Downloaded 11 times




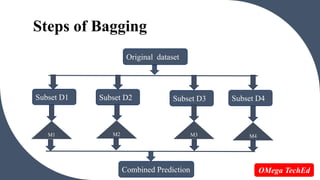


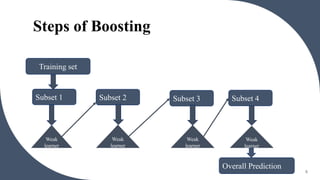


Ensemble learning uses multiple machine learning models to obtain better predictive performance than could be obtained from any of the constituent models alone. It involves techniques such as bagging and boosting. Bagging generates additional training data sets by sampling the original data with replacement and trains an ensemble of models on these data sets. Boosting trains models sequentially such that subsequent models focus on instances incorrectly predicted by preceding models, reducing errors. Both aim to reduce variance and improve predictive accuracy through model averaging or voting.























































































