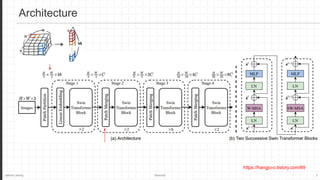
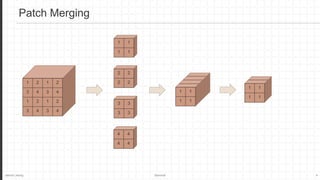
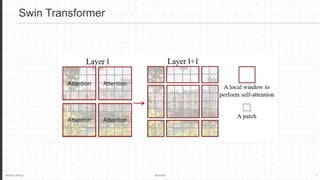
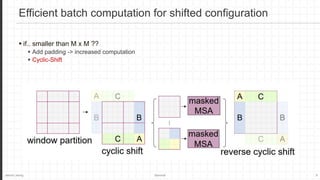
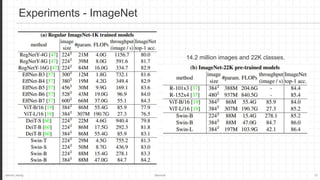
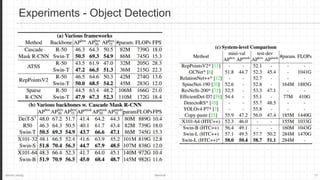
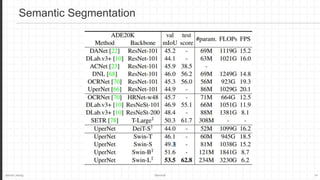
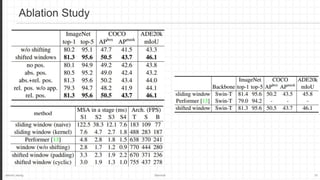
The document discusses the Swin Transformer, a general-purpose backbone for computer vision. It uses a hierarchical Transformer architecture with shifted windows to efficiently compute self-attention. Key aspects include dividing the image into non-overlapping windows at each level, and using shifted windows in successive blocks to allow for cross-window connections while maintaining linear computational complexity. Experimental results show Swin Transformer achieves state-of-the-art performance for image classification, object detection and semantic segmentation tasks.















![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)


























































