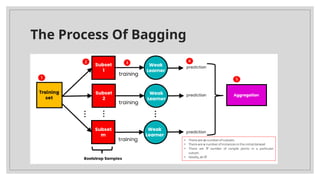
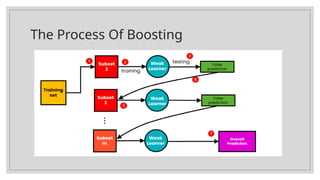
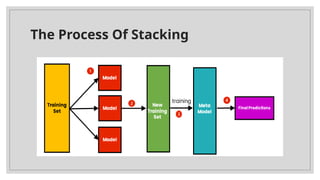
The document explains ensemble learning and its main techniques: bagging, boosting, and stacking. Bagging improves model accuracy by training multiple models independently on bootstrapped subsets of data, while boosting focuses on correcting previous errors through sequential training of weak models. Stacking combines predictions from multiple models using a meta-model for enhanced performance, and the document discusses the differences and applications of each technique in machine learning.