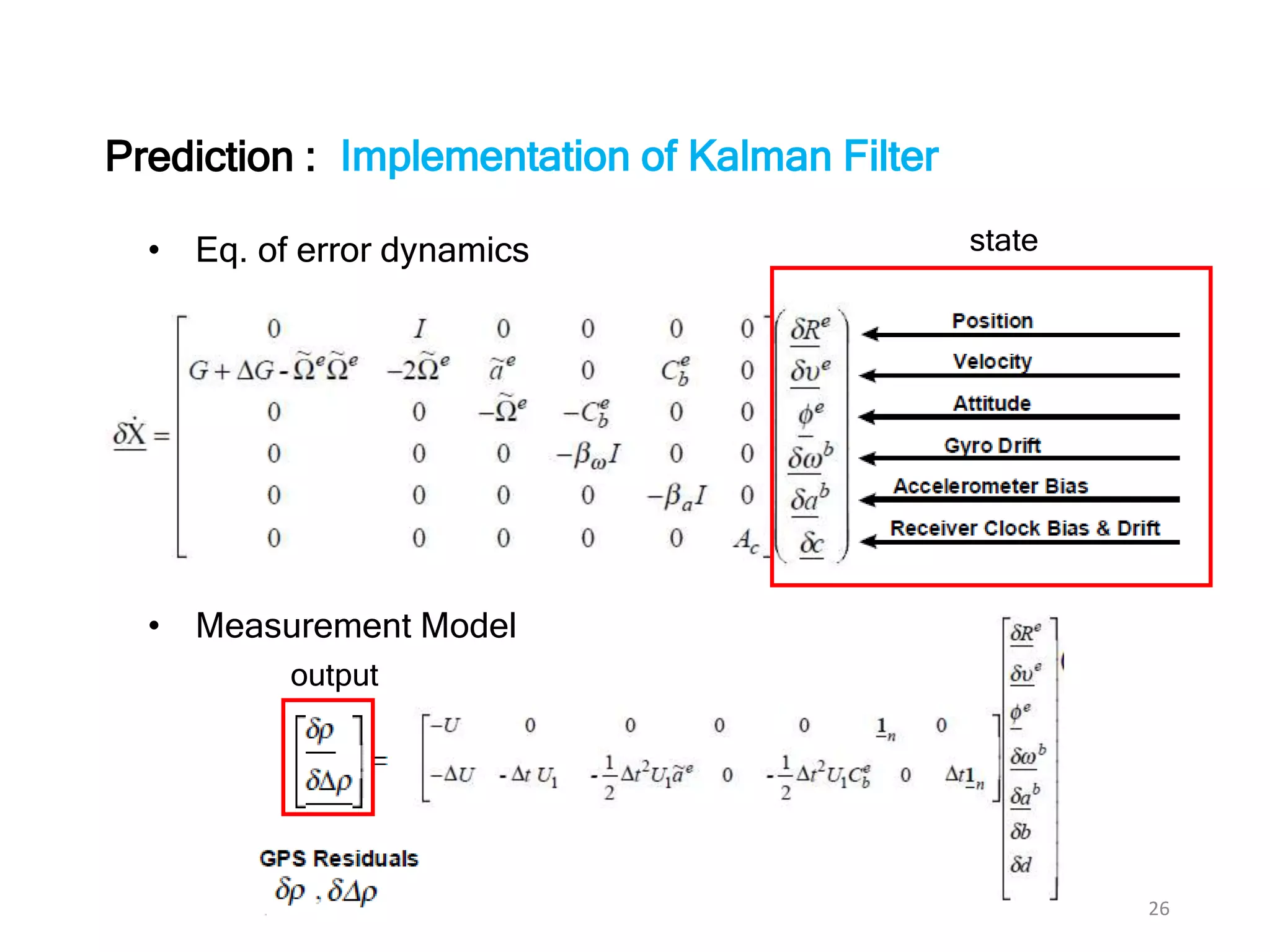
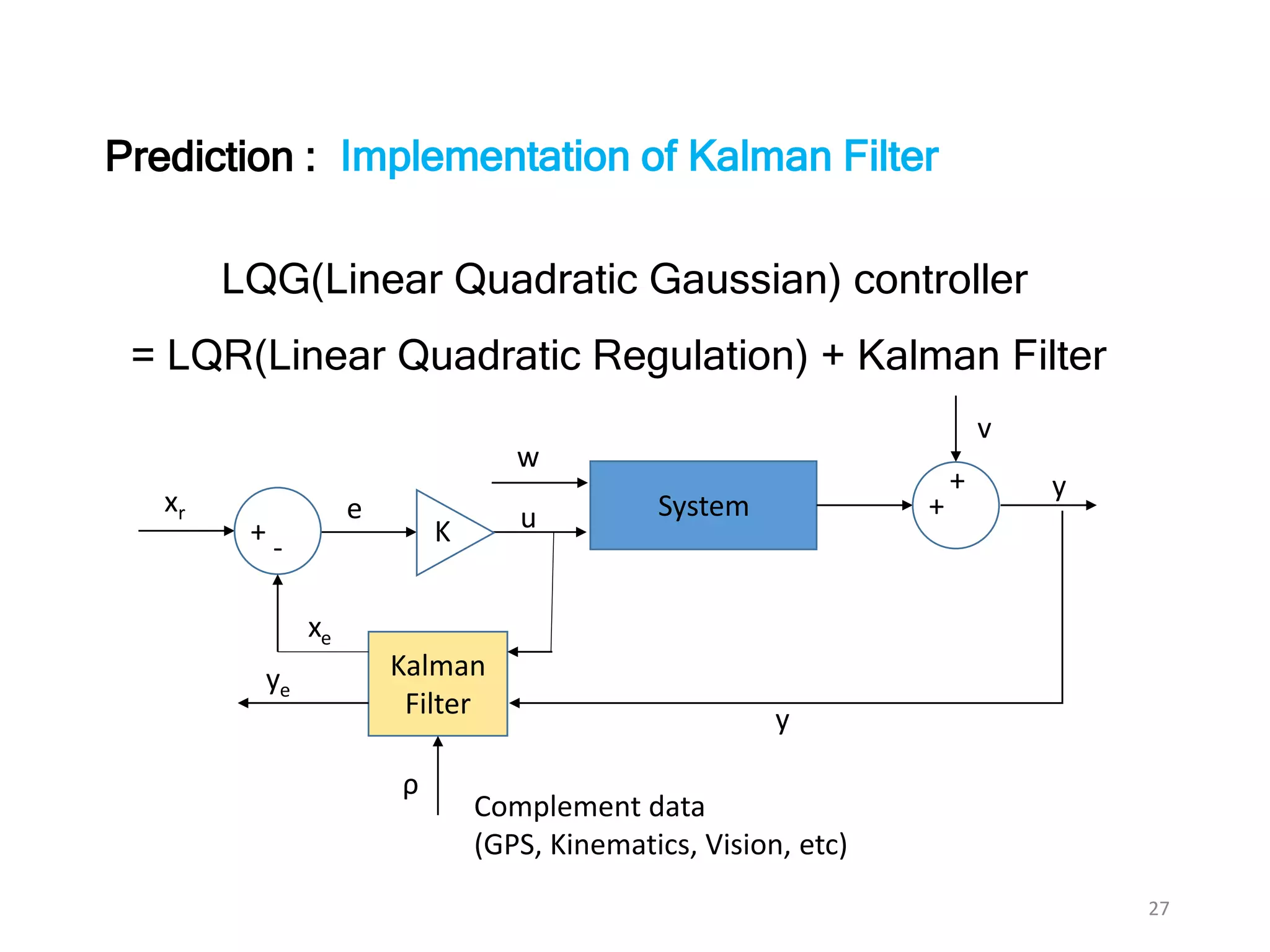





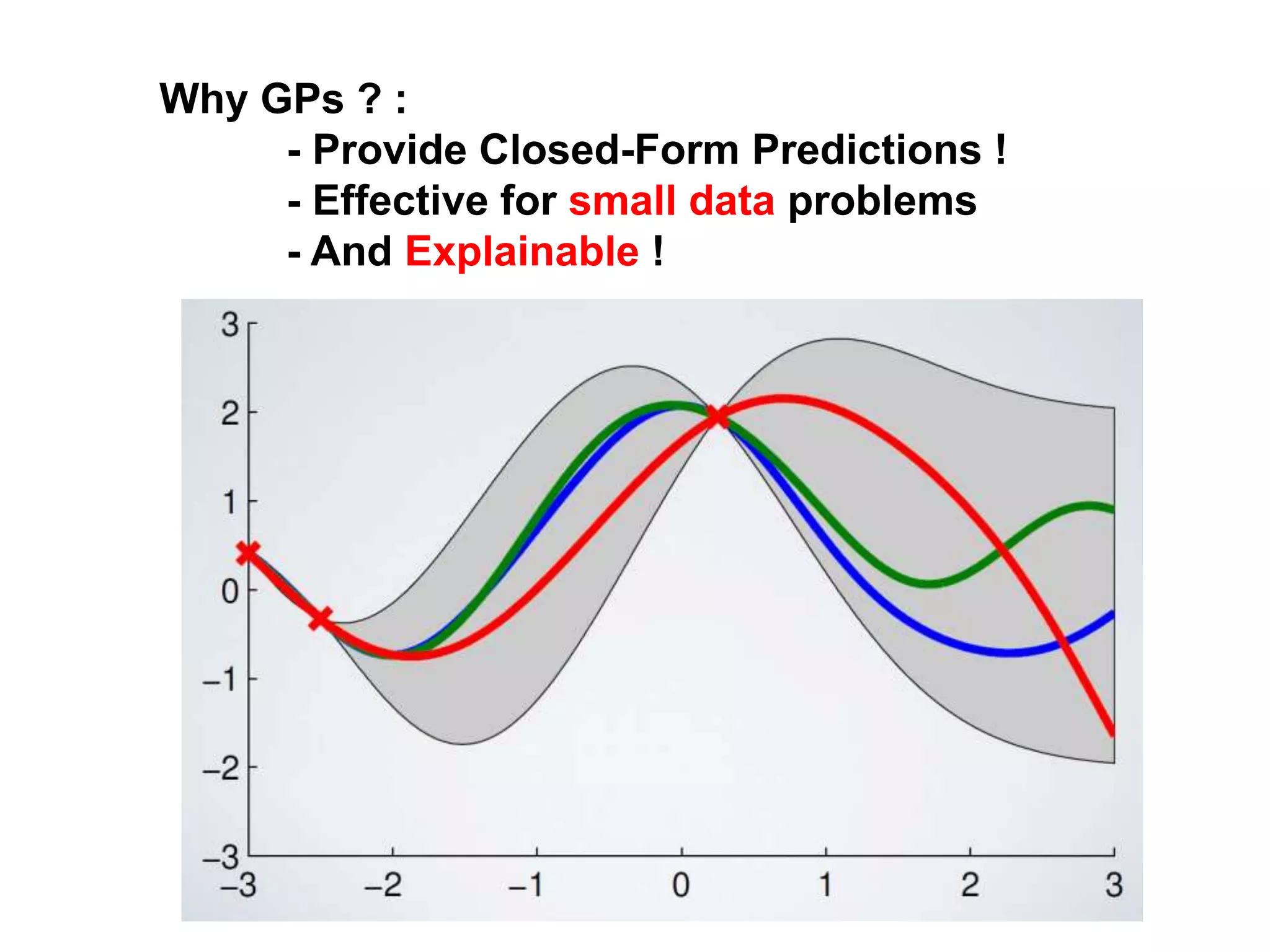

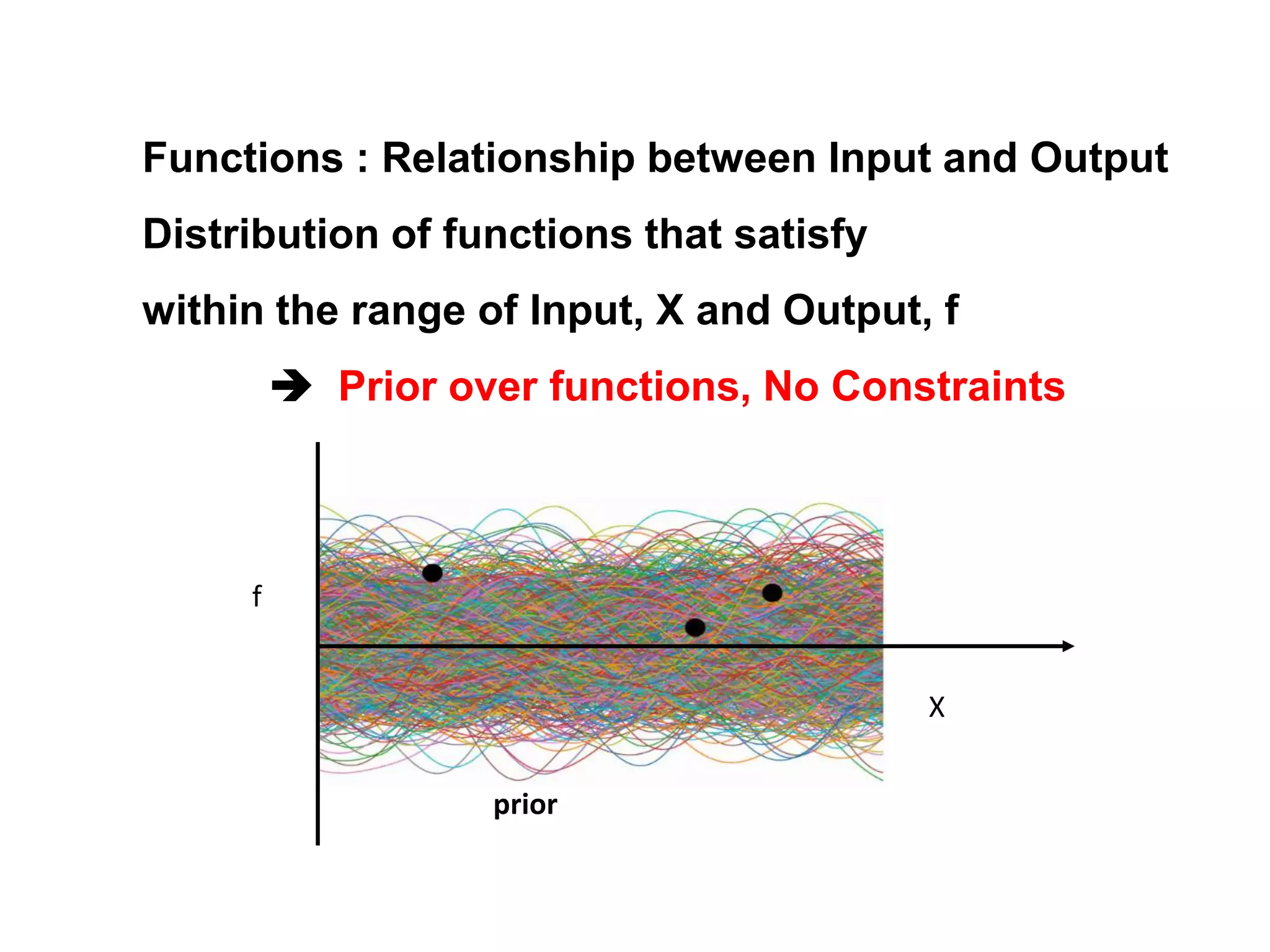

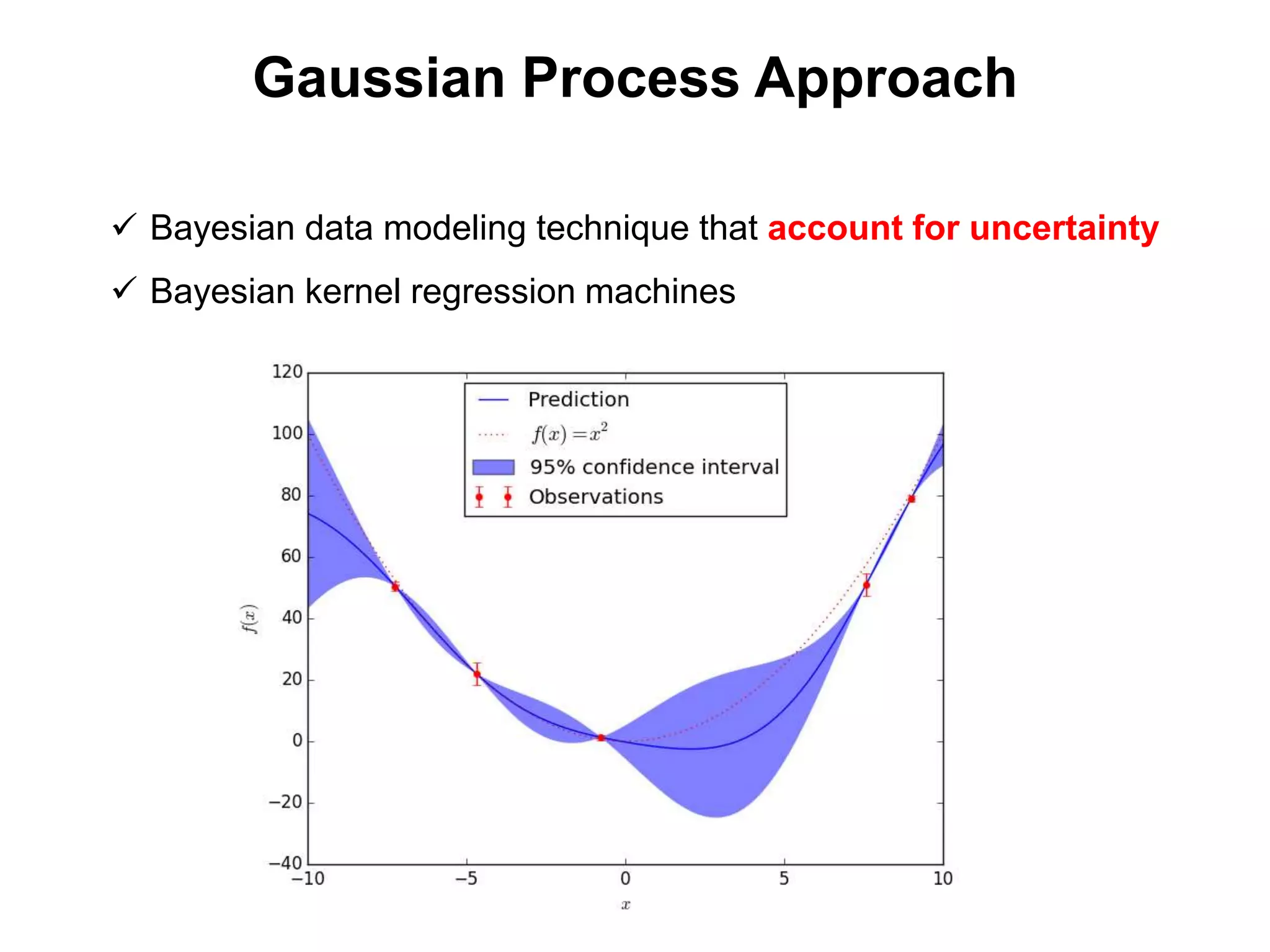
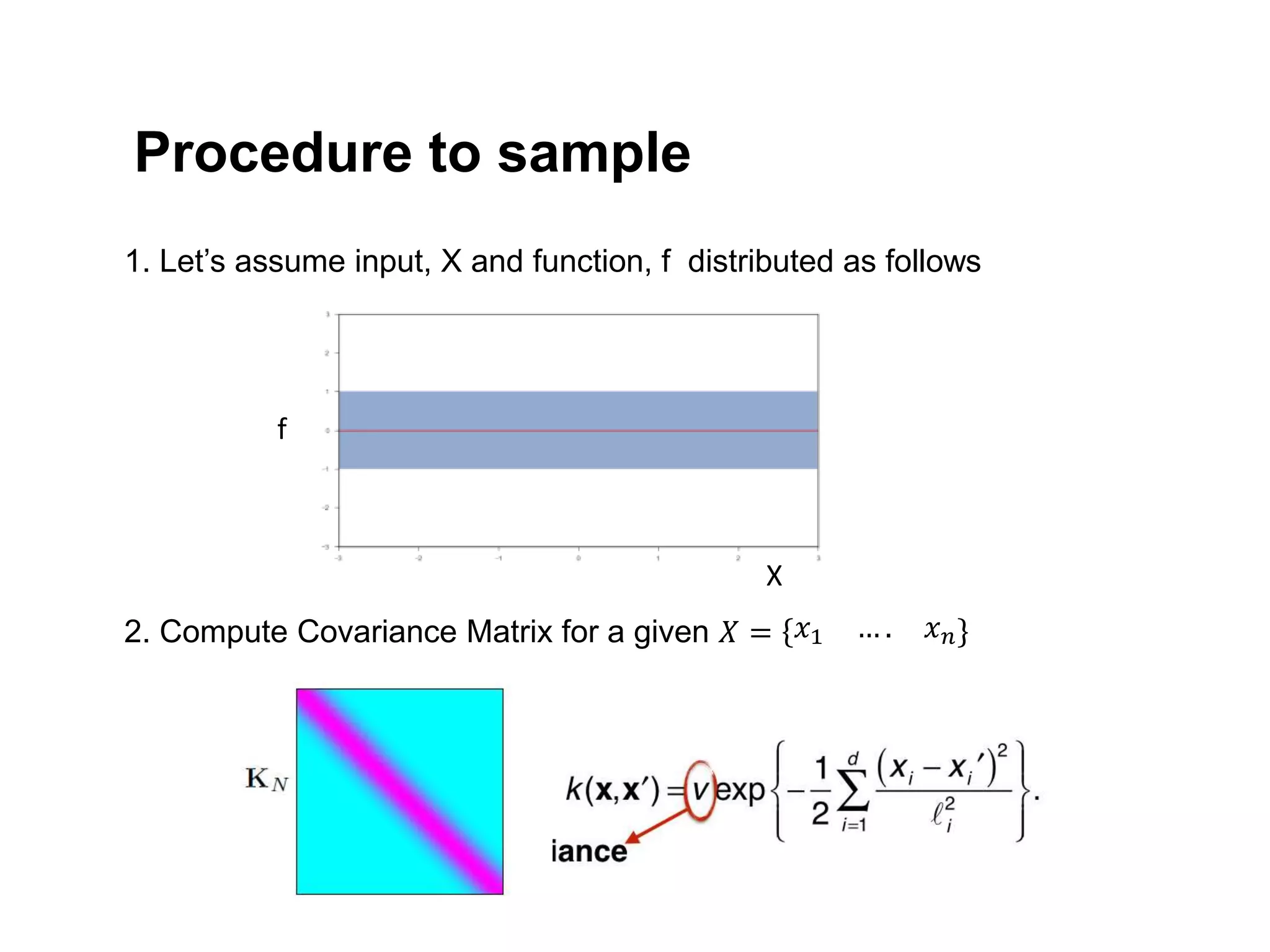
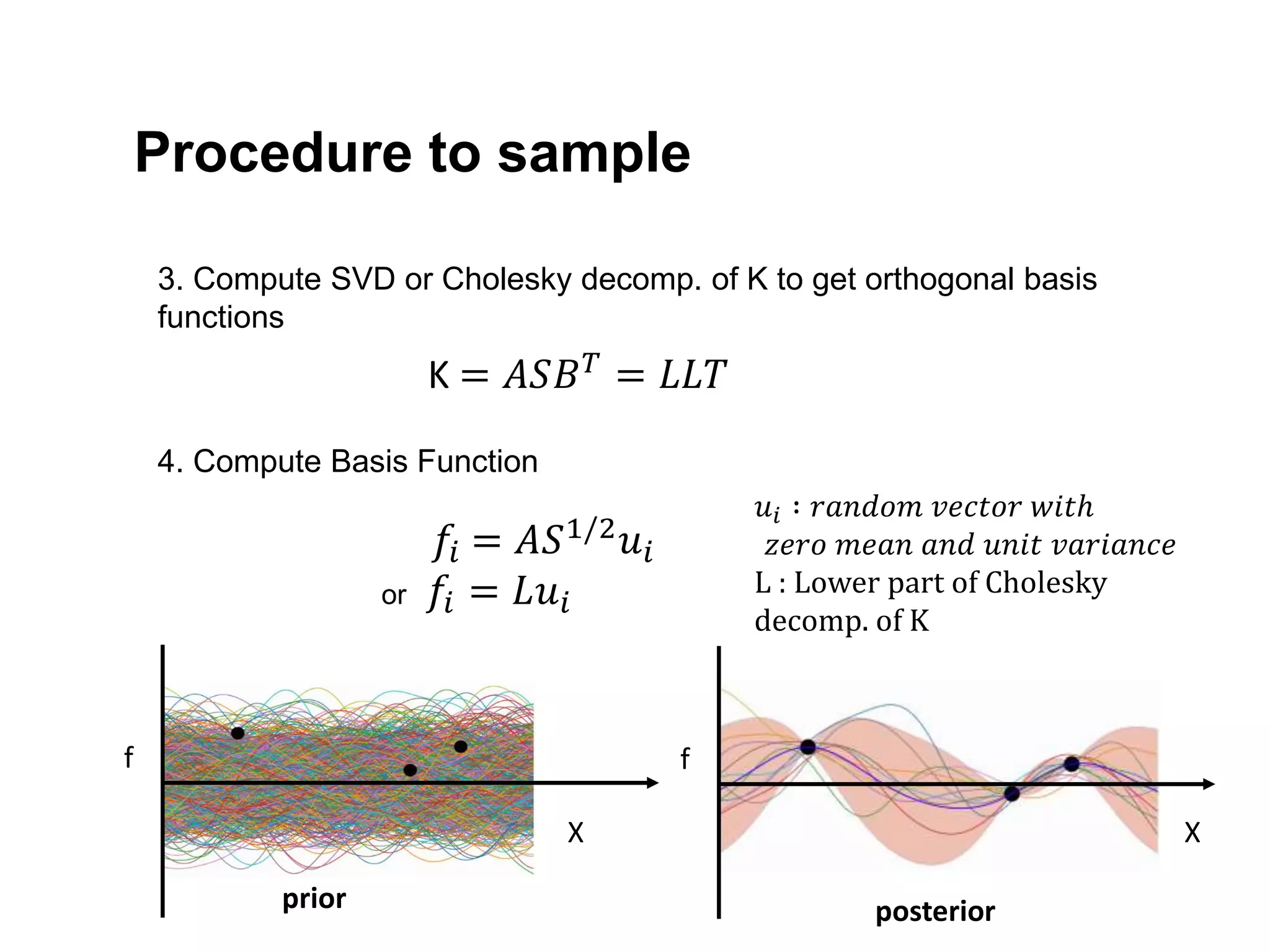

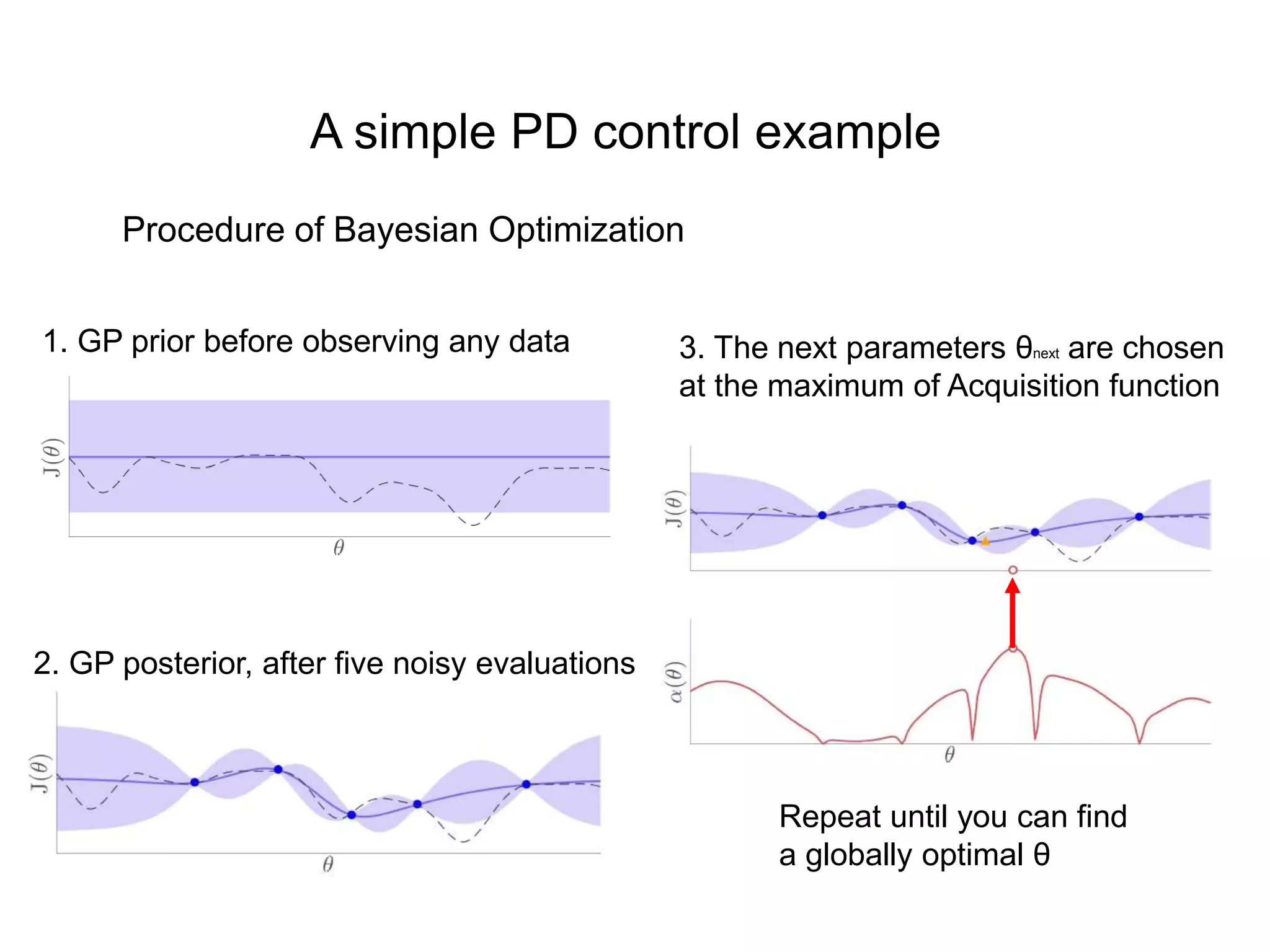
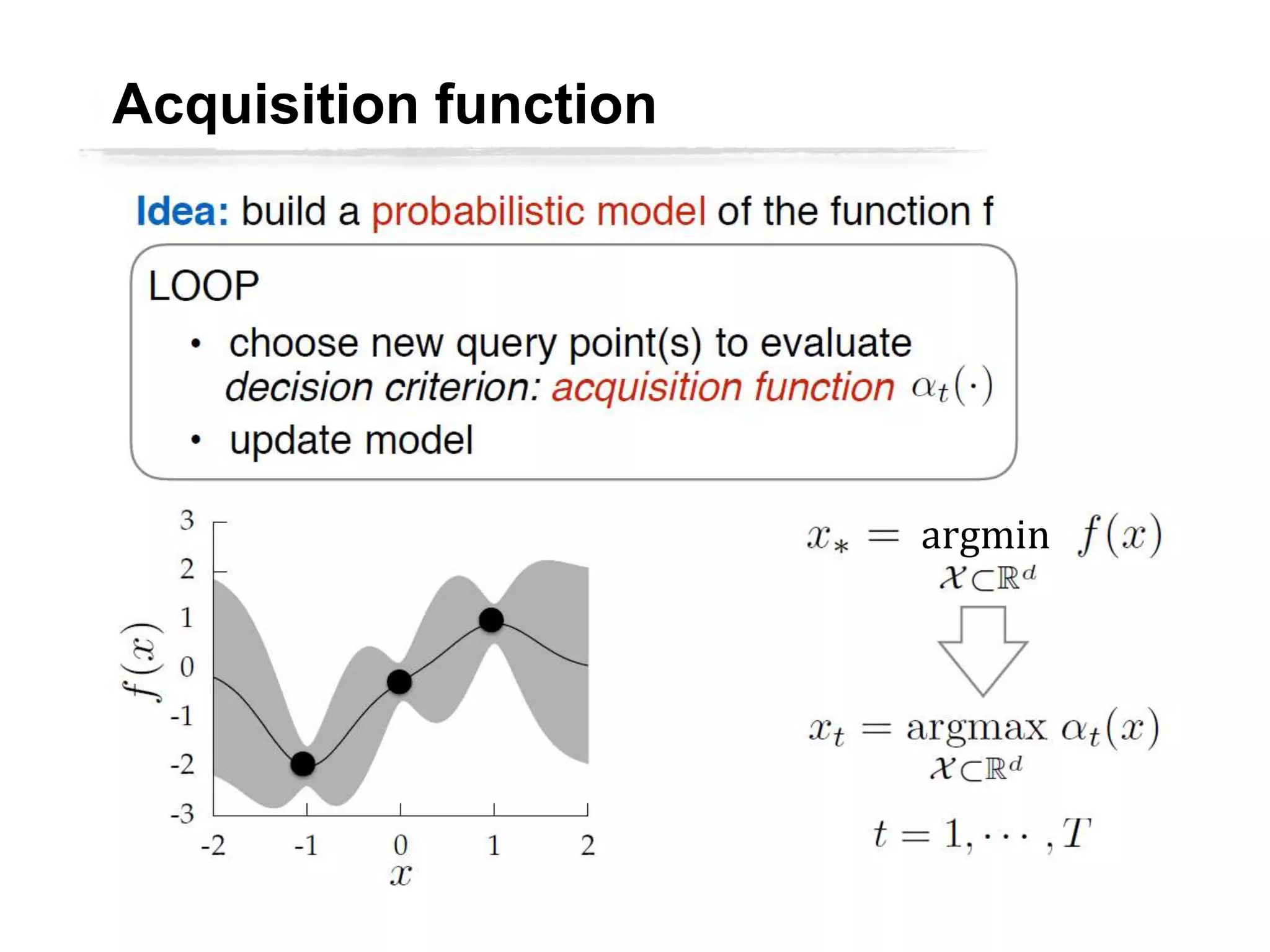


The document discusses Bayesian inference, focusing on learning, prediction, and optimization, with a particular emphasis on tools like the Kalman filter and Bayesian optimization techniques. It covers concepts such as maximum a posteriori estimation, regularized logistic regression, and Gaussian processes for modeling uncertainty in data. Additionally, it outlines the algorithmic implementations and methodologies for applying these Bayesian techniques in various settings.
















































![Sensor Fusion Study - Real World 2: GPS & INS Fusion [Stella Seoyeon Yang]](https://cdn.slidesharecdn.com/ss_thumbnails/gpsins-200817095309-thumbnail.jpg?width=640&height=640&fit=bounds)
![Sensor Fusion Study - Ch14. The Unscented Kalman Filter [Sooyoung Kim]](https://cdn.slidesharecdn.com/ss_thumbnails/ukf-200817092334-thumbnail.jpg?width=640&height=640&fit=bounds)
![Sensor Fusion Study - Real World 1: Lidar radar fusion [Kim Soo Young]](https://cdn.slidesharecdn.com/ss_thumbnails/lidarradarfusion-200815095222-thumbnail.jpg?width=640&height=640&fit=bounds)
![Sensor Fusion Study - Ch15. The Particle Filter [Seoyeon Stella Yang]](https://cdn.slidesharecdn.com/ss_thumbnails/particlefilter-200815094542-thumbnail.jpg?width=640&height=640&fit=bounds)
![Sensor Fusion Study - Ch13. Nonlinear Kalman Filtering [Ahn Min Sung]](https://cdn.slidesharecdn.com/ss_thumbnails/nonlinearkalmanfiltering200717-200815094232-thumbnail.jpg?width=640&height=640&fit=bounds)
![Sensor Fusion Study - Ch12. Additional Topics in H-Infinity Filtering [Hayden]](https://cdn.slidesharecdn.com/ss_thumbnails/ch12-200815075328-thumbnail.jpg?width=640&height=640&fit=bounds)
![Sensor Fusion Study - Ch11. The H-Infinity Filter [김영범]](https://cdn.slidesharecdn.com/ss_thumbnails/11h-inf-200815075146-thumbnail.jpg?width=640&height=640&fit=bounds)

![Sensor Fusion Study - Ch9. Optimal Smoothing [Hayden]](https://cdn.slidesharecdn.com/ss_thumbnails/optimalsmoothing-200815074615-thumbnail.jpg?width=640&height=640&fit=bounds)
![Sensor Fusion Study - Ch8. The Continuous-Time Kalman Filter [이해구]](https://cdn.slidesharecdn.com/ss_thumbnails/chapter8-thecontinuoustimekalmanfilter-200715035017-thumbnail.jpg?width=640&height=640&fit=bounds)
![Sensor Fusion Study - Ch7. Kalman Filter Generalizations [김영범]](https://cdn.slidesharecdn.com/ss_thumbnails/ch7kalmanfiltergeneralizations-200715034919-thumbnail.jpg?width=640&height=640&fit=bounds)
![Sensor Fusion Study - Ch6. Alternate Kalman filter formulations [Jinhyuk Song]](https://cdn.slidesharecdn.com/ss_thumbnails/ch6alternative-200712162741-thumbnail.jpg?width=640&height=640&fit=bounds)
![Sensor Fusion Study - Ch5. The discrete-time Kalman filter [박정은]](https://cdn.slidesharecdn.com/ss_thumbnails/ch5-200712161939-thumbnail.jpg?width=640&height=640&fit=bounds)
![Sensor Fusion Study - Ch3. Least Square Estimation [강소라, Stella, Hayden]](https://cdn.slidesharecdn.com/ss_thumbnails/chapter3-200521130800-thumbnail.jpg?width=640&height=640&fit=bounds)
![Sensor Fusion Study - Ch4. Propagation of states and covariance [김동현]](https://cdn.slidesharecdn.com/ss_thumbnails/optimisticstudychapter4-200520224531-thumbnail.jpg?width=640&height=640&fit=bounds)
![Sensor Fusion Study - Ch2. Probability Theory [Stella]](https://cdn.slidesharecdn.com/ss_thumbnails/chapter2-200424170905-thumbnail.jpg?width=640&height=640&fit=bounds)
![Sensor Fusion Study - Ch1. Linear System [Hayden]](https://cdn.slidesharecdn.com/ss_thumbnails/osech1slide-200424170544-thumbnail.jpg?width=640&height=640&fit=bounds)




















