Downloaded 40 times



















![Inner Product
The inner product of two vectors a = [a1, a2, ..., an] and
b = [b1, b2, ..., bn] is defined as
a · b = Σn
i=1ai bi = a1b1 + a2b2 + ... + anbn.
Inner product operation can be viewed as the simplest kernel function.
K(xn, xm) = xT
n xm.
Kejia Shi Parallel Bayesian Optimization August 16, 2017 25 / 49](https://image.slidesharecdn.com/meetup-171107062602/75/Parallel-Bayesian-Optimization-25-2048.jpg)








![Acquisition Function: Overview
How to utilize the posterior model to create such acquisition functions?
A setting of the model hyperparameters θ
An arbitrary query point x and its correponding function value
v = f (x)
Map them to a utility function U = U(x, v, θ)
Now the acquisition function can be defined as an integration over all its
parameters, i.e. v|x, θ and θ, the selection of the n + 1 point given its
previous data Dn,
a(x; Dn) = EθEv|x,θ[U(x, v, θ)].
Kejia Shi Parallel Bayesian Optimization August 16, 2017 34 / 49](https://image.slidesharecdn.com/meetup-171107062602/75/Parallel-Bayesian-Optimization-34-2048.jpg)
![Acquisition Function: Marginalization
Deal with a(x; Dn) = EθEv|x,θ[U(x, v, θ)] is very complicated.
We start from the outer expectation over unknown hyperparameters θ.
We wish to marginalize out our uncertainty about θ with
an(x) Eθ|Dn
[a(x; θ)] = a(x; θ)p(θ|Dn)dθ.
Notice: from Bayes Rule, p(θ|Dn) = p(y|X,θ)p(θ)
p(Dn) .
Two ways to tackle the marginalized acquisition function:
Point estimate ˆθ = ˆθML or ˆθMAP , therefore ˆan(x) = a(x; ˆθn).
Sampling from posterior distribution p(θ|Dn), {θ
(i)
n }S
i=1, therefore
Eθ|Dn
[a(x; θ)] ≈ 1
S ΣS
i=1a(x; θ
(i)
n )
Idea: By far we can ignore the θ dependence!
Kejia Shi Parallel Bayesian Optimization August 16, 2017 35 / 49](https://image.slidesharecdn.com/meetup-171107062602/75/Parallel-Bayesian-Optimization-35-2048.jpg)

![Acquisition Function: Improvement-based Policies
Favors points that are likely to improve upon an incumbent target τ!
Notice τ in practice is set to the best observed value, i.e. maxi=1:n yi .
Probability of improvement(PI):
Earliest idea
aPI (x; Dn) P(v > τ) = Φ(µn(x)−τ
σn(x) )
Expected improvement(EI):
Improvement function, I(x): I(x, v, θ) (v − τ)I(v > τ)
aEI (x; Dn) E[I(x, v, θ)] = (µn(x) − τ)Φ(µn(x)−τ
σn(x) ) + σn(x)φ(µn(x)−τ
σn(x) )
Kejia Shi Parallel Bayesian Optimization August 16, 2017 37 / 49](https://image.slidesharecdn.com/meetup-171107062602/75/Parallel-Bayesian-Optimization-37-2048.jpg)



![Parallelization
1. On Query Methods (Or Mostly,) Acquisition Function:
Most common: Expected Improvements
Snoek et al. 2012, Spearmint: Monte Carlo Acquisition Function
Wang et al. 2016, MOE (Yelp)[12]: q-EI, argmaxx1, , xqEI(x1, ..., xq)
- Construct an unbiased estimator of EI(x1, , xq) using infinitesimal
perturbation analysis (IPA)
- Turn to a gradient estimator problem under certain assumptions
Kejia Shi Parallel Bayesian Optimization August 16, 2017 43 / 49](https://image.slidesharecdn.com/meetup-171107062602/75/Parallel-Bayesian-Optimization-43-2048.jpg)
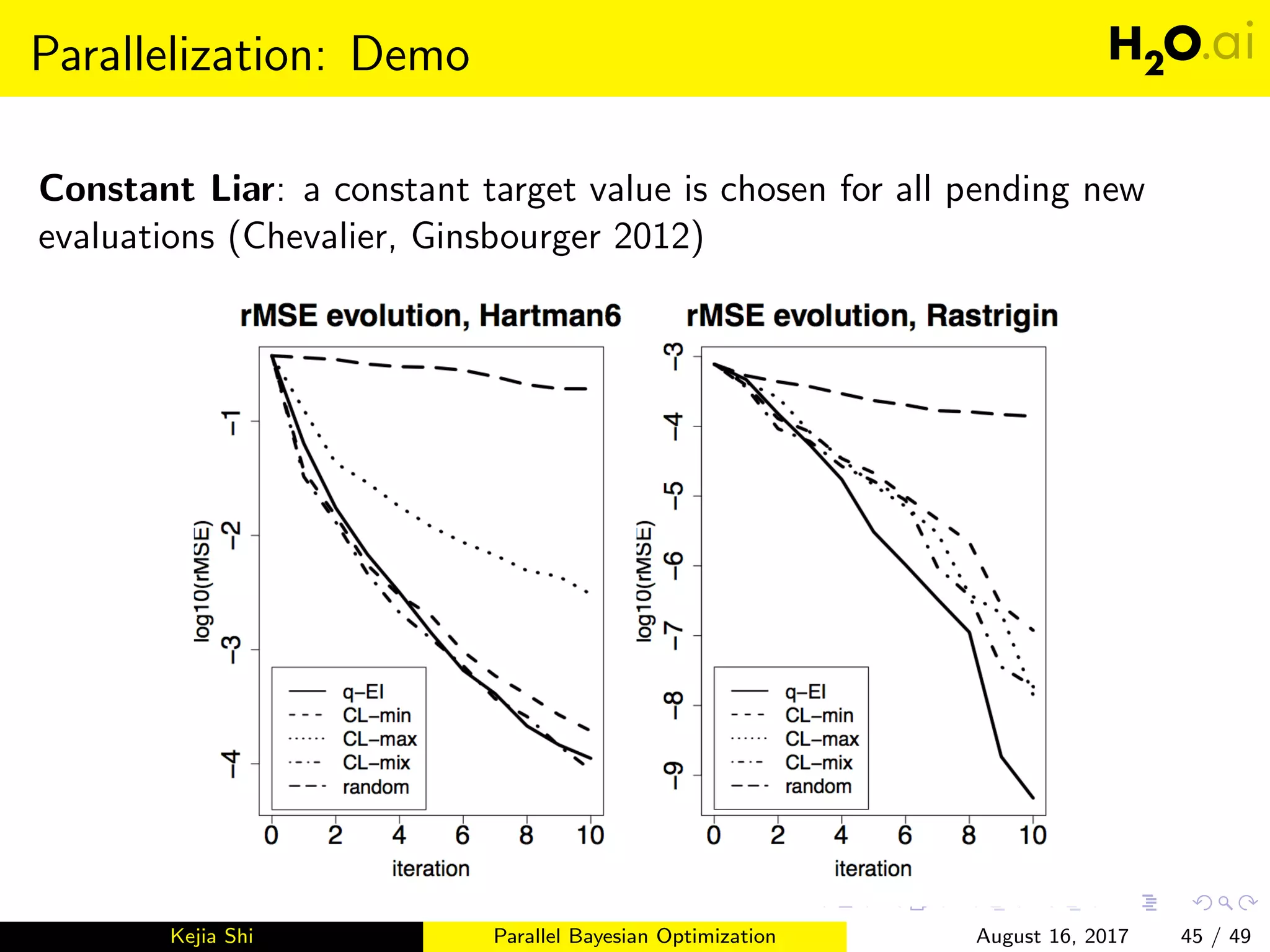





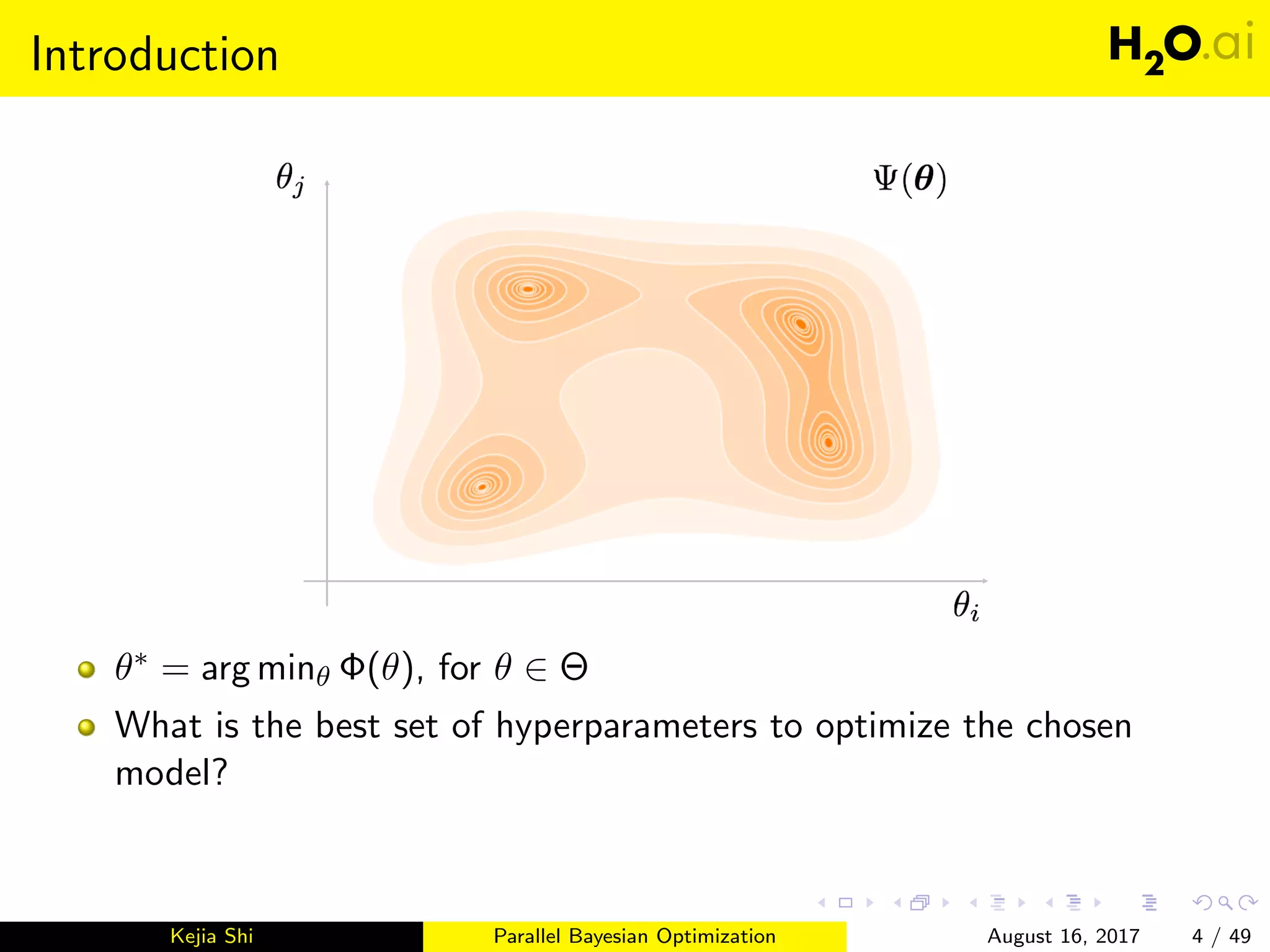
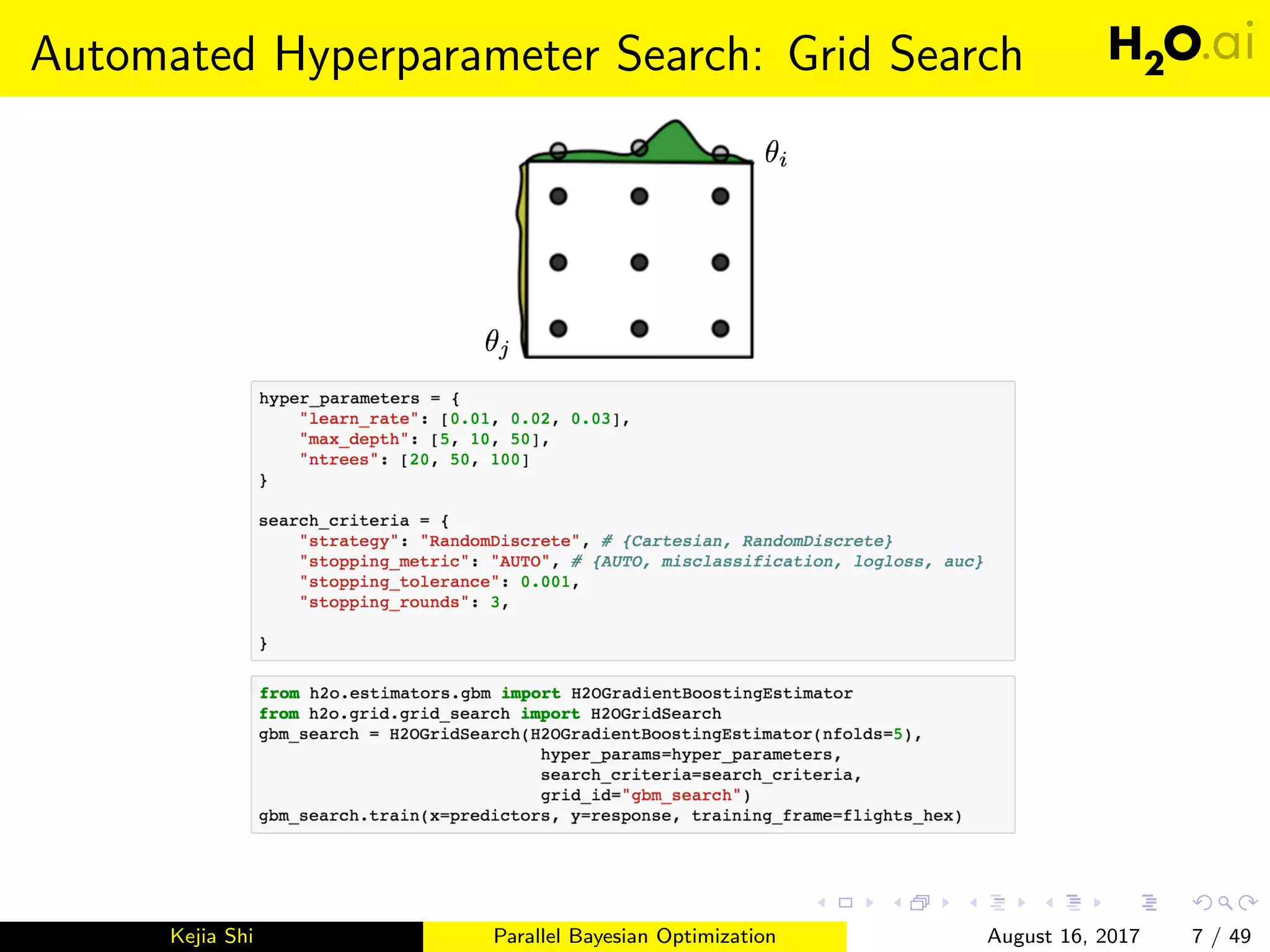
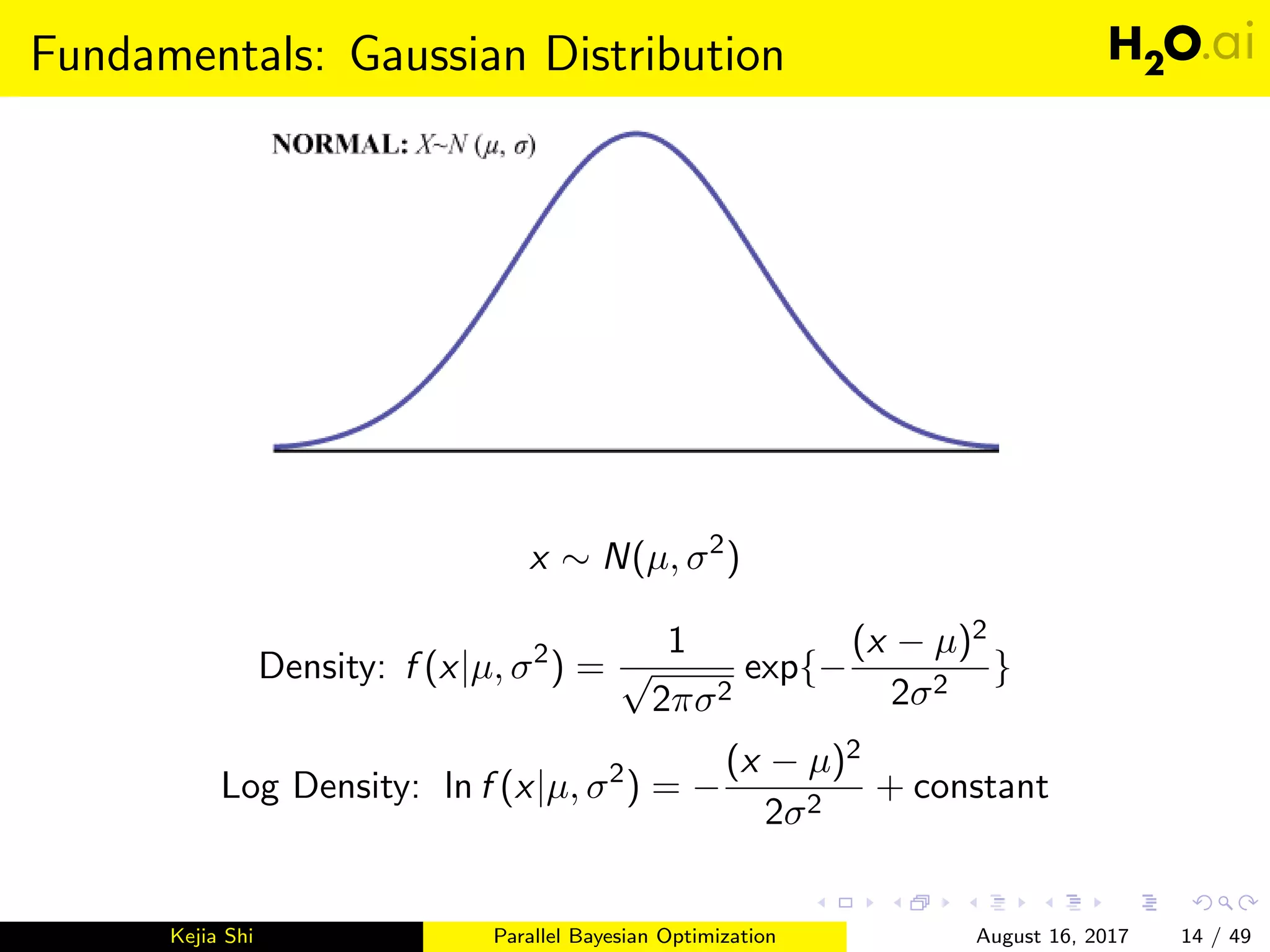
This document introduces parallel Bayesian optimization for machine learning. It first provides an overview and introduction, then discusses the fundamentals of Bayesian optimization including Gaussian processes and acquisition functions. It describes how Bayesian optimization can be used for automated hyperparameter tuning. Finally, it explains how parallel Bayesian optimization works by running multiple Bayesian optimization processes simultaneously to evaluate hyperparameters in parallel.























































































